python爬取千库网
url:https://i588ku.com/beijing/0-0-default-0-8-0-0-0-0-1/
有水印
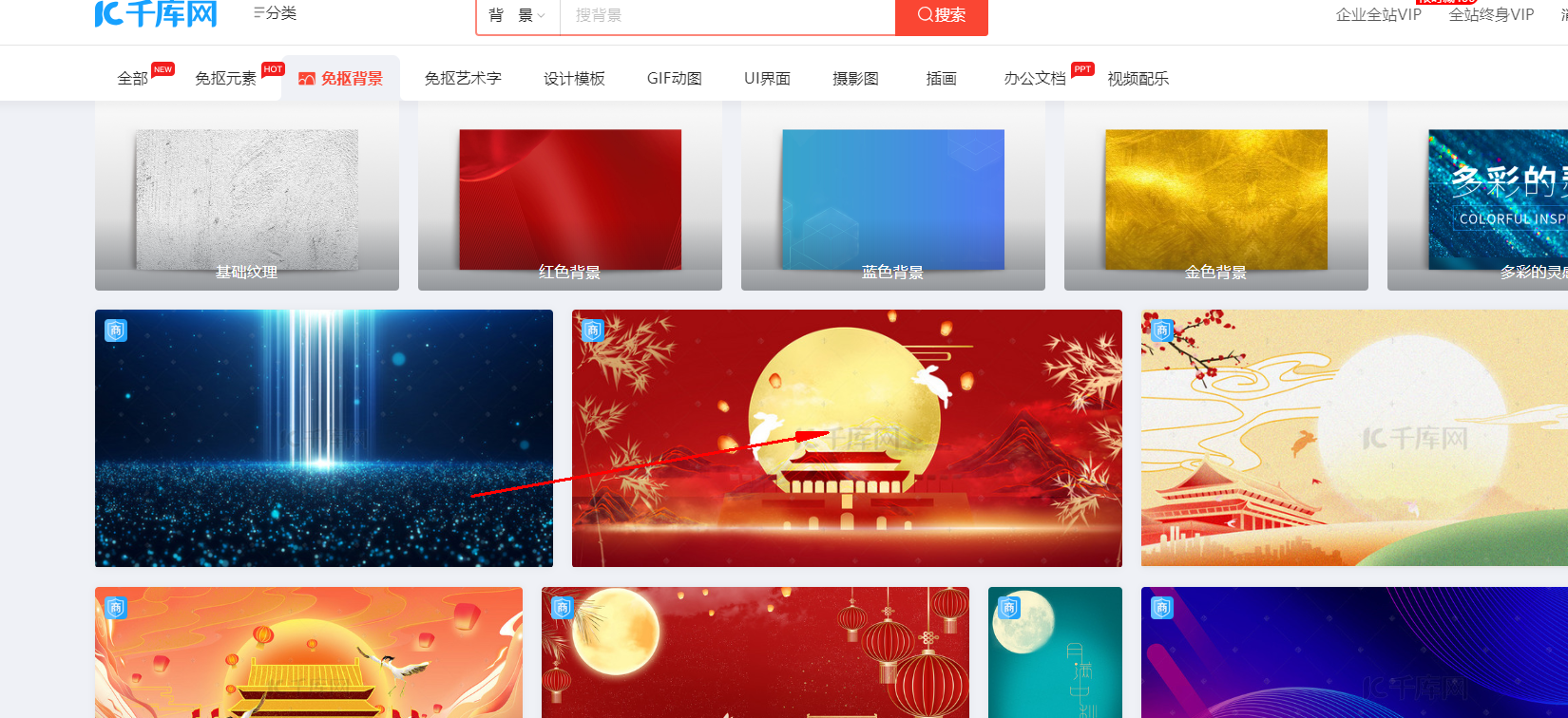
但是点进去就没了
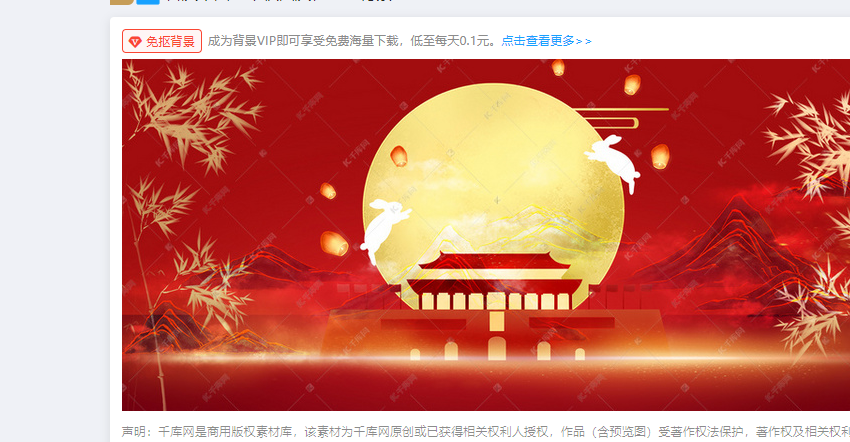
这里先来测试是否有反爬虫
import requests
from bs4 import BeautifulSoup
import os
html = requests.get('https://i588ku.com/beijing/0-0-default-0-8-0-0-0-0-1/')
print(html.text)
输出是404,添加个ua头就可以了
可以看到每个图片都在一个div class里面,比如fl marony-item bglist_5993476,是3个class但是最后一个编号不同就不取
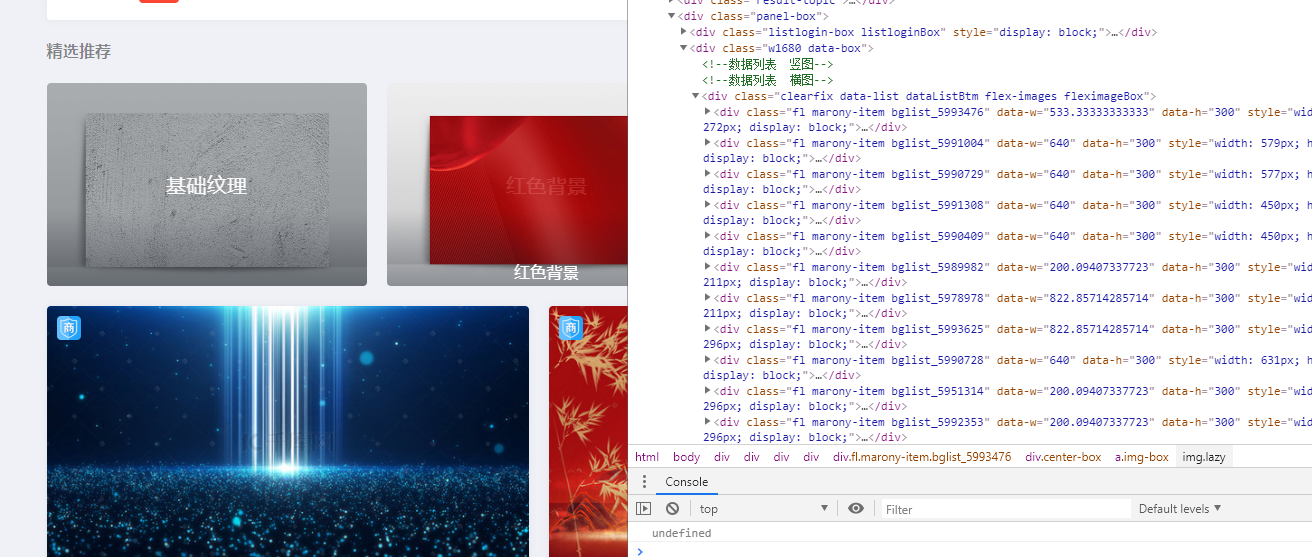
我们就可以获取里面的url
import requests
from bs4 import BeautifulSoup
import os
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'
}
html = requests.get('https://i588ku.com/beijing/0-0-default-0-8-0-0-0-0-1/',headers=headers)
soup = BeautifulSoup(html.text,'lxml')
Urlimags = soup.select('div.fl.marony-item div a')
for Urlimag in Urlimags:
print(Urlimag['href'])
输出结果为
//i588ku.com/ycbeijing/5993476.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5991004.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5990729.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5991308.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5990409.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5989982.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5978978.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5993625.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5990728.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5951314.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5992353.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5993626.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5992302.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5820069.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5804406.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5960482.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5881533.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5986104.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5956726.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5986063.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5978787.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5954475.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5959200.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5973667.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5850381.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5898111.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5924657.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5975496.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5928655.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5963925.html
//i588ku.com/comnew/vip/
这个/vip是广告,过滤一下
for Urlimag in Urlimags:
if 'vip' in Urlimag['href']:
continue
print('http:'+Urlimag['href'])
然后用os写入本地
import requests
from bs4 import BeautifulSoup
import os
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'
}
html = requests.get('https://i588ku.com/beijing/0-0-default-0-8-0-0-0-0-1/',headers=headers)
soup = BeautifulSoup(html.text,'lxml')
Urlimags = soup.select('div.fl.marony-item div a')
for Urlimag in Urlimags:
if 'vip' in Urlimag['href']:
continue
# print('http:'+Urlimag['href'])
imgurl = requests.get('http:'+Urlimag['href'],headers=headers)
imgsoup = BeautifulSoup(imgurl.text,'lxml')
imgdatas = imgsoup.select_one('.img-box img')
title = imgdatas['alt']
print('无水印:','https:'+imgdatas['src'])
if not os.path.exists('千图网图片'):
os.mkdir('千图网图片')
with open('千图网图片/{}.jpg'.format(title),'wb')as f:
f.write(requests.get('https:'+imgdatas['src'],headers=headers).content)
然后我们要下载多页,先看看url规则
第一页:https://i588ku.com/beijing/0-0-default-0-8-0-0-0-0-1/
第二页:https://i588ku.com/beijing/0-0-default-0-8-0-0-0-0-2/
import requests
from bs4 import BeautifulSoup
import os
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'
}
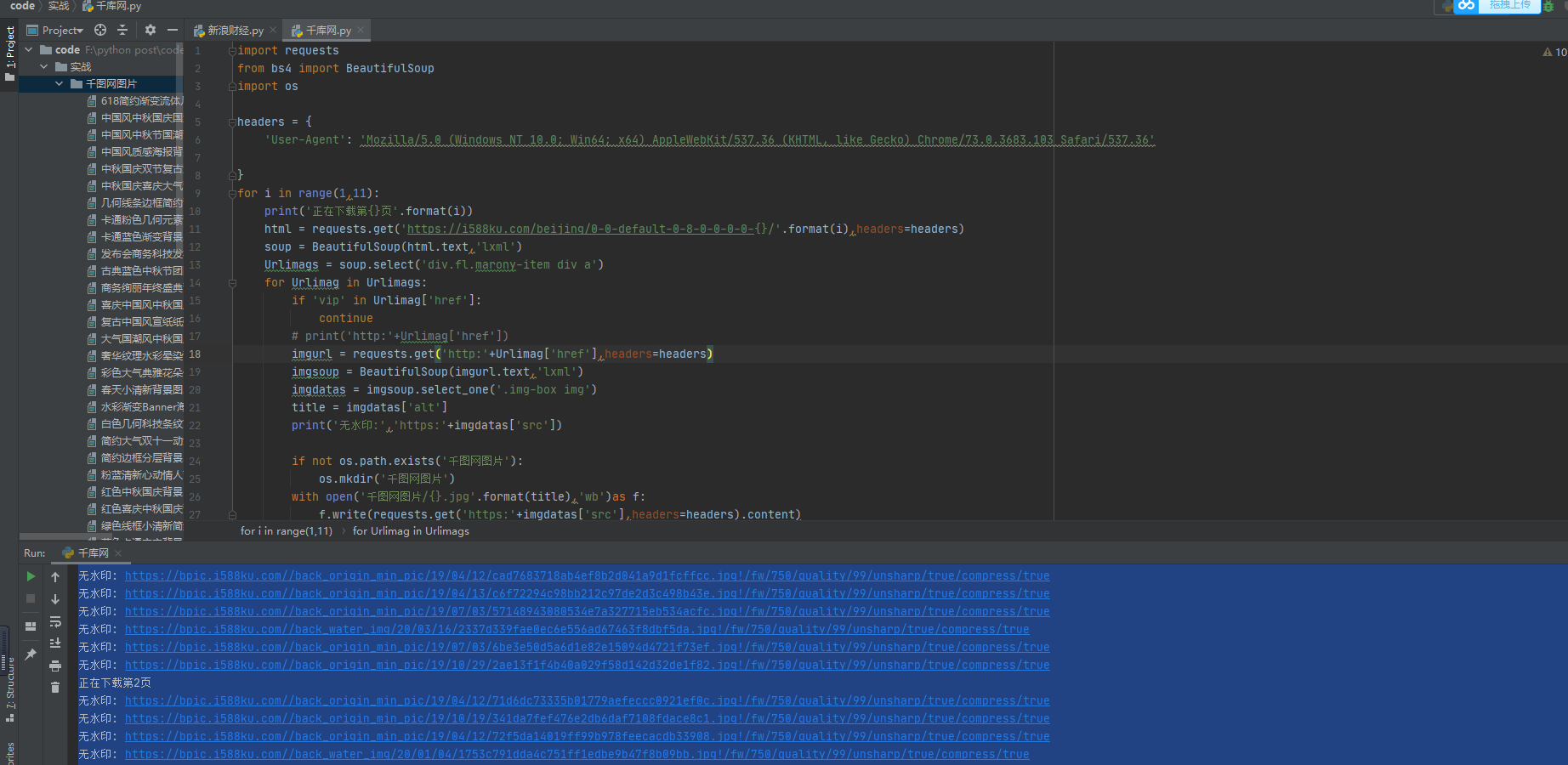
for i in range(1,11):
print('正在下载第{}页'.format(i))
html = requests.get('https://i588ku.com/beijing/0-0-default-0-8-0-0-0-0-{}/'.format(i),headers=headers)
soup = BeautifulSoup(html.text,'lxml')
Urlimags = soup.select('div.fl.marony-item div a')
for Urlimag in Urlimags:
if 'vip' in Urlimag['href']:
continue
# print('http:'+Urlimag['href'])
imgurl = requests.get('http:'+Urlimag['href'],headers=headers)
imgsoup = BeautifulSoup(imgurl.text,'lxml')
imgdatas = imgsoup.select_one('.img-box img')
title = imgdatas['alt']
print('无水印:','https:'+imgdatas['src'])
if not os.path.exists('千图网图片'):
os.mkdir('千图网图片')
with open('千图网图片/{}.jpg'.format(title),'wb')as f:
f.write(requests.get('https:'+imgdatas['src'],headers=headers).content)
python爬取千库网的更多相关文章
- Python爬取中国天气网
Python爬取中国天气网 基于requests库制作的爬虫. 使用方法:打开终端输入 “python3 weather.py 北京(或你所在的城市)" 程序正常运行需要在同文件夹下加入一个 ...
- python爬取天气后报网
前言 大二下学期的大数据技术导论课上由于需要获取数据进行分析,我决定学习python爬虫来获取数据.由于对于数据需求量相对较大,我最终选择爬取 天气后报网,该网站可以查询到全国各地多年的数据,而且相对 ...
- (python爬取小故事网并写入mysql)
前言: 这是一篇来自整理EVERNOTE的笔记所产生的小博客,实现功能主要为用广度优先算法爬取小故事网,爬满100个链接并写入mysql,虽然CS作为双学位已经修习了三年多了,但不仅理论知识一般,动手 ...
- Python爬取中国票房网所有电影片名和演员名字,爬取齐鲁网大陆所有电视剧名称
爬取CBO中国票房网所有电影片名和演员名字 # -*- coding: utf-8 -*- # 爬取CBO中国票房网所有电影片名 import json import requests import ...
- python爬取斗图网中的 “最新套图”和“最新表情”
1.分析斗图网 斗图网地址:http://www.doutula.com 网站的顶部有这两个部分: 先分析“最新套图” 发现地址栏变成了这个链接,我们在点击第二页 可见,每一页的地址栏只有后面的pag ...
- 适合初学者的Python爬取链家网教程
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: TinaLY PS:如有需要Python学习资料的小伙伴可以加点击下 ...
- Python 爬取煎蛋网妹子图片
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Date : 2017-08-24 10:17:28 # @Author : EnderZhou (z ...
- python爬取中国知网部分论文信息
爬取指定主题的论文,并以相关度排序. #!/usr/bin/python3 # -*- coding: utf-8 -*- import requests import linecache impor ...
- Python爬取17吉他网吉他谱
最近学习吉他,一张一张保存吉他谱太麻烦,写个小程序下载吉他谱. 安装 BeautifulSoup,BeautifulSoup是一个解析HTML的库.pip install BeautifulSoup4 ...
随机推荐
- mysql-STRAIGHT_JOIN-优化
性能提升神器-STRAIGHT_JOIN,在数据量大的联表查询中灵活运用的话,能大大缩短查询时间. 首先来解释下STRAIGHT_JOIN到底是用做什么的: STRAIGHT_JOIN is simi ...
- A Case for Lease-Based, Utilitarian Resource Management on Mobile Devices
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! 以下是对本文关键部分的摘抄翻译,详情请参见原文. Abstract 移动应用程序已经成为我们日常生活中不可或缺的一部分,但许多应用程序的设 ...
- instanceof判断问题
有时候我们根据instanceof来判断对象的数据类型 但是 用instanceof判断基本数据类型时 会不靠谱 例如 let str = '123' let str1 = new String(&q ...
- 超市管理系统C语言
登录系统 # include <stdio.h> //头文件 # include <string.h> //字符串头文件 # include <stdlib.h> ...
- 传统servelt项目之分页操作
需求说明: • 演示最终分页效果 • 提供分页素材 • 分页的作用 • 数据量大,一页容不下 • 后台查询部分数据而不是全部数据 • 降低带宽使用,提高访问速度 • 分页的实现思路 • ...
- 焦大:seo思维进化论(上)
http://www.wocaoseo.com/thread-51-1-1.html seo排名浮动一直是很多人关心的事情,但是背后的原理却一直很少被人知道.在seo是什么里说了seo的核心是什么,我 ...
- Labview学习之路(一)程序框图中的修饰
很多小伙伴知道在前面板有很多修饰符,比如上凸框,加粗下凹框等等,但是其实在程序框图中也是有修饰符的,他的位置比较隐蔽,并且修饰符很少,所以很多人基本没有用过.现在就给大家介绍一些这些程序框图种的修饰. ...
- unity 4种实现动态障碍方法
此文将介绍4种实现动态障碍的方法,2种基于navmesh,2种基于astar算法. 1.基于navmesh. 1.制作场景障碍: a.有几个独立的障碍物,就定义几个user area,即,一个场景仅仅 ...
- 面试【JAVA基础】集合类
1.ArrayList的扩容机制 每次扩容是原来容量的1.5倍,通过移位的方法实现. 使用copyOf的方式进行扩容. 扩容算法是首先获取到扩容前容器的大小.然后通过oldCapacity (oldC ...
- 使用Telnet服务测试端口时,提示没有Telnet服务
1.win7系统是默认不开启Telnet服务的,所以我们第一次使用时要手动开启Telnet服务 1)打开 控制面板 > 程序 > 程序功能 > 打开或关闭Windows功能,勾选上T ...