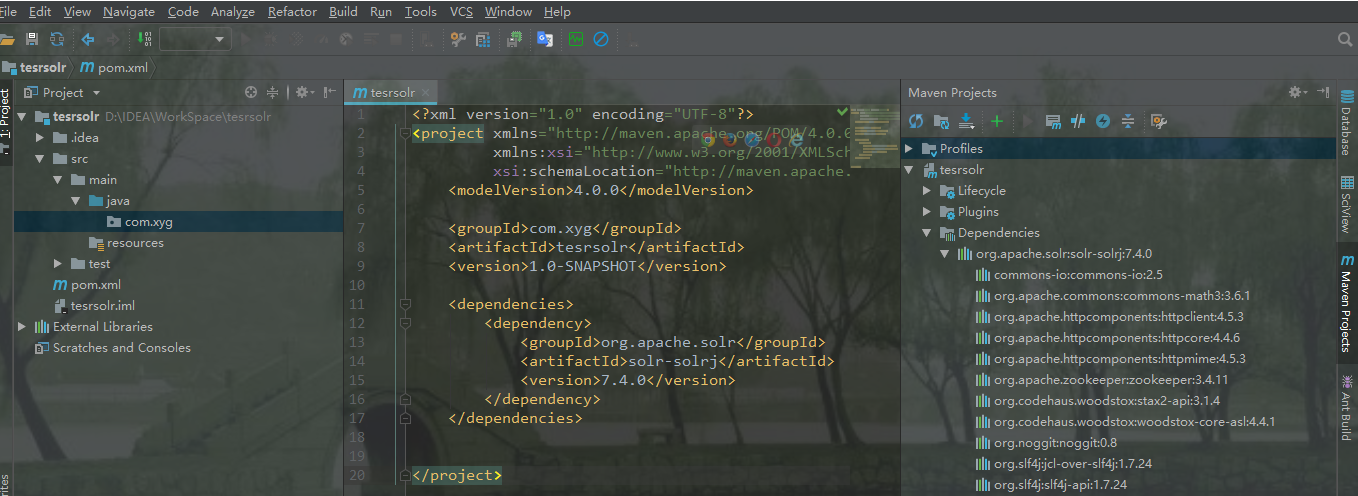
Solr7.4.0的API(Solrj)操作
一.SolrJ的概念
solr单机版服务搭建:https://www.cnblogs.com/frankdeng/p/9615253.html
solr集群版服务搭建:https://www.cnblogs.com/frankdeng/p/9597680.html
SolrJ是一个API,它使用Java(或任何基于JVM的语言)编写的应用程序可以轻松地与Solr交谈。SolrJ隐藏了许多连接到Solr的细节,并允许您的应用程序通过简单的高级方法与Solr交互。SolrJ支持大多数Solr API,并且具有高度可配置性。
官方API参考文档: http://lucene.apache.org/solr/guide/7_4/using-solrj.html#using-solrj
这里使用Maven构建项目,请将以下内容放入pom.xml:
<dependency>
<groupId>org.apache.solr</groupId>
<artifactId>solr-solrj</artifactId>
<version>7.4.0</version>
</dependency>
为了方便测试,导入单元测试依赖和日志依赖
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-nop</artifactId>
<version>1.7.25</version>
</dependency>
二.SolrJ的单机连接
SolrClient是一个抽象类,下边有很多被实现的子类,HttpSolrClient - 面向以查询为中心的工作负载,但也是一个很好的通用客户端。直接与单个Solr节点通信。
不同solr版本solrj 的创建方式有所不同
//solr4创建方式
SolrServer solrServer = new HttpSolrServer(solrUrl);
//solr5创建方式,在url中指定core名称:core1
HttpSolrClient solrClient = new HttpSolrClient(solrUrl);
//solr7创建方式,在url中指定core名称:core1
HttpSolrClient solrClient = new HttpSolrClient.Builder(solrUrl).build();
例如:
package com.xyg.solr; import org.apache.solr.client.solrj.impl.HttpSolrClient;
import org.junit.Test; /**
* Author: Mr.Deng
* Date: 2018/9/10
* Desc: 测试连接客户端
*/
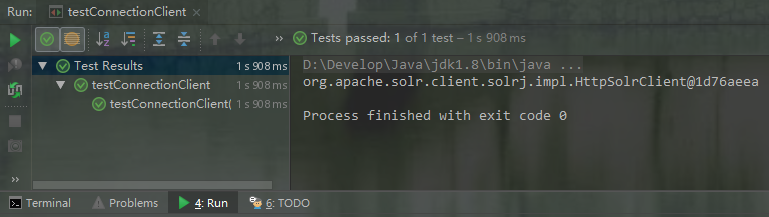
public class testConnectionClient { @Test
public void testConnectionClient(){
//设置solr客户端url地址
String solrUrl = "http://node21:8080/solr/new_core";
//创建solrClient同时指定超时时间,不指定走默认配置
HttpSolrClient solrClient = new HttpSolrClient.Builder(solrUrl)
.withConnectionTimeout()
.withSocketTimeout()
.build();
System.out.println(solrClient);
}
}
三.SolrJ的集群连接
CloudSolrClient - 面向与SolrCloud部署的通信。使用已记录的ZooKeeper状态来发现并将请求路由到健康的Solr节点。
package com.xyg.solrCloud; import org.apache.solr.client.solrj.impl.CloudSolrClient;
import org.junit.Test; /**
* Author: Mr.Deng
* Date: 2018/9/10
* Desc: 测试连接客户端
*/
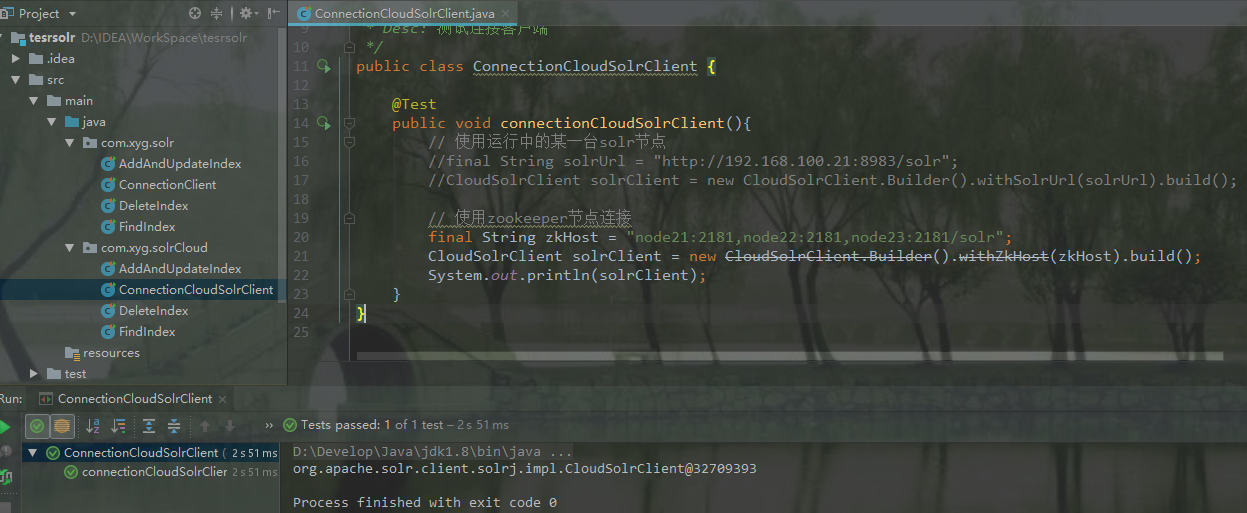
public class ConnectionCloudSolrClient { @Test
public void connectionCloudSolrClient(){
// 第一种方式:使用运行中的某一台solr节点
//final String solrUrl = "http://192.168.100.21:8983/solr";
//CloudSolrClient solrClient = new CloudSolrClient.Builder().withSolrUrl(solrUrl).build(); // 第二种方式:使用zookeeper节点连接(推荐)
final String zkHost = "node21:2181,node22:2181,node23:2181/solr";
CloudSolrClient solrClient = new CloudSolrClient.Builder().withZkHost(zkHost).build();
System.out.println(solrClient);
}
}
四.SolrJ的增删改查
这里测试单机版APi操作
1.创建索引
1)指定id单条创建索引
@Test
public void addIndexById() throws IOException, SolrServerException {
String solrUrl = "http://node21:8080/solr/new_core";
HttpSolrClient solrClient = new HttpSolrClient.Builder(solrUrl).build();
//创建索引文档对象
SolrInputDocument doc = new SolrInputDocument();
// 第一个参数:域的名称,域的名称必须是在schema.xml中定义的
// 第二个参数:域的值,注意:id的域不能少
doc.addField("id","");
doc.addField("name","红豆");
doc.addField("price","1.2");
//3.将文档写入索引库中
solrClient.add(doc);
solrClient.commit();
}
2)批量创建索引
@Test
public void addIndexByListId() throws Exception {
String solrUrl = "http://node21:8080/solr/new_core";
HttpSolrClient solrClient = new HttpSolrClient.Builder(solrUrl).build();
//创建索引文档对象
SolrInputDocument doc1 = new SolrInputDocument();
doc1.addField( "id", "");
doc1.addField( "name", "绿豆");
doc1.addField( "price", 1.8 );
SolrInputDocument doc2 = new SolrInputDocument();
doc2.addField( "id", "" );
doc2.addField( "name", "黑豆" );
doc2.addField( "price", 2.6 );
Collection<SolrInputDocument> docs = new ArrayList<SolrInputDocument>();
docs.add(doc1);
docs.add(doc2);
//3.将文档写入索引库中
solrClient.add(docs);
solrClient.commit();
}
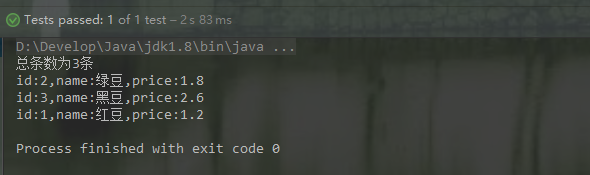
2.查询索引
1)匹配查询
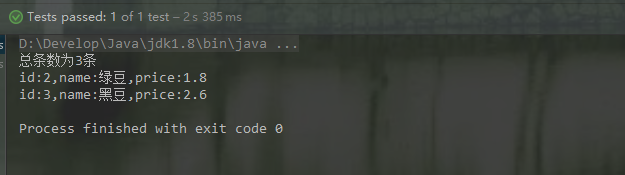
@Test
public void findIndex1() throws IOException, SolrServerException {
String solrUrl = "http://node21:8080/solr/new_core";
HttpSolrClient solrClient = new HttpSolrClient.Builder(solrUrl).build();
// 创建搜索对象
SolrQuery query = new SolrQuery();
// 设置搜索条件
query.set("q","*:*");
//设置每页显示多少条
query.setRows();
//发起搜索请求
QueryResponse response = solrClient.query(query);
// 查询结果
SolrDocumentList docs = response.getResults();
// 查询结果总数
long cnt = docs.getNumFound();
System.out.println("总条数为"+cnt+"条");
for (SolrDocument doc : docs) {
System.out.println("id:"+ doc.get("id") + ",name:"+ doc.get("name") + ",price:"+ doc.get("price"));
}
solrClient.close();
}
2)条件过滤查询
@Test
public void findIndex2() throws IOException, SolrServerException {
String solrUrl = "http://node21:8080/solr/new_core";
HttpSolrClient solrClient = new HttpSolrClient.Builder(solrUrl).build();
//2 封装查询参数
Map<String, String> queryParamMap = new HashMap<String, String>();
queryParamMap.put("q", "*:*");
//3 添加到SolrParams对象,SolrParams 有一个 SolrQuery 子类,它提供了一些方法极大地简化了查询操作
MapSolrParams queryParams = new MapSolrParams(queryParamMap);
//4 执行查询返回QueryResponse
QueryResponse response = solrClient.query(queryParams);
//5 获取doc文档
SolrDocumentList docs = response.getResults();
// 查询结果总数
long cnt = docs.getNumFound();
System.out.println("总条数为" + cnt + "条");
//[6]内容遍历
for (SolrDocument doc : docs) {
System.out.println("id:" + doc.get("id") + ",name:" + doc.get("name") + ",price:" + doc.get("price"));
}
solrClient.close();
}
3.更新索引
@Test
public void updateIndex() throws IOException, SolrServerException {
String solrUrl = "http://node21:8080/solr/new_core";
HttpSolrClient solrClient = new HttpSolrClient.Builder(solrUrl).build();
//创建索引文档对象
SolrInputDocument doc = new SolrInputDocument();
//把红豆价格修改为1.5
doc.addField("id","");
doc.addField("name","红豆");
doc.addField("price","1.5");
//3.将文档写入索引库中
solrClient.add(doc);
solrClient.commit();
//提交
solrClient.commit(); }
4.删除索引
1)单一条件删除
@Test
public void deleteIndexById() throws IOException, SolrServerException {
String solrUrl = "http://node21:8080/solr/new_core";
HttpSolrClient solrClient = new HttpSolrClient.Builder(solrUrl).build();
//全删
//solrClient.deleteByQuery("*:*");
//模糊匹配删除(带有分词效果的删除)
solrClient.deleteByQuery("name:红");
//指定id删除
//solrClient.deleteById("1");
solrClient.commit();
}
2)批量条件删除
@Test
public void deleteIndexByListId() throws IOException, SolrServerException {
String solrUrl = "http://node21:8080/solr/new_core";
HttpSolrClient solrClient = new HttpSolrClient.Builder(solrUrl).build();
//通过id删除
ArrayList<String> ids = new ArrayList<String>();
ids.add("");
ids.add("");
solrClient.deleteById(ids);
//[3]提交
solrClient.commit();
//[4]关闭资源
solrClient.close();
}
五.代码报错问题
1.代码添加索引报405问题
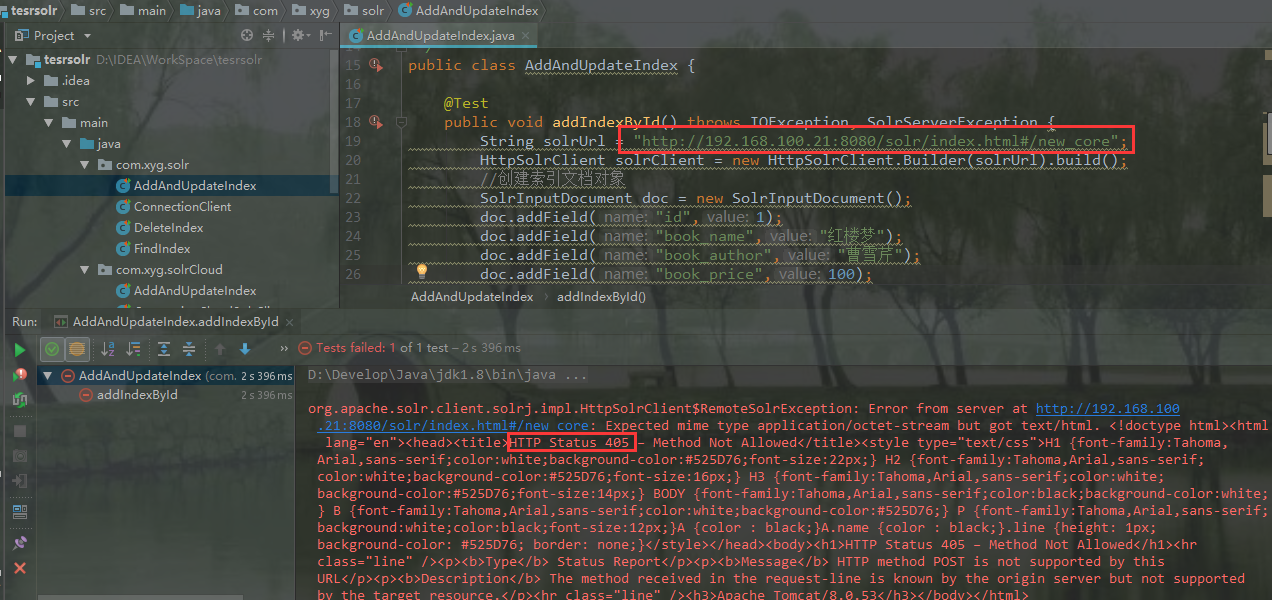
解决方法:
在使用Tomcat部署Solr后,new_core的地址为:http://node21:8080/solr/#/new_core,但使用SolrJ进行索引的时候,应该使用http://node21:8080/solr/new_core,即无中间的#号。
2.自定义索引字段
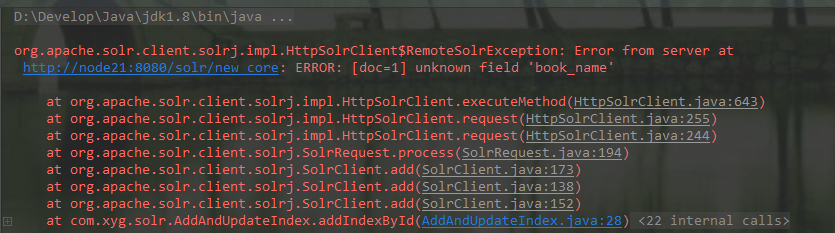
上图报错提示未识别索引字段
参考文档:
https://www.w3cschool.cn/solr_doc/solr_doc-g1az2fmd.html
https://www.cnblogs.com/gaogaoyanjiu/p/7815558.html
https://www.jianshu.com/p/11fb9cfdb2fd
Solr7.4.0的API(Solrj)操作的更多相关文章
- Solr7.4.0的API(Solrj)操作及项目中的使用
一.SolrJ的概念 solr单机版服务搭建:https://www.cnblogs.com/frankdeng/p/9615253.html solr集群版服务搭建:https://www.cnbl ...
- (五)solr7.1.0之solrJ的使用
(五)solr7.1.0之solrJ的使用 下面是solr7的官网API介绍: 网页翻译的不是很准确,只能了解个大概,基本能获取如下信息: 一.构建和运行SolrJ应用程序 对于用Maven构建的项目 ...
- solr7.4.0+mysql+solrj(简而优美)
目录: 1 solr7部署+创建核心2 solr mysql 连接 2.1 导入相关 jar包 2.2 配置连接信息 2.3 配置中文分析器3 solrj JAVA客户端应用 3.1 solrj 构建 ...
- 利用SolrJ操作solr API完成index操作
使用SolrJ操作Solr会比利用httpClient来操作Solr要简单.SolrJ是封装了httpClient方法,来操作solr的API的.SolrJ底层还是通过使用httpClient中的方法 ...
- Solr 14 - SolrJ操作SolrCloud集群 (Solr的Java API)
目录 1 pom.xml文件的配置 2 SolrJ操作SolrCloud 1 pom.xml文件的配置 项目的pom.xml依赖信息请参照: Solr 09 - SolrJ操作Solr单机服务 (So ...
- Solr 09 - SolrJ操作Solr单机服务 (Solr的Java API)
目录 1 SolrJ是什么 2 SolrJ对索引的CRUD操作 2.1 创建Maven工程(打包方式选择为jar) 2.2 配置pom.xml文件, 加入SolrJ的依赖 2.3 添加和修改索引 2. ...
- Spark 下操作 HBase(1.0.0 新 API)
hbase1.0.0版本提供了一些让人激动的功能,并且,在不牺牲稳定性的前提下,引入了新的API.虽然 1.0.0 兼容旧版本的 API,不过还是应该尽早地来熟悉下新版API.并且了解下如何与当下正红 ...
- 使用solrj操作solr索引库,solr是lucene服务器
客户端开发 Solrj 客户端开发 Solrj Solr是搭建好的lucene服务器 当然不可能完全满足一般的业务需求 可能 要针对各种的架构和业务调整 这里就需要用到Solrj了 Solrj是Sol ...
- 使用solrJ操作solr常用方法 【注释非常详细,非常好】
转: 使用solrJ操作solr常用方法 2017年08月07日 22:49:06 成都往右 阅读数:8990 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.cs ...
随机推荐
- Hello 2018 A,B,C,D
A. Modular Exponentiation time limit per test 1 second memory limit per test 256 megabytes input sta ...
- 界面编程之QT绘图和绘图设备20180728
/*******************************************************************************************/ 一.绘图 整 ...
- sso接口的调用
之前一直想sso接口已经写好了,登录注册功能是怎么调用的呢?原来在登录注册的jsp页面实现的接口的调用,页面的校验和验证功能在jsp页面即可实现. 注册页面: <%@ page language ...
- HTML5 文件API
filelist 表示文件对象的列表. <form name="upload"> <input type="file" name=" ...
- Hadoop基础--统计商家id的标签数案例分析
Hadoop基础--统计商家id的标签数案例分析 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.项目需求 将“temptags.txt”中的数据进行分析,统计出商家id的评论标 ...
- [六字真言]6.吽.SpringMVC中上传大小异常填坑
最近在讲课的时候,遇到了关于上传文件过大的时候浏览器无法响应的问题,配置了捕获异常,有的学生浏览器好使,有的学生浏览器不好用!莫名其妙! MaxUploadSizeExceededException进 ...
- RESTful记录-RESTful内容
什么是资源? REST架构对待每一个内容都作为一种资源.这些资源可以是文本文件,HTML网页,图片,视频或动态业务数据. REST服务器只是提供资源,REST客户端可访问和修改的资源.这里每个资源由U ...
- [整理]IIS 6.0 下部署 Asp.net MVC Web Api 后 HTTP PUT and DELETE 请求失败
http://guodong.me/?p=1560 ASP.NET MVC 4 has a new feature called WebAPI which makes it much easier t ...
- J2EE的体系结构是指什么?
J2EE 即Java2平台企业版,它提供了基于组件的方式来设计.开发.组装和部署企业应用.J2EE使用多层分布式的应用模型,这个多层通常通过三层或四层来实现: 客户层,运行在客户计算机上的组件. We ...
- 如何使用gifsicle压缩gif图片
最近我写了一些关于如何将各种形式的多媒体格式相互转换的文章,特别是GIF动图方面的,比如如何将小视频转换成GIF动图或将GIF动图转换成视频,有很多像ImageMagick,ffmpeg这样的工具帮助 ...