浅谈sql索引
索引是什么
假如你手上有一个你公司的客户表,老板说找什么客户你就得帮他找出来。
客户不多的时候,你拿着手指一行一行滑,费不了多少时间就能找到。
后来公司做大了,客户越来越多,好几页的客户,你发现,一行一行滑真的好累啊,最主要找慢了还得挨老板叼。
他妈的,吃力不讨好。
那咋办?
我相信这么聪明的你不会坐以待毙的。
你可能会自己做一些记录,比如拿个小本本写上,
28岁的客户在第一页
29岁的客户在第二页
或者
姓张的客户在第二页
姓李的客户在第三页和第四页
当然这些要根据那张客户表的实际情况来。
这样子,下次老板叫你找29岁的客户,你就一下子翻到第二页,一下子就找到了,轻松又漂亮地解决了问题。
这么机智地解决了问题,当上ceo,迎娶白富美就指日可待了。
好了,美好故事到此就结束了。
真实的情况是怎么样的呢?
真实的情况就是数据库就是故事中的你,你就是故事中的老板,故事中的小本本,就是咱们今天要讲的索引。
索引的特点
那么从这个故事中可以看出索引有什么特点呢?
为了提高查找效率而建立
如果你不给数据库加索引的话,多数情况下,它就真的是一行行找,效率极低。
数据量少的时候不需要索引
但数据量少的时候,也没必要建索引,你想想啊,数据量少的时候,你一下子就找到了,速度比你去翻小本本时间可能还要快点,就不要浪费一个小本本了。
MySQL的索引本质也是一张表的,建立索引也需要相应的空间。
索引是建立在表的数据上的
上面的故事里我也说了,小本本的内容要根据你表里的实际情况来的。
这样的话,如果建立了索引,就要注意两个点:
不要实际删除数据。
假如你有批客户闹掰了,你一生气,把客户表中那一整页都撕了。
那你下次按照【31岁的客户在第20页】这个规则去找,但是前面的就被你撕了,现在31岁的客户就提前了几页,你数到第20页,发现找不到,人都傻了。
MySQL也是这样的,如果删除数据,会导致按照索引查找的数据不会在原先的位置上。频繁更新的字段不要建立索引。
假设用户的年龄天天变,那最好也不要记在小本本上了,否则你每天都要去更新小本本,今天是【31岁的客户在第20页】,明天就要改成【32岁的客户在第20页】了。
MySQL也是这样的,如果建立索引的字段频繁更新,这样便会导致之前建立的索引需要频繁更新。
MySQL索引分类
人家MySQL建立索引的方式比我们记小本本的方式要聪明有效率地多了。
你可以看到我上面做小本本的方式都是根据表中的某一列来的,比如
【31岁的客户在第20页】这个是根据客户的年龄这一列来做的;
【姓李的客户在第三页和第四页】这个使用客户的名字这一列来做的。
在MySQL中,我们也只是需要告诉MySQL用哪些列来做索引即可,然后接下来的事他就会自己做。
咱们建立的索引呢,根据使用列的情况不同,可以分类如下:
单值索引:即一个索引只包含单个列。一个表可以有多个单列索引。
唯一索引:索引列的值必须唯一,但允许有空值。
复合索引:即一个索引包含多个列。
假如现在有一个people表,内有字段id(主键不需要做索引),name,age,phone_number(电话号码)那么:
- 单值索引:可以单独用name或age做一个索引,任何一个字段都可以。这样的索引可以做多个。
- 唯一索引:和单值索引一样,但做索引的该字段必须唯一,比如你确定people表中phone_number的值唯一的话,那么便可以在上面建立唯一索引。
- 复合索引:可以用(name,age)或(age,phone_number)或(name,age,phone_number)做一个索引。
建议:建立复合索引,且一个表不要超过5个索引。
基本语法
创建(如果加上UNIQUE则创建唯一索引):
CREATE [UNIQUE] INDEX indexName ON mytable(columnname(length));
或
ALTER mytable ADD [UNIQUE] INDEX[indexName] ON (columnname(length));删除:
DROP INDEX [indexName] ON mytable;查看:
SHOW INDEX FROM table\G
MySQL索引结构
就是上面的索引建立好后,这事虽然不用我们管,但也可以了解一下,MySQL是按照什么样的策略去查找数据的呢。
有几种结构,下面讲的是比较常用的BTree结构。
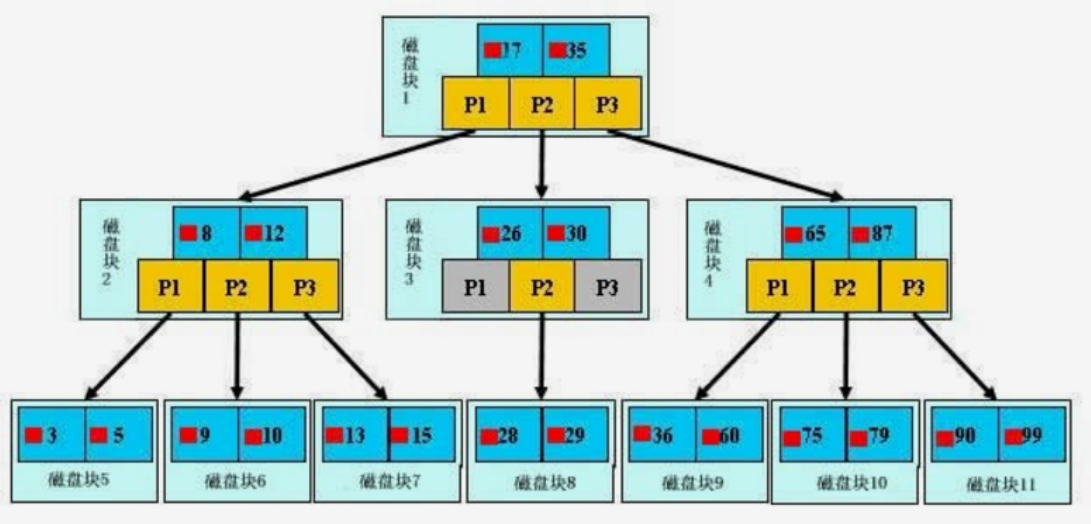
图片介绍:
如图一颗B+树,浅蓝色表示磁盘块,每个磁盘块包括几个数据项(深蓝色)和指针(黄色)。
如磁盘块1包括数据项17和35,包含指针P1、P2、P3;P1表示小于17的磁盘块,P2表示在17-35之间的磁盘块,P3表示大于35的磁盘块。
真实的数据只存在于叶子节点,非叶子节点不存储真实数据,只存储指引搜索方向的数据项。
如17、35并不真实存在数据表中。
查找过程(以上图查找数据项29):
首先把磁盘块1由磁盘加载到内存,此时发生一次IO;在内存中用二分查找确定29在17和35之间,锁定磁盘块1的P2指针,因为内存时间非常短(相比磁盘的IO)可以忽略不计。
将磁盘块1的P2指向的磁盘块3由磁盘加载到内存,发生第二次IO;确定29在26和30之间,指向磁盘块3的P2指针。
将磁盘块3的P2指针指向的磁盘块8加载到内存,发生第三次IO,同时内存中做二分查找找到29。
查询结束,总计三次IO。
真实的情况是:3层的B+树可以表示上百万的数据,如果上百万的数据查找只需要3次IO,性能提高将是巨大的,如果没有索引,每个数据项都要发生一次IO,那么总共需要上百万次IO。
总结:减少IO次数可以减少查询时间,提高性能,那么怎么减少IO次数?
答案:增加树的广度而非深度。B+树的叶子节点可以多。
建立索引的时机
哪些情况需要创建索引
- 主键自动建立唯一索引
- 频繁作为查询条件的字段应该创建索引
- 查询中与其他表关联的字段,外键关系建立索引
- 频繁更新的字段不适合创建索引 -- 因为每次更新不只更新记录还会更新索引
- Where里用不到的字段的不创建索引
- 单键/组合索引的选择问题 -- 在高并发下倾向创建组合索引
- 查询中排序的字段 -- 排序字段若通过索引去访问将大大提高排序速度
- 查询中统计或者分组字段
哪些情况不需要创建索引
- 表记录太少 -- mysql300w左右就可以考虑建索引了
- 经常增删改的表 -- 因为索引要跟着更新
- 数据重复且分布平均的表字段 -- 可以用(该字段不同的数据的数量)/(该字段总的数据量),值越接近1,说明不怎么重复,越有建索引的价值。
浅谈sql索引的更多相关文章
- 浅谈SQL优化入门:3、利用索引
0.写在前面的话 关于索引的内容本来是想写的,大概收集了下资料,发现并没有想象中的简单,又不想总结了,纠结了一下,决定就大概写点浅显的,好吧,就是懒,先挖个浅坑,以后再挖深一点.最基本的使用很简单,直 ...
- c#Winform程序调用app.config文件配置数据库连接字符串 SQL Server文章目录 浅谈SQL Server中统计对于查询的影响 有关索引的DMV SQL Server中的执行引擎入门 【译】表变量和临时表的比较 对于表列数据类型选择的一点思考 SQL Server复制入门(一)----复制简介 操作系统中的进程与线程
c#Winform程序调用app.config文件配置数据库连接字符串 你新建winform项目的时候,会有一个app.config的配置文件,写在里面的<connectionStrings n ...
- 转【】浅谈sql中的in与not in,exists与not exists的区别_
浅谈sql中的in与not in,exists与not exists的区别 1.in和exists in是把外表和内表作hash连接,而exists是对外表作loop循环,每次loop循环再对内表 ...
- 浅谈sql中的in与not in,exists与not exists的区别
转 浅谈sql中的in与not in,exists与not exists的区别 12月12日北京OSC源创会 —— 开源技术的年终盛典 » sql exists in 1.in和exists ...
- 浅谈SQL Server数据内部表现形式
在上篇文章 浅谈SQL Server内部运行机制 中,与大家分享了SQL Server内部运行机制,通过上次的分享,相信大家已经能解决如下几个问题: 1.SQL Server 体系结构由哪几部分组成? ...
- 浅谈SQL Server---2
浅谈SQL Server内部运行机制 https://www.cnblogs.com/wangjiming/p/10098061.html 对于已经很熟悉T-SQL的读者,或者对于较专业的DBA来说, ...
- 浅谈SQL Server---1
浅谈SQL Server优化要点 https://www.cnblogs.com/wangjiming/p/10123887.html 1.SQL Server 体系结构由哪几部分组成? 2.SQL ...
- 浅谈SQL注入风险 - 一个Login拿下Server
前两天,带着学生们学习了简单的ASP.NET MVC,通过ADO.NET方式连接数据库,实现增删改查. 可能有一部分学生提前预习过,在我写登录SQL的时候,他们鄙视我说:“老师你这SQL有注入,随便都 ...
- 浅谈sql 、linq、lambda 查询语句的区别
浅谈sql .linq.lambda 查询语句的区别 LINQ的书写格式如下: from 临时变量 in 集合对象或数据库对象 where 条件表达式 [order by条件] select 临时变量 ...
随机推荐
- 题解-CF802C Heidi and Library (hard)
题面 CF802C Heidi and Library (hard) 有一个大小为 \(k\) 的空书架.有 \(n\) 天和 \(n\) 种书,每天要求书架中有书 \(a_i\).每天可以多次买书, ...
- 笔记-CF643E Bear and Destroying Subtrees
CF643E Bear and Destroying Subtrees 设 \(f_{i,j}\) 表示节点 \(i\) 的子树深度为 \(\le j\) 的概率,\(ch_i\) 表示 \(i\) ...
- 120多套各种类别微信小程序模板源码打包下载
120多套各种类别微信小程序模板源码打包下载,以下是部分截图欢迎下载!120多套各种类别微信小程序模板源码打包下载 下载地址:https://pan.baidu.com/s/1Cfqyc9p2ZDOc ...
- sqli-labs less5-6(双查询注入)
less-5 双查询注入 利用count(), group by, floor(), rand()报错 双查询注入的原理参考博客 打开less-5 用union注入的流程进行发现页面不会有回显,所以u ...
- 1.pipeline原理
redis基本语法:https://www.cnblogs.com/xiaonq/p/7919111.html redis四篇:https://www.cnblogs.com/xiaonq/categ ...
- 浏览器小程序(Browser Applet)闪亮登场
2017 年 1 月 9 日,微信小程序横空出世.随后,支付宝小程序.今日头条小程序.百度智能小程序.360小程序等纷纷推出,自此国内软件功能扩展领域进入到了小程序时代,小程序为丰富其宿主软件的功能和 ...
- 浅析Python项目服务器部署
基础理论 关于Web服务器和应用服务器 基本概念: Web服务器主要功能就是存储.处理.传递网页,客户端和服务器之间基于HTTP协议进行通信. 应用服务器主要是处理动态请求,调用相应的对象完成对请求的 ...
- 精尽Spring MVC源码分析 - HandlerMapping 组件(四)之 AbstractUrlHandlerMapping
该系列文档是本人在学习 Spring MVC 的源码过程中总结下来的,可能对读者不太友好,请结合我的源码注释 Spring MVC 源码分析 GitHub 地址 进行阅读 Spring 版本:5.2. ...
- Missing Private key解决方案——IOS证书 .cer 以p12文件以及配置方案
一个苹果证书怎么多次使用--导出p12文件 为什么要导出.p12文件 因为苹果规定 .cer证书只能存在于一台机器上,因此 如果另一台电脑想要用的话,需要导出为.p12 file ,安装到另一台没有安 ...
- js 点击input焦点不弹出键盘 PDA扫描枪
直接贴代码 1.利用input readonly属性 当input有readonly属性的时候,即使获取焦点,也不会吊起小键盘 扫码枪输入的间隔大概在15-60毫秒,然后手动输入的100-200毫秒之 ...