python爬虫框架(3)--Scrapy框架安装配置
1.安装python并将scripts配置进环境变量中
2.安装pywin32
在windows下,必须安装pywin32,安装地址:http://sourceforge.net/projects/pywin32/
下载对应版本的pywin32,直接双击安装即可,安装完毕之后验证:

在python命令行下输入
import win32com
如果没有提示错误,则证明安装成功
3.安装pip
pip是用来安装其他必要包的工具,首先下载 get-pip.py
python get-pip.py
执行命令后便会安装好pip,并且同时,它帮你安装了setuptools
安装完了之后在命令行中执行
pip --version
4.安装pyOPENSSL
在Windows下,是没有预装pyOPENSSL的,而在Linux下是已经安装好的。
安装地址:https://launchpad.net/pyopenssl

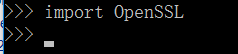
在python命令行下输入
import OpenSSL
如果没有提示错误,则证明安装成功
5.安装 lxml
lxml是一种使用 Python 编写的库,可以迅速、灵活地处理 XML
直接执行如下命令
pip install lxml
6.安装Scrapy
执行如下命令
pip install Scrapy
pip 会另外下载其他依赖的包,这些就不要我们手动安装啦,等待一会,大功告成!
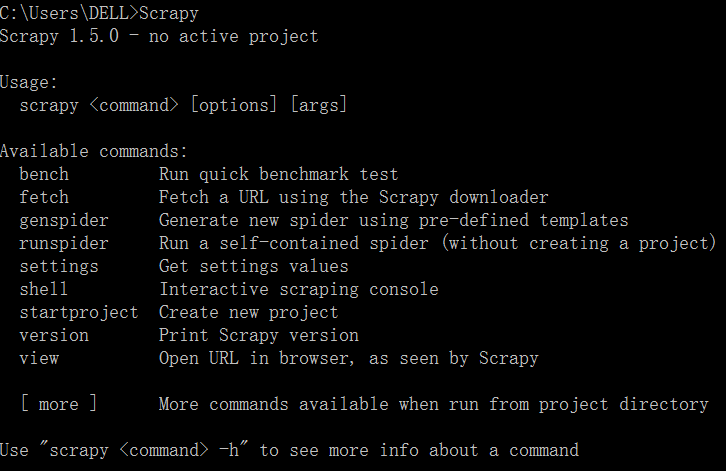
7.验证安装
输入 Scrapy
如果提示如下命令,就证明安装成功啦,如果失败了,请检查上述步骤有何疏漏。
可能会遇到AttributeError: 'module' object has no attribute 'OP_NO_TLSv1_1'的问题,原因是使用pip install Scrapy自动安装了较高版本的Twisted
解决办法:安装低版本的twisted
pip install twisted==13.1.0
python爬虫框架(3)--Scrapy框架安装配置的更多相关文章
- Python爬虫进阶之Scrapy框架安装配置
Python爬虫进阶之Scrapy框架安装配置 初级的爬虫我们利用urllib和urllib2库以及正则表达式就可以完成了,不过还有更加强大的工具,爬虫框架Scrapy,这安装过程也是煞费苦心哪,在此 ...
- python爬虫入门(六) Scrapy框架之原理介绍
Scrapy框架 Scrapy简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬 ...
- 零基础写python爬虫之使用Scrapy框架编写爬虫
网络爬虫,是在网上进行数据抓取的程序,使用它能够抓取特定网页的HTML数据.虽然我们利用一些库开发一个爬虫程序,但是使用框架可以大大提高效率,缩短开发时间.Scrapy是一个使用Python编写的,轻 ...
- PYTHON 爬虫笔记十一:Scrapy框架的基本使用
Scrapy框架详解及其基本使用 scrapy框架原理 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了 ...
- python爬虫学习之Scrapy框架的工作原理
一.Scrapy简介 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 其最初是为了 页面抓取 (更确切来说, 网 ...
- python 爬虫相关含Scrapy框架
1.从酷狗网站爬取 新歌首发的新歌名字.播放时长.链接等 from bs4 import BeautifulSoup as BS import requests import re import js ...
- 芝麻HTTP:Python爬虫进阶之Scrapy框架安装配置
初级的爬虫我们利用urllib和urllib2库以及正则表达式就可以完成了,不过还有更加强大的工具,爬虫框架Scrapy,这安装过程也是煞费苦心哪,在此整理如下. Windows 平台: 我的系统是 ...
- 【Python爬虫实战】Scrapy框架的安装 搬运工亲测有效
windows下亲测有效 http://blog.csdn.net/liuweiyuxiang/article/details/68929999这个我们只是正确操作步骤详解的搬运工
- Python爬虫知识点四--scrapy框架
一.scrapy结构数据 解释: 1.名词解析: o 引擎(Scrapy Engine)o 调度器(Scheduler)o 下载器(Downloader)o 蜘蛛(Spiders)o 项目管 ...
- 第三百三十一节,web爬虫讲解2—Scrapy框架爬虫—Scrapy安装—Scrapy指令
第三百三十一节,web爬虫讲解2—Scrapy框架爬虫—Scrapy安装—Scrapy指令 Scrapy框架安装 1.首先,终端执行命令升级pip: python -m pip install --u ...
随机推荐
- c# 查找一个字符串在另一个字符串出现的次数
方法一: string test = "FF FF FF FF 01 00 82 00 00 A2 00 00 FB 07 FF FF FF FF 01 00 82 00 00 A2 00 ...
- 在CentOS6.4中安装配置LAMP环境的详细步骤 - Leroy-LIZH
本文详细介绍了CentOS6.4系统中安装LAMP服务并对其进行配置的过程,即安装Apache+PHP+Mysql,参照了网上大神的设置,其他Linux发行系统可以参考~ 在本文中部分命令操作需要ro ...
- Java 反射机制应用实践
反射基础 p.s: 本文需要读者对反射机制的API有一定程度的了解,如果之前没有接触过的话,建议先看一下官方文档的Quick Start(https://docs.oracle.com/javase/ ...
- Android开发中java.lang.RuntimeException: Unable to start activity ComponentInfo{xxx}
Android开发中java.lang.RuntimeException: Unable to start activity ComponentInfo{xxx}: java.lang.NullPoi ...
- 使用NSUserDefaults保存自定义对象(转)
转自http://zani.iteye.com/blog/1431239 .h文件 #import <Foundation/Foundation.h> @interface MyObjec ...
- linux进程学习-创建新进程
init进程将系统启动后,init将成为此后所有进程的祖先,此后的进程都是直接或间接从init进程“复制”而来.完成该“复制”功能的函数有fork()和clone()等. 一个进程(父进程)调用for ...
- python lambda 用途
可以让一个带参数函数,传递并以无参调用 def test(a): print a a=test # #a() a=897987 fun=lambda : test(a) fun()
- Arc066_F Contest with Drinks Hard
传送门 题目大意 有一个长为$N$的序列$A$,你要构造一个长为$N$的$01$序列使得$01$序列全部由$1$组成的子串个数$-$两个序列的对应位置两两乘积之和最大,每次独立的询问给定$pos,x$ ...
- deque容器
一.deque容器基本概念 deque是“double-ended queue”的缩写,和vector一样,deque也支持随机存取.vector是单向开口的连续性空间,deque则是一种双向开口的连 ...
- 学习动态性能表(22)V$resource_limit
学习动态性能表 第20篇--V$resource_limit 2007.6.15 就一条SQL语句供你参考: select * from V$RESOURCE_LIMIT where resourc ...