Spark sql 简单使用
一、认识Spark sql
1、什么是Sparksql?
spark sql是spark的一个模块,主要用于进行结构化数据的处理,它提供的最核心抽象就是DataFrame。
2、SparkSQL的作用?
提供一个编程抽象(DataFrame),并且作为分布式SQL查询引擎
DataFrame:它可以根据很多源进行构建,包括:结构化的数据文件、hive中的表,外部的关系型数据库、以及RDD
3、运行原理
将SparkSQL转化为RDD,然后提交到集群执行
4、特点
容易整合、统一的数据访问方式、兼容Hive、标准的数据连接
5、SparkSession
SparkSession是Spark 2.0引如的新概念。SparkSession为用户提供了统一的切入点,来让用户学习spark的各项功能。
在spark的早期版本中,SparkContext是spark的主要切入点,由于RDD是主要的API,我们通过sparkcontext来创建和操作RDD。对于每个其他的API,我们需要使用不同的context。例如,对于Streming,我们需要使用StreamingContext;对于sql,使用sqlContext;对于Hive,使用hiveContext。但是随着DataSet和DataFrame的API逐渐成为标准的API,就需要为他们建立接入点。所以在spark2.0中,引入SparkSession作为DataSet和DataFrame API的切入点,SparkSession封装了SparkConf、SparkContext和SQLContext。为了向后兼容,SQLContext和HiveContext也被保存下来。
SparkSession实质上是SQLContext和HiveContext的组合(未来可能还会加上StreamingContext),所以在SQLContext和HiveContext上可用的API在SparkSession上同样是可以使用的。SparkSession内部封装了sparkContext,所以计算实际上是由sparkContext完成的。
特点:
---- 为用户提供一个统一的切入点使用Spark 各项功能
---- 允许用户通过它调用 DataFrame 和 Dataset 相关 API 来编写程序
---- 减少了用户需要了解的一些概念,可以很容易的与 Spark 进行交互
---- 与 Spark 交互之时不需要显示的创建 SparkConf, SparkContext 以及 SQlContext,这些对象已经封闭在 SparkSession 中
6、DataFrame
在Spark中,DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格。DataFrame与RDD的主要区别在于,前者带有schema元信息,即DataFrame所表示的二维表数据集的每一列都带有名称和类型。这使得Spark SQL得以洞察更多的结构信息,从而对藏于DataFrame背后的数据源以及作用于DataFrame之上的变换进行了针对性的优化,最终达到大幅提升运行时效率的目标。反观RDD,由于无从得知所存数据元素的具体内部结构,Spark Core只能在stage层面进行简单、通用的流水线优化。

二、RDD转换成DataFrame
使用spark1.x版本的方式
测试数据:
qqq,12
ddd,11
ccc,44
1、方式一:通过case class创建DataFrames(反射推断模式)
使用反射推断的时候需要注意以下方式
1、将本地的一个文件转换成RDD 拿到文件-->拆分-->组合成样例类的格式
2、将转换之后的RDD又转成DataFrame .toDF
3、为DF注册一个临时表名
4、调用sqlContext.sql("sql语句")就可以调用show方法了
5、关闭
object DataFrameTest {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("DataFrameTest").setMaster("local")
val sc = new SparkContext(conf)
val context = new SQLContext(sc)
// 将本地的数据读入 RDD, 并将 RDD 与 case class 关联
val peopleRDD = sc.textFile("D:\\Student.txt")
.map(line => Student(line.split(",")(0), line.split(",")(1).trim.toInt))
import context.implicits._
// 将RDD 转换成 DataFrames
val df = peopleRDD.toDF
//将DataFrames注册成一张临时表
df.registerTempTable("Student")
//使用SQL语句进行查询
context.sql("select * from Student").show()
}
case class Student(name:String,age:Int)
}
方式二:通过 structType 创建 DataFrames(编程接口)
用户自定义模式:
1、构造出StructType类型
2、构造RDD[Row]
3、创建dataFrame
4、注册表名
5、执行sql
6、关闭
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Row, SQLContext}
import org.apache.spark.{SparkConf, SparkContext}
object StructTypeTest {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("hello sql")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
//加入隐式转换
//将普通文件转换成RDD
val textRDD = sc.textFile("d:/Student.txt")
//定义schema的字段名
val schemaString: String = "name age"
import org.apache.spark.sql.types.{StringType, StructField, StructType}
//构造StructType类型
val structType: StructType = StructType(schemaString.split(" ").map(field => StructField(field, StringType, true)))
//将RDD转换成Row
val rowRDD: RDD[Row] = textRDD.map(_.split(",")).map(x => Row(x(0), x(1)))
//将schema与数据进行关联
val frame: DataFrame = sqlContext.createDataFrame(rowRDD, structType)
frame.registerTempTable("person") //创建虚表
val sql: DataFrame = sqlContext.sql("select * from person where age>2") //执行语句
sql.show()
}
}
方式三:通过 json 文件创建 DataFrames
{"name":"sada","age":12}
{"name":"wew","age":22}
{"name":"sadsda","age":23}
object JsonDatFrameTest {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("hello sql")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
val df: DataFrame = sqlContext.read.json("D://Student.json")
df.registerTempTable("Student")
val sql: DataFrame = sqlContext.sql("select * from Student") //执行语句
sql.show()
}
}
三、DataFrame的read和save和savemode
1、数据的读取
object TestRead {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("TestDataFrame2").setMaster("local")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
//方式一
val df1 = sqlContext.read.json("E:\\666\\people.json")
//面向列式存储
val df2 = sqlContext.read.parquet("E:\\666\\users.parquet")
//方式二
val df3 = sqlContext.read.format("json").load("E:\\666\\people.json")
val df4 = sqlContext.read.format("parquet").load("E:\\666\\users.parquet")
//方式三,默认是parquet格式
val df5 = sqlContext.load("E:\\666\\users.parquet")
}
}
2、数据的保存
object TestSave {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("TestDataFrame2").setMaster("local")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
val df1 = sqlContext.read.json("E:\\666\\people.json")
//方式一
df1.write.json("E:\\111")
//注意:在持久化的时候,读取json格式的文件,直接保存的时候,默认为parquet模式
df1.write.parquet("E:\\222")
//方式二
df1.write.format("json").save("E:\\333")
df1.write.format("parquet").save("E:\\444")
//方式三
df1.write.save("E:\\555")
}
}
3、数据的保存模式
使用mode
df1.write.format("parquet").mode(SaveMode.Ignore).save("E:\\444")

四、数据源
1、json格式
读取json格式,并持久化为parquet格式,并保存在d盘
val conf = new SparkConf().setMaster("local[*]").setAppName("hello sql")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
//加入隐式转换
import sqlContext.implicits._
//读取json文件的时候操作方式
val frame: DataFrame = sqlContext.read.json("d:/hello.json")
// frame.show()//直接控制台显示
frame.select("name").write.format("parquet").save("d:/task")//持久化为parquet格式,保存在d盘
注意:在持久化的时候,读取json格式的文件,直接保存的时候,默认为parquet模式
如果需要将结构输出为文本格式的话,可以将dataFrame转为RDD之后在进行处理并操作
//读取json文件的时候操作方式
val frame: DataFrame = sqlContext.read.json("d:/hello.json")
val frame1: DataFrame = frame.select("name")
//将frame1转为一个RDD
val rdd: RDD[Row] = frame1.rdd
rdd.map(_.get(0)).saveAsTextFile("d:/task3")
2、parquet格式:面向列式存储
读取parquet格式,并持久化为json格式
//读取parquet格式文件的操作方式
val frame: DataFrame = sqlContext.read.load("d:/task")
frame.select("name").write.format("json").save("d:/task1")
3、jdbc格式
需要加入相应的驱动包
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
</dependency>
var option=Map("url"->"jdbc:mysql://192.168.100.121/big_data?user=root&password=1234","dbtable"->"person")
val frame: DataFrame = sqlContext.read.format("jdbc").options(option).load()
frame.select("name").show()
或者
val conf = new SparkConf().setAppName("TestMysql").setMaster("local")
val sc = new SparkContext(conf) val sqlContext = new SQLContext(sc)
val url = "jdbc:mysql://192.168.123.102:3306/hivedb" val table = "dbs"
val properties = new Properties()
properties.setProperty("user","root")
properties.setProperty("password","root") //需要传入Mysql的URL、表明、properties(连接数据库的用户名密码)
val df = sqlContext.read.jdbc(url,table,properties)
df.createOrReplaceTempView("dbs")
sqlContext.sql("select * from dbs").show()
4、txt格式采用反射推断或者用户自定义格式
//RDD text保存只支持string类型
sc.makeRDD(1 to(10)).map(_.toString).toDF("number").write.text("d:/task4")
5、数据源之Hive
(1)准备工作
在pom.xml文件中添加依赖
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-hive -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>2.3.0</version>
</dependency>
开发环境则把resource文件夹下添加hive-site.xml文件,集群环境把hive的配置文件要发到$SPARK_HOME/conf目录下
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hivedb?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
<!-- 如果 mysql 和 hive 在同一个服务器节点,那么请更改 hadoop02 为 localhost -->
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
<description>password to use against metastore database</description>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/hive/warehouse</value>
<description>hive default warehouse, if nessecory, change it</description>
</property>
</configuration>
(2)测试代码
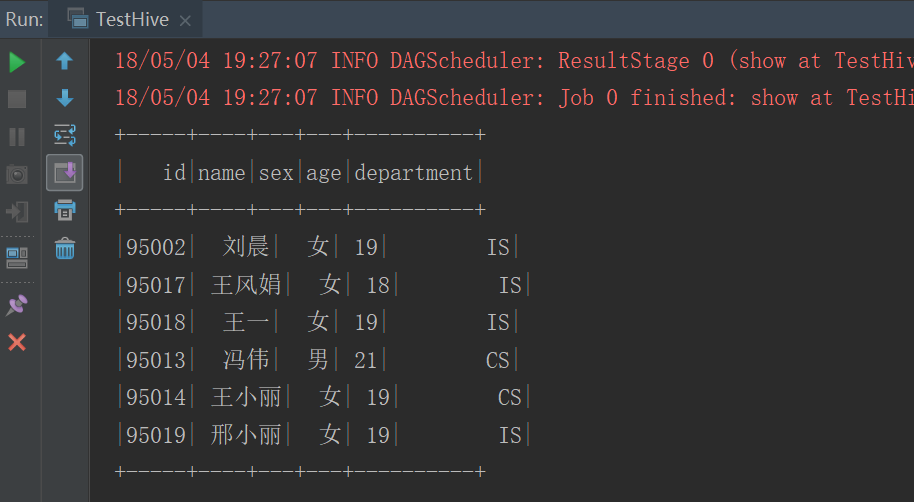
object TestHive {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName(this.getClass.getSimpleName)
val sc = new SparkContext(conf)
val sqlContext = new HiveContext(sc)
sqlContext.sql("select * from myhive.student").show()
}
}
运行结果
Spark sql 简单使用的更多相关文章
- Spark的Streaming和Spark的SQL简单入门学习
1.Spark Streaming是什么? a.Spark Streaming是什么? Spark Streaming类似于Apache Storm,用于流式数据的处理.根据其官方文档介绍,Spark ...
- spark sql的简单操作
测试数据 sparkStu.text zhangxs chenxy wangYr teacher wangx teacher sparksql { ,"job":"che ...
- Spark SQL 之 Data Sources
#Spark SQL 之 Data Sources 转载请注明出处:http://www.cnblogs.com/BYRans/ 数据源(Data Source) Spark SQL的DataFram ...
- Spark SQL 之 DataFrame
Spark SQL 之 DataFrame 转载请注明出处:http://www.cnblogs.com/BYRans/ 概述(Overview) Spark SQL是Spark的一个组件,用于结构化 ...
- 【原】Learning Spark (Python版) 学习笔记(三)----工作原理、调优与Spark SQL
周末的任务是更新Learning Spark系列第三篇,以为自己写不完了,但为了改正拖延症,还是得完成给自己定的任务啊 = =.这三章主要讲Spark的运行过程(本地+集群),性能调优以及Spark ...
- Spark 官方文档(5)——Spark SQL,DataFrames和Datasets 指南
Spark版本:1.6.2 概览 Spark SQL用于处理结构化数据,与Spark RDD API不同,它提供更多关于数据结构信息和计算任务运行信息的接口,Spark SQL内部使用这些额外的信息完 ...
- Spark SQL 官方文档-中文翻译
Spark SQL 官方文档-中文翻译 Spark版本:Spark 1.5.2 转载请注明出处:http://www.cnblogs.com/BYRans/ 1 概述(Overview) 2 Data ...
- Spark SQL External Data Sources JDBC简易实现
在spark1.2版本中最令我期待的功能是External Data Sources,通过该API可以直接将External Data Sources注册成一个临时表,该表可以和已经存在的表等通过sq ...
- Spark源码系列(九)Spark SQL初体验之解析过程详解
好久没更新博客了,之前学了一些R语言和机器学习的内容,做了一些笔记,之后也会放到博客上面来给大家共享.一个月前就打算更新Spark Sql的内容了,因为一些别的事情耽误了,今天就简单写点,Spark1 ...
随机推荐
- 第二十章、QTableView与QStandardItemModel开发实战:展示Excel文件内容
老猿Python博文目录 专栏:使用PyQt开发图形界面Python应用 老猿Python博客地址 一.概述 在前面<第十九章.Model/View开发:QTableView的功能及属性> ...
- PyQt(Python+Qt)学习随笔:QTableView的wordWrap属性
老猿Python博文目录 老猿Python博客地址 wordWrap属性用于控制视图中数据项文本的换行策略.如果此属性为True,则在数据项文本中分词的适当处进行换:否则数据项文本不进行换行处理.默认 ...
- XSS挑战赛(3)
查看关键代码: <?php ini_set("display_errors", 0); $str = $_GET["keyword"]; $str00 = ...
- 在IDEA上 使用maven进行打包时报错: Failed to execute goal org.apache.maven.plugins:maven-javadoc-plugin:2.10.2:jar
报错内容: Failed to execute goal org.apache.maven.plugins:maven-javadoc-plugin:2.10.2:jar (attach-javado ...
- Kruskal重构树——[NOI2018] 归程
题目链接: UOJ LOJ 感觉 Kruskal 重构树比较简单,就不单独开学习笔记了. Statement 给定一个 \(n\) 点 \(m\) 边的无向连通图,用 \(l,a\) 描述一条边的长度 ...
- 自定义Django认证系统的技术方案
Django已经提供了开箱即用的认证系统,但是可能并不满足我们的个性化需求.自定义认证系统需要知道哪些地方可以扩展,哪些地方可以替换.本文就来介绍自定义Django认证系统的相关技术细节. 自定义认证 ...
- Day1 字符串格式化
1.占位符方式:占位符: %d 整数 %012d 数字位数至少长度为12位,不足的前面加0填充. >>> 'Hello,%s,%012d' % ('a',12345678901234 ...
- SpringBoot基于JustAuth实现第三方授权登录
1. 简介 随着科技时代日渐繁荣,越来越多的应用融入我们的生活.不同的应用系统不同的用户密码,造成了极差的用户体验.要是能使用常见的应用账号实现全应用的认证登录,将会更加促进应用产品的推广,为生活 ...
- 【Go语言绘图】图片的旋转
在上一篇中,我们了解了gg库的基本使用,包括调整大小.调整圆形参数.设置颜色.保存图片.加载图片和裁剪.这一篇我们来学习一下图片的旋转. 加载图片 首先,我们先来一张黄图. func TestRota ...
- js上 五、运算符-1
5.1.认识运算符 什么是运算符? 运算符用于执行程序代码运算,会针对一个以上操作数项目来进行运算. 运算符的应用: 购物车:计算总价,数量: **Js ** 中有哪些运算符? 算术运算符.赋值运算符 ...