Sequence Classification
Natural Language Processing with Python
Charpter 6.1
import nltk
from nltk.corpus import brown def pos_features(sentence,i,history):
features = {"suffix(1)":sentence[i][-1:],
"suffix(2)":sentence[i][-2:],
"suffix(3)":sentence[i][-3:]}
if i == 0:
features["prev-word"]="<STAR>"
features["prev_tag"] ="<STAR>"
else:
features["prev_word"]=sentence[i-1]
features["prev_tag"]=history[i-1]
return features class ConsecutivePosTagger(nltk.TaggerI):
def __init__(self,train_sents):
train_set=[]
for tagged_sent in train_sents:
history=[]
untagged_sent = nltk.tag.untag(tagged_sent)
for i,(word,tag) in enumerate(tagged_sent):
featureset=pos_features(untagged_sent,i,history)
train_set.append((featureset,tag))
history.append(tag)
self.classifier=nltk.NaiveBayesClassifier.train(train_set) def tag(self,sentence):
history=[]
for i,word in enumerate(sentence):
featureset=pos_features(sentence,i,history)
tag=self.classifier.classify(featureset)
history.append(tag)
return zip(sentence,history) def test_ConsecutivePosTagger():
tagged_sents=brown.tagged_sents(categories='news')
size = int(len(tagged_sents) * 0.1)
train_sents, test_sents = tagged_sents[size:], tagged_sents[:size]
tagger = ConsecutivePosTagger(train_sents) print tagger.evaluate(test_sents)
流程为:
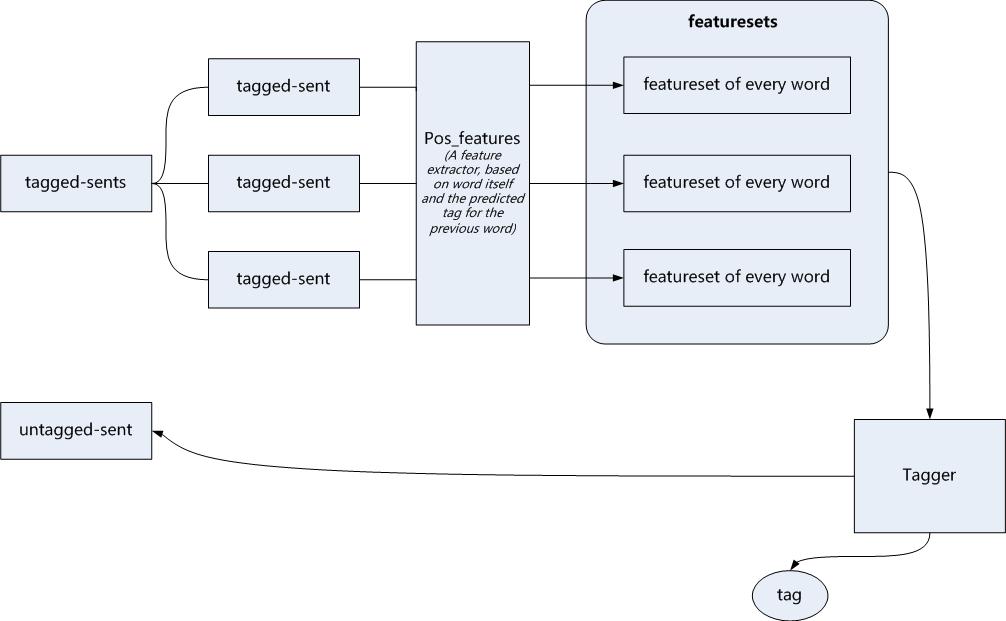
结果为:
0.796940194715
Sequence Classification的更多相关文章
- Kraken taxonomic sequence classification system
kraken:是一个将分类标签打到短DNAreads上的分类序列器.
- .NET平台开源项目速览(13)机器学习组件Accord.NET框架功能介绍
Accord.NET Framework是在AForge.NET项目的基础上封装和进一步开发而来.因为AForge.NET更注重与一些底层和广度,而Accord.NET Framework更注重与机器 ...
- RNN,写起来真的烦
曾经,为了处理一些序列相关的数据,我稍微了解了一点递归网络 (RNN) 的东西.由于当时只会 tensorflow,就从官网上找了一些 tensorflow 相关的 demo,中间陆陆续续折腾了两个多 ...
- 文本分类实战(十)—— BERT 预训练模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- Accord.NET Framework 介绍
阅读目录 1.基本功能与介绍 Accord.NET Framework是在AForge.NET项目的基础上封装和进一步开发而来.因为AForge.NET更注重与一些底层和广度,而Accord.NET ...
- [Tensorflow] RNN - 02. Movie Review Sentiment Prediction with LSTM
From: Predicting Movie Review Sentiment with TensorFlow and TensorBoard Ref: http://www.cnblogs.com/ ...
- 自然语言处理领域重要论文&资源全索引
自然语言处理(NLP)是人工智能研究中极具挑战的一个分支.随着深度学习等技术的引入,NLP领域正在以前所未有的速度向前发展.但对于初学者来说,这一领域目前有哪些研究和资源是必读的?最近,Kyubyon ...
- [转]NLP Tasks
Natural Language Processing Tasks and Selected References I've been working on several natural langu ...
- .NET数据挖掘与机器学习开源框架
1. 数据挖掘与机器学习开源框架 1.1 框架概述 1.1.1 AForge.NET AForge.NET是一个专门为开发者和研究者基于C#框架设计的,他包括计算机视觉与人工智能,图像处理,神经 ...
随机推荐
- php composer 安装
- 8.3 sikuli 集成进eclipse 报错:eclipse中运行提示 Win32Util.dll: Can't load 32-bit .dll on a AMD 64 bit platform
sikuli运行出现问题:Win32Util.dll: Can't load 32-bit .dll on a AMD 64 bit platform 在64位平台上无法加载32位的dll文件 解决办 ...
- ubuntu14下python环境的配置
1.安装build依赖包(一些包需要用pip编译) sudo apt-get install python-dev 2.安装pip包管理工具 sudo apt-get install python-p ...
- Python 3.5.1 Syntax & APIs(Continue Updating..
print(x, end=' ') instead of print(x) to escape the default line-changing-output. print(str.ljust(si ...
- cocos2d-x 3.10 显示Box2d 调试视图
1.将cocos2d-x-3.10\tests\cpp-tests\Classes\Box2DTestBed目录下的GLES-Render.h和GLES-Render.cpp拷贝到当前项目的Class ...
- Bootstrap学习 - 组件
下拉菜单 注意:需要先引入jQuery.js再引入bootstrap.js(依赖前者) <div class="dropdown pull-right"> //默认就是 ...
- HDU - 1865 1string(大数)
题目链接:http://acm.hust.edu.cn/vjudge/contest/121397#problem/F http://acm.hdu.edu.cn/showproblem.php?pi ...
- HDU 2671 Can't be easier
简单的几何题目 点(a,b)关于直线Ax+By+C=1对称点的公式 #include<cstdio> #include<cstring> #include<cmath&g ...
- iis配置,客户端可以下载apk,或者播放视频
1.选中网站,在右侧找到iis中的MINE类型 2.点击最右侧的添加按钮,提示输入扩展名 3. apk:在弹出的添加窗口里的文件扩展名输入:APK在MIME类型输入:application/vnd.a ...
- zabbix企业应用之bind dns监控(转)
继续介绍zabbix监控企业应用的实例,本次介绍zabbix监控dns,我监控的dns为bind 9.8.2,本dns为公网dns,是为了解决公司内网服务器自动化所需求的dns解析,比如目前的pupp ...