C#实现有向无环图(DAG)拓扑排序
对一个有向无环图(Directed Acyclic Graph简称DAG)G进行拓扑排序,是将G中所有顶点排成一个线性序列,使得图中任意一对顶点u和v,若边(u,v)∈E(G),则u在线性序列中出现在v之前。通常,这样的线性序列称为满足拓扑次序(Topological Order)的序列,简称拓扑序列。简单的说,由某个集合上的一个偏序得到该集合上的一个全序,这个操作称之为拓扑排序.
线性结构概念
总的来说,“线性结构”是一个有序数据元素的集合 线性结构满足以下特点:
- 集合中必存在唯一“第一个元素”;
- 集合中必存在唯一“最后一个元素”;
- 除了最后一个元素,所有元素均有唯一“后继结点”;
- 除了第一个元素,所有元素均有唯一“前趋结点”
和我们abp Module很像,第一个加载模块永远是其ABP核心模块,最后一个模块永远是我们的启动模块
举例
1.大学课程排序
大学课程的学习是有先后顺序的,C语言是基础,数据结构依赖于C语言,其它课程也有类似依赖关系。这样的一个课程安排是怎么实现的呢?
2.VS项目编译顺序
假设VS中有三个项目A,B,C,它们的关系如下。VS编译器是如何判断三个项目的编译顺序的呢?
A->B->C A引用B B引用C
A->B->C->A 提示循环引用
ABP的Module
ABP中的模块也是如此,不可循环引用相互依赖A->B B->A X
前面说到ABP中的第一个模块和最后一个模块是确定的。
呢么中间的是怎么排序的呢。其实用的是拓扑算法
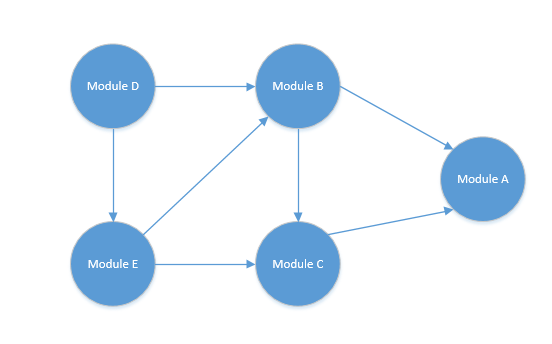
从图中可以得知:
1.A模块是最核心的,不依赖于其他任何模块
2.D依赖E和B,E依赖B和C,B依赖C和A,C依赖A
那么根据拓扑排序,应该如何排序呢?
1.从图中找一个没有前驱指向它的顶点
2.删除该顶点.以及该顶点的前驱
3.重复步骤 1 and 2 ,直到图中顶点为空 或者 找不到步骤1中这样的顶点 为止.
排序如下:
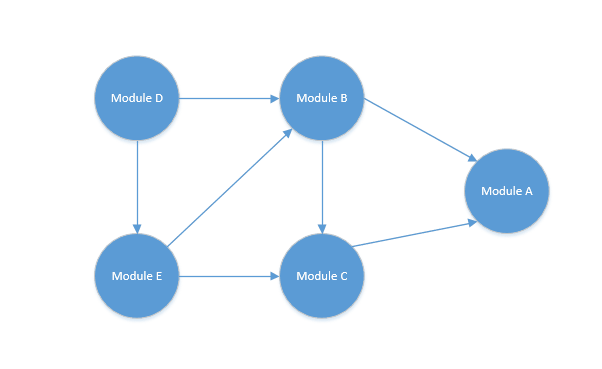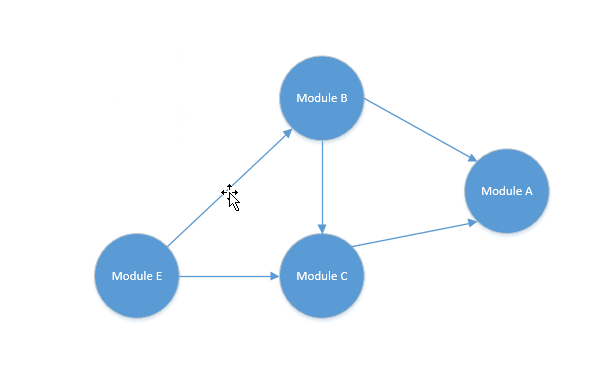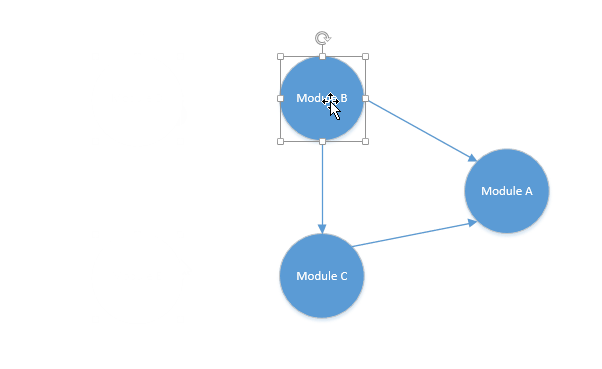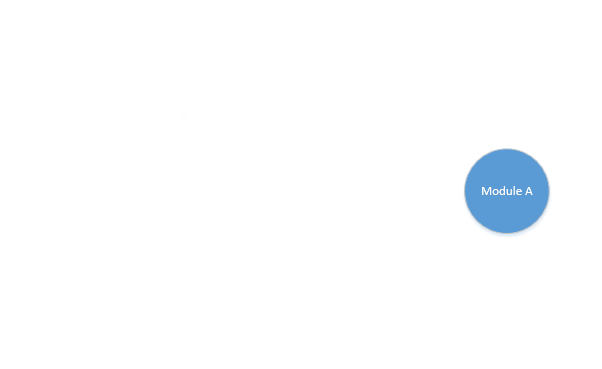
结果就是D->E->B->C->A 排完之后正好对应D依赖E和B,E依赖B和C,B依赖C和A,C依赖A
这个顺序在ABP的模块这看来是行不通的,需要在反转一次,最先加载A,才行。
C#实现深度优先搜索
有这样一个DAG图

如果对它进行排序的话,其实过程是这样的.
图中,顶点A是没有指向它的前驱的,所以从它开始访问
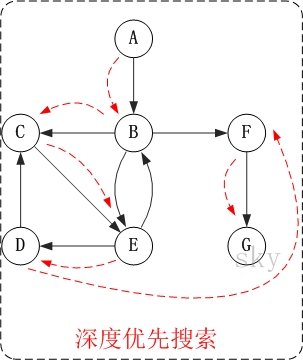
1.访问 A
2.访问 B
3.访问 C
在访问了 B 后应该是访问 B 的另外一个顶点,这里可以是随机的也可以是有序的,具体取决于你存储的序列顺序,这里先访问 C 。
4.访问 E
5.访问 D
这里访问 D 是因为 B 已经被访问过了,所以访问顶点 D 。
6.访问 F
因为顶点 C 已经被访问过,所以应该回溯访问顶点 B 的另一个有向边指向的顶点 F 。
7.访问 G
那么代码应该如何写呢?
source:需要排序的集合
getDepends:一个func委托,用于获取当前模块依赖的其他模块
方法内部维护了一个字典对象Visited 用于存储已经访问过的模块,key表示模块,value是一个bool,true时表示正在处理,false表示以及处理完成,
处理完成的模块会加入到sorted集合中
static List<T> MySort<T>(IEnumerable<T> source, Func<T, IEnumerable<T>> getDepends)
{
// 访问过的路径
Dictionary<T, bool> visited = new Dictionary<T, bool>();
// 已经排过序的
List<T> sorted = new List<T>();
foreach (var item in source)
{
Visit<T>(item, getDepends, visited, sorted);
}
return sorted;
}
static void Visit<T>(T item, Func<T, IEnumerable<T>> getDepends, Dictionary<T, bool> visited, List<T> sorted)
{
//已经访问过了
if (visited.ContainsKey(item))
{
bool isVisit = visited[item];
if (isVisit == true)
{
throw new Exception("循环引用");
}
}
//未访问
else
{
visited.Add(item, true);//true :正在访问 false:访问完成
//获取所有依赖
var depends = getDepends(item);
foreach (var depend in depends)
{
Visit(depend, getDepends, visited, sorted);
}
//访问完成
visited[item] = false;
sorted.Add(item);
}
}
C#实现有向无环图(DAG)拓扑排序的更多相关文章
- 算法87-----DAG有向无环图的拓扑排序
一.题目:课程排表---210 课程表上有一些课,是必须有修学分的先后顺序的,必须要求在上完某些课的情况下才能上下一门.问是否有方案修完所有的课程?如果有的话请返回其中一个符合要求的路径,否则返回[] ...
- CSU 1804: 有向无环图(拓扑排序)
http://acm.csu.edu.cn/csuoj/problemset/problem?pid=1804 题意:…… 思路:对于某条路径,在遍历到某个点的时候,之前遍历过的点都可以到达它,因此在 ...
- 大数据工作流任务调度--有向无环图(DAG)之拓扑排序
点击上方蓝字关注DolphinScheduler(海豚调度) |作者:代立冬 |编辑:闫利帅 回顾基础知识: 图的遍历 图的遍历是指从图中的某一个顶点出发,按照某种搜索方法沿着图中的边对图中的所有顶点 ...
- [笔记] 有向无环图 DAG
最小链覆盖 (最长反链) 最小链覆盖 \(=n-\) 最大匹配. 考虑首先每个点自成一条链,此时恰好有 \(n\) 条链,最终答案一定是合并(首尾相接)若干条链形成的. 将两点匹配的含义其实就是将链合 ...
- 【模板整合计划】图论—有向无环图 (DAG) 与树
[模板整合计划]图论-有向无环图 (DAG) 与树 一:[拓扑排序] 最大食物链计数 \(\text{[P4017]}\) #include<cstring> #include<cs ...
- 判断有向无环图(DAG)
1.拓扑排序 bfs 所有入度为0的先入选. 2.tarjan 1个点1个集合 3.暴力 一个点不能重新到达自己
- pagerank算法在数学模型中的运用(有向无环图中节点排序)
一.模型介绍 pagerank算法主要是根据网页中被链接数用来给网页进行重要性排名. 1.1模型解释 模型核心: a. 如果多个网页指向某个网页A,则网页A的排名较高. b. 如果排名高A的网页指向某 ...
- 题目1448:Legal or Not(有向无环图判断——拓扑排序问题)
题目链接:http://ac.jobdu.com/problem.php?pid=1448 详解链接:https://github.com/zpfbuaa/JobduInCPlusPlus 参考代码: ...
- 图->有向无环图->拓扑排序
文字描述 关于有向无环图的基础定义: 一个无环的有向图称为有向无环图,简称DAG图(directed acycline graph).DAG图是一类较有向树更一般的特殊有向图. 举个例子说明有向无环图 ...
随机推荐
- python读取.mat文件的数据
首先导入scipy的包 from scipy.io import loadmat 然后读取 m = loadmat("F:/__identity/activity/论文/data/D001. ...
- QT Creator 代码自动补全
QT Creator 代码自动补全 用QT Creater编程,如果没有自动补全是很痛苦的事情,于是便查阅了QT的文档,发现CTRL+SPACE是自 动补全的快捷键;但是在 Creater里使用居然没 ...
- ASP.NET上传文件,已经上传的大小保存在session中,在另一个页面中读取session的值不行
想自己做个ASP.NET上传文件时显示进度条的, 按照自己的想法,其实也就是显示每次已经上传的字节,从网上找到一个方法是能够把文件变成流以后再慢慢写入的,我在那个循环写入的时候每循环一次都把已经上传的 ...
- unity监测按下键的键值并输出+unity键值
using System; using System.Collections; using System.Collections.Generic; using UnityEngine; using U ...
- 2017-03-05 CentOS中配置守护服务(Supervisor)监听dotnet core web程序的运行
我们继续解决上篇博客的问题,我这个人有个毛病,不喜欢遗留什么问题,也不喜欢问题说不明白,具体要怎么解决一定要详尽,因为经常自己遇到问题的时候,去翻别人的博客,就会遇到这样的问题,很苦恼,又说废话了. ...
- 迭代式返回 IEnumerable<T>
private IEnumerable<PoliceForceViewModel> CreateResultList(IEnumerable<GPSData> gpsData) ...
- Windows下载安装虚拟机和CentOS7
1,想要在Windows系统中安装linux系统,首先需要安装一个虚拟机VMware VMware 12下载地址:https://my.vmware.com/cn/web/vmware/info/sl ...
- [转载]java读写word文档,完美解决方案
做项目的过程中,经常需要把数据里里的数据读出来,经过加工,以word格式输出. 在网上找了很多解决方案都不太理想,偶尔发现了PageOffice,一个国产的Office插件,开发调用非常简单!比网上介 ...
- 网络编程基础--IO模型
一 IO模型介绍: 背景 是 Linux环境下 的 network IO , Third Edition: The Sockets Networking ”,.2节“I/O Models ”,Stev ...
- nginx location配置与rewrite配置
注:原文出处 www.linuxidc.com/Linux/2015-06/119398.htm 1. location正则写法 一个示例: location =/{ # 精确匹配 / ,主机名后面不 ...