Spark shuffle详细过程
有许多场景下,我们需要进行跨服务器的数据整合,比如两个表之间,通过Id进行join操作,你必须确保所有具有相同id的数据整合到相同的块文件中。那么我们先说一下mapreduce的shuffle过程。
Mapreduce的shuffle的计算过程是在executor中划分mapper与reducer。Spark的Shuffling中有两个重要的压缩参数。spark.shuffle.compress true---是否将会将shuffle中outputs的过程进行压缩。将spark.io.compression.codec编码器设置为压缩数据,默认是true.同时,通过spark.shuffle.manager 来设置shuffle时的排序算法,有hash,sort,tungsten-sort。(用hash会快一点,我不需要排序啊~)
Hash Shuffle
使用hash散列有很多缺点,主要是因为每个Map task都会为每个reduce生成一份文件,所以最后就会有M * R个文件数量。那么如果在比较多的Map和Reduce的情况下就会出问题,输出缓冲区的大小,系统中打开文件的数量,创建和删除所有这些文件的速度都会受到影响。如下图:
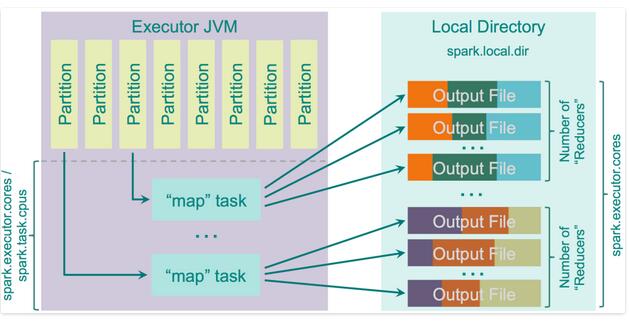
这里有一个优化的参数spark.shuffle.consolidateFiles,默认为false,当设置成true时,会对mapper output时的文件进行合并。如果你集群有E个executors(“-num-excutors”)以及C个cores("-executor-cores”),以及每个task又T个CPUs(“spark.task.cpus”),那么总共的execution的slot在集群上的个数就是E * C / T(也就是executor个数×CORE的数量/CPU个数)个,那么shuffle过程中所创建的文件就为E * C / T * R(也就是executor个数 × core的个数/CPU个数×reduce个数)个。外文文献写的太公式化,那么我用通俗易懂的形式阐述下。就好比总共的并行度是20(5个executor,4个task) Map阶段会将数据写入磁盘,当它完成时,他将会以reduce的个数来生成文件数。那么每个executor就只会计算core的数量/cpu个数的tasks.如果task数量大于总共集群并行度,那么将开启下一轮,轮询执行。
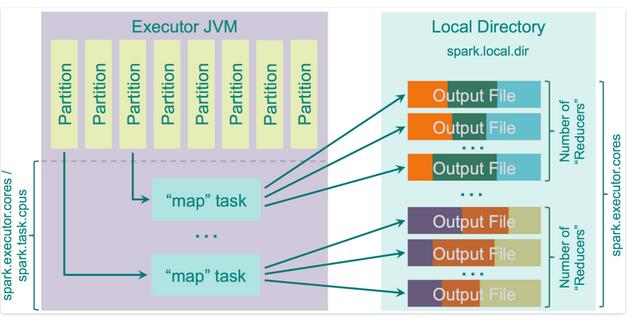
速度较快,因为没有再对中间结果进行排序,减少了reduce打开文件时的性能消耗。
当然,当数据是经过序列化以及压缩的。当重新读取文件,数据将进行解压缩与反序列化,这里reduce端数据的拉取有个参数spark.reducer.maxSizeInFlight(默认为48MB),它将决定每次数据从远程的executors中拉取大小。这个拉取过程是由5个并行的request,从不同的executor中拉取过来,从而提升了fetch的效率。 如果你加大了这个参数,那么reducers将会请求更多的文数据进来,它将提高性能,但是也会增加reduce时的内存开销。
Sort Shuffle
Sort Shuffle如同hash shuffle map写入磁盘,reduce拉取数据的一个性质,当在进行sort shuffle时,总共的reducers要小于spark.shuffle.sort.bypassMergeThrshold(默认为200),将会执行回退计划,使用hash将数据写入单独的文件中,然后将这些小文件聚集到一个文件中,从而加快了效率。(实现自BypassMergeSortShuffleWriter中)
那么它的实现逻辑是在reducer端合并mappers的输出结果。Spark在reduce端的排序是用了TimSort,它就是在reduce前,提前用算法进行了排序。 那么用算法的思想来说,合并的M N个元素进行排序,那么其复杂度为O(MNlogM) 具体算法不讲了~要慢慢看~
随之,当你没有足够的内存保存map的输出结果时,在溢出前,会将它们disk到磁盘,那么缓存到内存的大小便是 spark.shuffle.memoryFraction * spark.shuffle.safyFraction.默认的情况下是”JVM Heap Size * 0.2 * 0.8 = JVM Heap Size * 0.16”。需要注意的是,当你多个线程同时在一个executor中运行时(spark.executor.cores/spark.task.cpus 大于1的情况下),那么map output的每个task将会拥有 “JVM Heap Size * spark.shuffle.memoryFraction * spark.shuffle.safetyFraction / spark.executor.cores * spark.task.cpus。运行原理如下图:
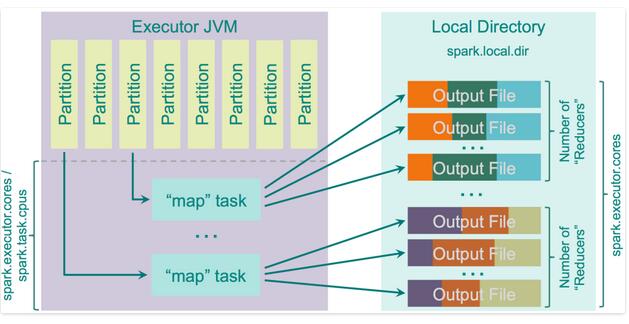
使用此种模式,会比使用hashing要慢一点,可通过bypassMergeThreshold找到集群的最快平衡点。
Tungsten Sort
使用此种排序方法的优点在于,操作的二进制数据不需要进行反序列化。它使用 sun.misc.Unsafe模式进行直接数据的复制,因为没有反序列化,所以直接是个字节数组。同时,它使用特殊的高效缓存器ShuffleExtemalSorter压记录与指针以及排序的分区id.只用了8 Bytes的空间的排序数组。这将会比使用CPU缓存要效率。
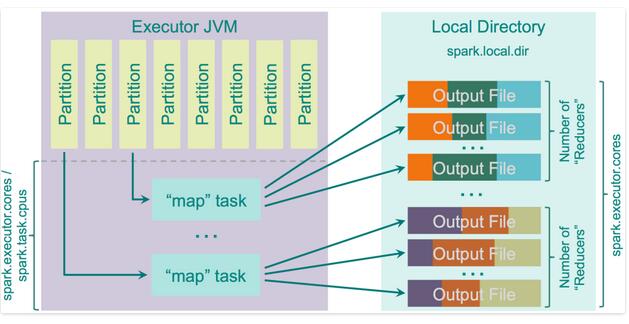
每个spill的数据、指针进行排序,输出到一个索引文件中。随后将这些partitions再次合并到一个输出文件中。
本文翻译自一位国外大神的博客:https://0x0fff.com/spark-memory-management/
Spark shuffle详细过程的更多相关文章
- Mac配置Scala和Spark最详细过程
Mac配置Scala和Spark最详细过程 原文链接: http://www.cnblogs.com/blog5277/p/8567337.html 原文作者: 博客园--曲高终和寡 一,准备工作 1 ...
- Spark Shuffle数据处理过程与部分调优(源码阅读七)
shuffle...相当重要,为什么咩,因为shuffle的性能优劣直接决定了整个计算引擎的性能和吞吐量.相比于Hadoop的MapReduce,可以看到Spark提供多种计算结果处理方式,对shuf ...
- 浅析 Spark Shuffle 内存使用
在使用 Spark 进行计算时,我们经常会碰到作业 (Job) Out Of Memory(OOM) 的情况,而且很大一部分情况是发生在 Shuffle 阶段.那么在 Spark Shuffle 中具 ...
- Spark源码系列(六)Shuffle的过程解析
Spark大会上,所有的演讲嘉宾都认为shuffle是最影响性能的地方,但是又无可奈何.之前去百度面试hadoop的时候,也被问到了这个问题,直接回答了不知道. 这篇文章主要是沿着下面几个问题来开展: ...
- 022 Spark shuffle过程
1.官网 http://spark.apache.org/docs/1.6.1/configuration.html#shuffle-behavior Spark数据进行重新分区的操作就叫做shuf ...
- Spark 源码系列(六)Shuffle 的过程解析
Spark 大会上,所有的演讲嘉宾都认为 shuffle 是最影响性能的地方,但是又无可奈何.之前去百度面试 hadoop 的时候,也被问到了这个问题,直接回答了不知道. 这篇文章主要是沿着下面几个问 ...
- Spark原始码系列(六)Shuffle的过程解析
问题导读: 1.shuffle过程的划分? 2.shuffle的中间结果如何存储? 3.shuffle的数据如何拉取过来? Shuffle过程的划分 Spark的操作模型是基于RDD的,当调用RD ...
- Spark Shuffle机制详细源码解析
Shuffle过程主要分为Shuffle write和Shuffle read两个阶段,2.0版本之后hash shuffle被删除,只保留sort shuffle,下面结合代码分析: 1.Shuff ...
- Spark Shuffle原理、Shuffle操作问题解决和参数调优
摘要: 1 shuffle原理 1.1 mapreduce的shuffle原理 1.1.1 map task端操作 1.1.2 reduce task端操作 1.2 spark现在的SortShuff ...
随机推荐
- iOS--时间类date详解
NSDate定义时间的类 NSDate是一个时间类,在编写程序时,我们很少遇到.今天我突然碰到,感觉很生疏. 给大家发个博客,让大家也都温习一下,哈哈! 兄弟用的时候突然发现竟然有一些bug,大家用时 ...
- C++模板实例化
深入理解C++中第七章提到模板实例化参数的选择:函数的决议结果只和函数参数有关和返回值无关.记录一下. 测试程序如下: #include <iostream> using namespac ...
- Oracle 常用修改字段SQL语句
1. 更新字段名称 alter table table_name rename column column_old to column_new; 2. 添加字段 ); 3. 删除字段 alter ta ...
- Linux 指令。
从16年11月21号开始吧,加班变得特别频繁,基本上一周加5天,周六也会加,下班也很晚,一般都是10点9点,回家之后很疲惫,已经很久没有给自己充过电了,自己的学习计划和健身计划也打乱了,对工作的压力也 ...
- Java框架重量级,轻量级的问题?
一般认为,SSH为重量级.SSI为轻量级. 但轻重的概念怎么界定?
- CentOS7防火墙
一.CentOS7依然使用iptables的方法 CentOS7不再使用iptables,而是使用firewalld,若不想使用firewalld,可以停掉firewalld并且安装iptables- ...
- Android——黑名单
<?xml version="1.0" encoding="utf-8"?> <LinearLayout xmlns:android=&quo ...
- uva 12169
/* 巨大的斐波那契数列_________________________________________________________________________________ #inclu ...
- HDU-2243 考研路茫茫——单词情结(AC自动机)
题目大意:给n个单词,长度不超过L的单词有多少个包含n个单词中的至少一个单词. 题目分析:用长度不超过L的单词书目减去长度在L之内所有不包含任何一个单词的书目. 代码如下: # include< ...
- squid源码安装下的conf文件默认值和提示
# WELCOME TO SQUID 3.0.STABLE26# ----------------------------## This is the default Squid c ...