scrapy 爬虫基础
Scrapy是Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
安装Scrapy的过程比较复杂而且容易出错,贴出一个参考链接:windows下scrapy安装步骤。
安装完成后,在自定义目录下输入
scrapy startproject Project_Name //创建新爬虫项目
scrapy genspider -t crawl Crawl_Name Url_addr//创建爬虫,模板,爬虫名和待爬网址
Scrapy内置的爬虫模板可使用:scrapy genspider -l 来查询,查询结果如下:包括basic crawl csvfeed xmlfeed四种类型。
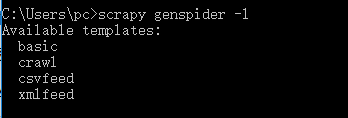
使用以上命令后,便会在目录中自动生成爬虫项目,包含的内容如下图:
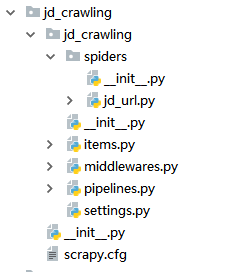
分别代表的意义为:
scrapy.cfg:项目的配置文件
jd_crawling/:项目的Python模块,将会从这里引用代码
jd_crawling/items.py:项目的items文件
jd_crawling/pipelines.py:项目的pipelines文件 (pipeline意为管道,即将数据传递过来进行储存或处理)
jd_crawling/settings.py:项目的设置文件
jd_crawling/spiders/:存储爬虫的目录
进入目录中,在item中定义待爬的关键字(target),目的是封装进Item中,做为整个项目的一个对象进行引用和处理
class JdCrawlingItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
goods_name = scrapy.Field()#定义商品名称
goods_link = scrapy.Field()#定义商品链接
items创建完成后进入spider创建爬虫规则:先爬,再取。可以看到在子佛那个创建的项目中已经为我们自动创建了一些内容:
class JdUrlSpider(CrawlSpider):
name = 'jd_url' #爬虫的识别名称,必须唯一
allowed_domains = ['jd.com'] # 允许执行的url范围
start_urls = ['http://www.jd.com/'] # 爬取的URL列表
创建匹配规则:
def parse_item(self, response): #解析的方法,调用的时候传入从每一个URL传回的Response对象作为唯一参数,负责解析并匹配抓取的数据(解析为item)
item = JdCrawlingItem() #此处便引用了之前定义的item
item['goods_name'] = response.xpath("//a[@class='pic']/@title").extract()
item['goods_link'] = response.xpath("//a[@class='pic']/@href").extract()
print(item['goods_name'])
xpath的使用方法详见:关于scrapy网络爬虫的xpath书写经验总结
最后执行:scrapy crawl jd_url 则可以开始我们的爬虫了。
这是最基本的爬虫,之后还会涉及到:1通过pipeline 写进数据库(pymsql)2突破反爬虫限制3爬虫数据分析和处理等内容。会在接下来的内容中完善
scrapy 爬虫基础的更多相关文章
- 小白学 Python 爬虫(33):爬虫框架 Scrapy 入门基础(一)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(34):爬虫框架 Scrapy 入门基础(二)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(35):爬虫框架 Scrapy 入门基础(三) Selector 选择器
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(36):爬虫框架 Scrapy 入门基础(四) Downloader Middleware
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(37):爬虫框架 Scrapy 入门基础(五) Spider Middleware
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(38):爬虫框架 Scrapy 入门基础(六) Item Pipeline
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(40):爬虫框架 Scrapy 入门基础(七)对接 Selenium 实战
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(41):爬虫框架 Scrapy 入门基础(八)对接 Splash 实战
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 爬虫入门之Scrapy 框架基础功能(九)
Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非 ...
随机推荐
- Linux 每日命令行
uptime 用于查看系统的负载信息. 它依次显示 当前系统时间.系统已运行时间.启用终端数量及平均负载值等信息.平均负载指的是系统在最近1分钟.5分钟.15分钟内的压力情况:负载值越低越好,尽量不要 ...
- HTTP协议学习笔记
一.什么是HTTP协议 HTTP协议是指计算机通信网络中两台计算机之间进行通信所必须共同遵守的规定或规则,超文本传输协议(HTTP)是一种通信协议,它允许将超文本标记语言(HTML)文档从Web服务器 ...
- 基于JDK1.8的ArrayList剖析
前言 本文是基于JDK1.8的ArrayList进行分析的.本文大概从以下几个方面来分析ArrayList这个数据结构 构造方法 add方法 扩容 remove方法 (一)构造方法 /** * Con ...
- 标准Http协议的六种请求方法详解
标准Http协议支持六种请求方法,即: 1.GET 2.POST 3.PUT 4.Delete 5.HEAD 6.Options 但其实我们大部分情况下只用到了GET和POST.如果想设计一个符合RE ...
- JS标签的各种事件的举例
1.鼠标单击事件( onclick ) <!DOCTYPE HTML> <html> <head> <meta http-equiv="Conten ...
- 初学node.js有感一
Node.js感悟 一.前言 很久以前就对node.js十分的好奇和感兴趣,因为种种原因没能去深入的认识了解和学习掌握这门技术,最近正好要做一些项目,其中就用到了node.js中的一些东西,所以借着使 ...
- NumPy学习_00 ndarray的创建
1.使用array()函数创建数组 参数可以为:单层或嵌套列表:嵌套元组或元组列表:元组或列表组成的列表 # 导入numpy库 import numpy as np # 由单层列表创建 a = np. ...
- nyoj135 取石子(二) Nimm博弈
思路:计算每堆石子的SG值,然后异或得到总的SG值,如果SG=0则输,否则赢. 每堆石子的SG值等于m%(n+1),可以自己推算一下. AC代码 #include <cstdio> #in ...
- 项目实战14—ELK 企业内部搜索引擎
一.els.elk 的介绍 1.els,elk els:ElasticSearch,Logstash,Kibana,Beats elk:ElasticSearch,Logstash,Kibana ① ...
- flask中jinjia2模板引擎详解3
接上文 模板继承 Jinji2中的模板继承是jinjia2比较强大的功能之一. 模板继承可以定义一个父级公共的模板,把同一类的模板框架定义出来共享. 这样做一方面可以提取共享代码,减少代码冗余和重复的 ...