C#实现有向无环图(DAG)拓扑排序
对一个有向无环图(Directed Acyclic Graph简称DAG)G进行拓扑排序,是将G中所有顶点排成一个线性序列,使得图中任意一对顶点u和v,若边(u,v)∈E(G),则u在线性序列中出现在v之前。通常,这样的线性序列称为满足拓扑次序(Topological Order)的序列,简称拓扑序列。简单的说,由某个集合上的一个偏序得到该集合上的一个全序,这个操作称之为拓扑排序.
线性结构概念
总的来说,“线性结构”是一个有序数据元素的集合 线性结构满足以下特点:
- 集合中必存在唯一“第一个元素”;
- 集合中必存在唯一“最后一个元素”;
- 除了最后一个元素,所有元素均有唯一“后继结点”;
- 除了第一个元素,所有元素均有唯一“前趋结点”
和我们abp Module很像,第一个加载模块永远是其ABP核心模块,最后一个模块永远是我们的启动模块
举例
1.大学课程排序
大学课程的学习是有先后顺序的,C语言是基础,数据结构依赖于C语言,其它课程也有类似依赖关系。这样的一个课程安排是怎么实现的呢?
2.VS项目编译顺序
假设VS中有三个项目A,B,C,它们的关系如下。VS编译器是如何判断三个项目的编译顺序的呢?
A->B->C A引用B B引用C
A->B->C->A 提示循环引用
ABP的Module
ABP中的模块也是如此,不可循环引用相互依赖A->B B->A X
前面说到ABP中的第一个模块和最后一个模块是确定的。
呢么中间的是怎么排序的呢。其实用的是拓扑算法
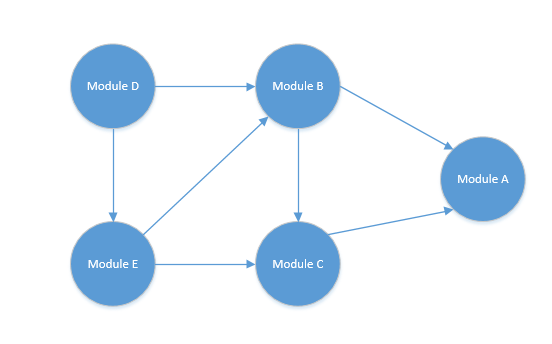
从图中可以得知:
1.A模块是最核心的,不依赖于其他任何模块
2.D依赖E和B,E依赖B和C,B依赖C和A,C依赖A
那么根据拓扑排序,应该如何排序呢?
1.从图中找一个没有前驱指向它的顶点
2.删除该顶点.以及该顶点的前驱
3.重复步骤 1 and 2 ,直到图中顶点为空 或者 找不到步骤1中这样的顶点 为止.
排序如下:
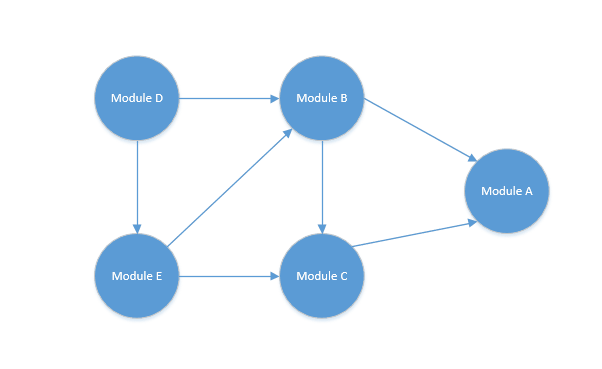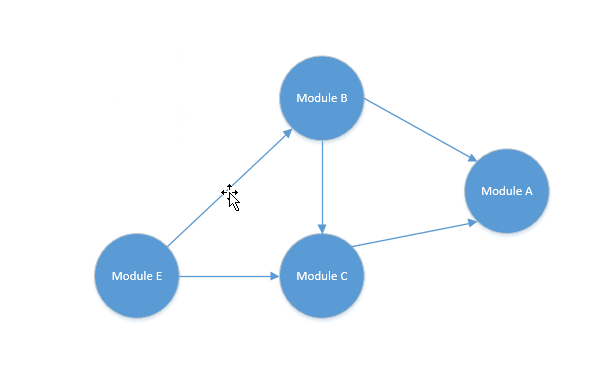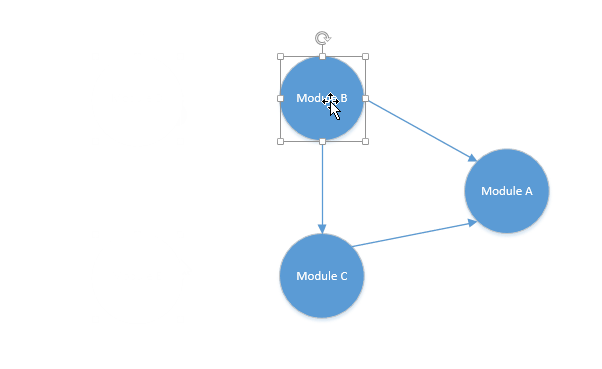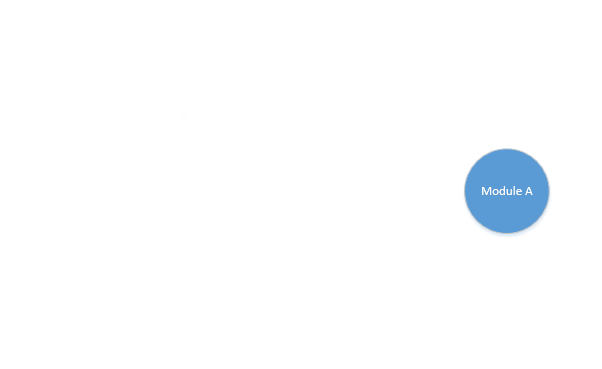
结果就是D->E->B->C->A 排完之后正好对应D依赖E和B,E依赖B和C,B依赖C和A,C依赖A
这个顺序在ABP的模块这看来是行不通的,需要在反转一次,最先加载A,才行。
C#实现深度优先搜索
有这样一个DAG图

如果对它进行排序的话,其实过程是这样的.
图中,顶点A是没有指向它的前驱的,所以从它开始访问
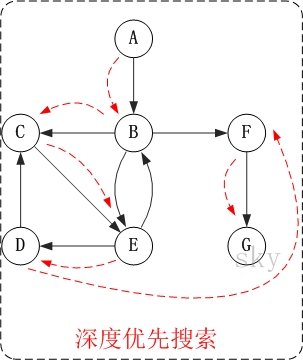
1.访问 A
2.访问 B
3.访问 C
在访问了 B 后应该是访问 B 的另外一个顶点,这里可以是随机的也可以是有序的,具体取决于你存储的序列顺序,这里先访问 C 。
4.访问 E
5.访问 D
这里访问 D 是因为 B 已经被访问过了,所以访问顶点 D 。
6.访问 F
因为顶点 C 已经被访问过,所以应该回溯访问顶点 B 的另一个有向边指向的顶点 F 。
7.访问 G
那么代码应该如何写呢?
source:需要排序的集合
getDepends:一个func委托,用于获取当前模块依赖的其他模块
方法内部维护了一个字典对象Visited 用于存储已经访问过的模块,key表示模块,value是一个bool,true时表示正在处理,false表示以及处理完成,
处理完成的模块会加入到sorted集合中
static List<T> MySort<T>(IEnumerable<T> source, Func<T, IEnumerable<T>> getDepends)
{
// 访问过的路径
Dictionary<T, bool> visited = new Dictionary<T, bool>();
// 已经排过序的
List<T> sorted = new List<T>();
foreach (var item in source)
{
Visit<T>(item, getDepends, visited, sorted);
}
return sorted;
}
static void Visit<T>(T item, Func<T, IEnumerable<T>> getDepends, Dictionary<T, bool> visited, List<T> sorted)
{
//已经访问过了
if (visited.ContainsKey(item))
{
bool isVisit = visited[item];
if (isVisit == true)
{
throw new Exception("循环引用");
}
}
//未访问
else
{
visited.Add(item, true);//true :正在访问 false:访问完成
//获取所有依赖
var depends = getDepends(item);
foreach (var depend in depends)
{
Visit(depend, getDepends, visited, sorted);
}
//访问完成
visited[item] = false;
sorted.Add(item);
}
}
C#实现有向无环图(DAG)拓扑排序的更多相关文章
- 算法87-----DAG有向无环图的拓扑排序
一.题目:课程排表---210 课程表上有一些课,是必须有修学分的先后顺序的,必须要求在上完某些课的情况下才能上下一门.问是否有方案修完所有的课程?如果有的话请返回其中一个符合要求的路径,否则返回[] ...
- CSU 1804: 有向无环图(拓扑排序)
http://acm.csu.edu.cn/csuoj/problemset/problem?pid=1804 题意:…… 思路:对于某条路径,在遍历到某个点的时候,之前遍历过的点都可以到达它,因此在 ...
- 大数据工作流任务调度--有向无环图(DAG)之拓扑排序
点击上方蓝字关注DolphinScheduler(海豚调度) |作者:代立冬 |编辑:闫利帅 回顾基础知识: 图的遍历 图的遍历是指从图中的某一个顶点出发,按照某种搜索方法沿着图中的边对图中的所有顶点 ...
- [笔记] 有向无环图 DAG
最小链覆盖 (最长反链) 最小链覆盖 \(=n-\) 最大匹配. 考虑首先每个点自成一条链,此时恰好有 \(n\) 条链,最终答案一定是合并(首尾相接)若干条链形成的. 将两点匹配的含义其实就是将链合 ...
- 【模板整合计划】图论—有向无环图 (DAG) 与树
[模板整合计划]图论-有向无环图 (DAG) 与树 一:[拓扑排序] 最大食物链计数 \(\text{[P4017]}\) #include<cstring> #include<cs ...
- 判断有向无环图(DAG)
1.拓扑排序 bfs 所有入度为0的先入选. 2.tarjan 1个点1个集合 3.暴力 一个点不能重新到达自己
- pagerank算法在数学模型中的运用(有向无环图中节点排序)
一.模型介绍 pagerank算法主要是根据网页中被链接数用来给网页进行重要性排名. 1.1模型解释 模型核心: a. 如果多个网页指向某个网页A,则网页A的排名较高. b. 如果排名高A的网页指向某 ...
- 题目1448:Legal or Not(有向无环图判断——拓扑排序问题)
题目链接:http://ac.jobdu.com/problem.php?pid=1448 详解链接:https://github.com/zpfbuaa/JobduInCPlusPlus 参考代码: ...
- 图->有向无环图->拓扑排序
文字描述 关于有向无环图的基础定义: 一个无环的有向图称为有向无环图,简称DAG图(directed acycline graph).DAG图是一类较有向树更一般的特殊有向图. 举个例子说明有向无环图 ...
随机推荐
- review30
数据流 DateInputStream和DataOutputStream类创建的对象称为数据输入流和数据输出流.这两个流是很有用的流,它们允许程序按着机器无关的风格读取Java原始数据.也就是说,当读 ...
- nginx路由重定向
location / { if ($http_host !~ "m.xxx.cn"){ rewrite ^/web/(.*)/bdu(\d?)\.htm(.*)$ /rewrite ...
- spring boot: 条件注解@Condition
@Conditional根据满足某一个特定的条件创建一个特定的Bean(基于条件的Bean的创建,即使用@Conditional注解). 比方说,当一个jar包在一个类的路径下的时候,自动配置一个或多 ...
- 安装Xcode 7 beta后Xcode 6崩溃的问题
最新解决方案:把OSX El Capitan升级到Beta 7 (15A263e),Xcode6可使用! 解决方案:http://stackoverflow.com/questions/318035 ...
- uva 1025 A Spy int the Metro
https://vjudge.net/problem/UVA-1025 看见spy忍俊不禁的想起省赛时不知道spy啥意思 ( >_< f[i][j]表示i时刻处于j站所需的最少等待时间,有 ...
- 解析Ceph: 数据的端到端正确性和 Scrub 机制
转自:https://www.ustack.com/blog/ceph-internal-scrub/ Ceph 的主要一大特点是强一致性,这里主要指端到端的一致性.众所周知,传统存储路径上从应用层到 ...
- mysql分表和分区实际应用简介
一,什么是mysql分表,分区 什么是分表,从表面意思上看呢,就是把一张表分成N多个小表,具体请看mysql分表的3种方法 什么是分区,分区呢就是把一张表的数据分成N多个区块,这些区块可以在同一个磁盘 ...
- HTTP协议状态代码和错误状态含义的解释
面试互联网公司经常被问的就是HTTP协议的知识,甚至比TCP/IP问的还多,其中HTTP代码的知识也是开发过程中经常会接触的,今天学习所有 HTTP 状态代码及其定义. 代码 指示 2xx ...
- CODEVS 1174 靶形数独
题目描述 Description 小城和小华都是热爱数学的好学生,最近,他们不约而同地 迷上了数独游戏,好胜的他们想用数独来一比高低.但普通 的数独对他们来说都过于简单了,于是他们向Z 博士请教,Z ...
- shell 去重
group=`cat config.properties | grep -v "^$" | grep -v "^# ...