MapReduce之GroupingComparator分组(辅助排序、二次排序)
指对Reduce阶段的数据根据某一个或几个字段进行分组。
案例
需求
有如下订单数据
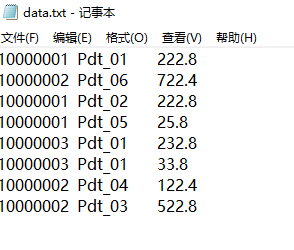
现在需要找出每一个订单中最贵的商品,如图

需求分析
利用“订单id和成交金额”作为
key,可以将Map阶段读取到的所有订单数据先按照订单id(升降序都可以),再按照acount(降序)排序,发送到Reduce。在Reduce端利用
groupingComparator将订单id相同的kv聚合成组,然后取第一个成交金额即是最大值(若有多个成交金额并排第一,则都输出)。Mapper阶段主要做三件事:
keyin-valuein
map()
keyout-valueout期待shuffle之后的数据:
10000001 Pdt_02 222.8
10000001 Pdt_01 222.8
10000001 Pdt_05 25.810000002 Pdt_06 722.4
10000002 Pdt_03 522.8
10000002 Pdt_04 122.410000003 Pdt_01 232.8
10000003 Pdt_01 33.8Reducer阶段主要做三件事:
keyin-valuein
reduce()
keyout-valueout进入Reduce需要考虑的事
- 获取分组比较器,如果没设置默认使用MapTask排序时key的比较器
- 默认的比较器比较策略不符合要求,它会将orderId一样且acount一样的记录才认为是一组的
- 自定义分组比较器,只按照orderId进行对比,只要OrderId一样,认为key相等,这样可以将orderId相同的分到一个组!
在组内去第一个最大的即可
编写程序
利用“订单id和成交金额”作为key,所以把每一行记录封装为bean。由于需要比较ID,所以实现了WritableComparable接口
OrderBean.java
public class OrderBean implements WritableComparable<OrderBean>{
private String orderId;
private String pId;
private Double acount;
public String getOrderId() {
return orderId;
}
public void setOrderId(String orderId) {
this.orderId = orderId;
}
public String getpId() {
return pId;
}
public void setpId(String pId) {
this.pId = pId;
}
public Double getAcount() {
return acount;
}
public void setAcount(Double acount) {
this.acount = acount;
}
public OrderBean() {
}
@Override
public String toString() {
return orderId + "\t" + pId + "\t" + acount ;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(orderId);
out.writeUTF(pId);
out.writeDouble(acount);
}
@Override
public void readFields(DataInput in) throws IOException {
orderId=in.readUTF();
pId=in.readUTF();
acount=in.readDouble();
}
// 二次排序,先按照orderid排序(升降序都可以),再按照acount(降序)排序
@Override
public int compareTo(OrderBean o) {
//先按照orderid排序升序排序
int result=this.orderId.compareTo(o.getOrderId());
if (result==0) {//订单ID相同,就比较成交金额的大小
//再按照acount(降序)排序
result=-this.acount.compareTo(o.getAcount());
}
return result;
}
}
自定义比较器,可以通过两种方法:
- 继承
WritableCompartor - 实现
RawComparator
MyGroupingComparator.java
//实现RawComparator
public class MyGroupingComparator implements RawComparator<OrderBean>{
private OrderBean key1=new OrderBean();
private OrderBean key2=new OrderBean();
private DataInputBuffer buffer=new DataInputBuffer();
@Override
public int compare(OrderBean o1, OrderBean o2) {
return o1.getOrderId().compareTo(o2.getOrderId());
}
@Override
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
try {
buffer.reset(b1, s1, l1); // parse key1
key1.readFields(buffer);
buffer.reset(b2, s2, l2); // parse key2
key2.readFields(buffer);
buffer.reset(null, 0, 0); // clean up reference
} catch (IOException e) {
throw new RuntimeException(e);
}
return compare(key1, key2);
}
}
MyGroupingComparator2.java
//继承WritableCompartor
public class MyGroupingComparator2 extends WritableComparator{
public MyGroupingComparator2() {
super(OrderBean.class,null,true);
}
public int compare(WritableComparable a, WritableComparable b) {
OrderBean o1=(OrderBean) a;
OrderBean o2=(OrderBean) b;
return o1.getOrderId().compareTo(o2.getOrderId());
}
}
OrderMapper.java
public class OrderMapper extends Mapper<LongWritable, Text, OrderBean, NullWritable>{
private OrderBean out_key=new OrderBean();
private NullWritable out_value=NullWritable.get();
@Override
protected void map(LongWritable key, Text value,
Mapper<LongWritable, Text, OrderBean, NullWritable>.Context context)
throws IOException, InterruptedException {
String[] words = value.toString().split("\t");
out_key.setOrderId(words[0]);
out_key.setpId(words[1]);
out_key.setAcount(Double.parseDouble(words[2]));
context.write(out_key, out_value);
}
}
OrderReducer.java
public class OrderReducer extends Reducer<OrderBean, NullWritable, OrderBean, NullWritable>{
/*
* OrderBean key-NullWritable nullWritable在reducer工作期间,
* 只会实例化一个key-value的对象!
* 每次调用迭代器迭代下个记录时,使用反序列化器从文件中或内存中读取下一个key-value数据的值,
* 封装到之前OrderBean key-NullWritable nullWritable在reducer的属性中
*/
@Override
protected void reduce(OrderBean key, Iterable<NullWritable> values,
Reducer<OrderBean, NullWritable, OrderBean, NullWritable>.Context context)
throws IOException, InterruptedException {
Double maxAcount = key.getAcount();
for (NullWritable nullWritable : values) {
if (!key.getAcount().equals(maxAcount)) {
break;
}
//复合条件的记录
context.write(key, nullWritable);
}
}
}
OrderBeanDriver.java
public class OrderBeanDriver {
public static void main(String[] args) throws Exception {
Path inputPath=new Path("E:\\mrinput\\groupcomparator");
Path outputPath=new Path("e:/mroutput/groupcomparator");
//作为整个Job的配置
Configuration conf = new Configuration();
//保证输出目录不存在
FileSystem fs=FileSystem.get(conf);
if (fs.exists(outputPath)) {
fs.delete(outputPath, true);
}
// ①创建Job
Job job = Job.getInstance(conf);
// ②设置Job
// 设置Job运行的Mapper,Reducer类型,Mapper,Reducer输出的key-value类型
job.setMapperClass(OrderMapper.class);
job.setReducerClass(OrderReducer.class);
// Job需要根据Mapper和Reducer输出的Key-value类型准备序列化器,通过序列化器对输出的key-value进行序列化和反序列化
// 如果Mapper和Reducer输出的Key-value类型一致,直接设置Job最终的输出类型
job.setOutputKeyClass(OrderBean.class);
job.setOutputValueClass(NullWritable.class);
// 设置输入目录和输出目录
FileInputFormat.setInputPaths(job, inputPath);
FileOutputFormat.setOutputPath(job, outputPath);
// 设置自定义的分组比较器
job.setGroupingComparatorClass(MyGroupingComparator2.class);
// ③运行Job
job.waitForCompletion(true);
}
}
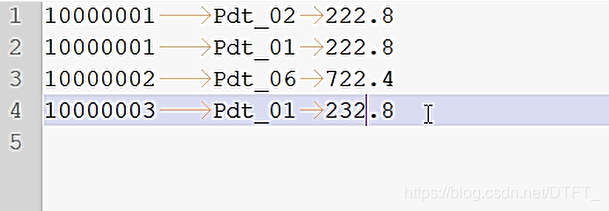
输出结果
MapReduce之GroupingComparator分组(辅助排序、二次排序)的更多相关文章
- mapreduce编程(一)-二次排序
转自:http://blog.csdn.net/heyutao007/article/details/5890103 mr自带的例子中的源码SecondarySort,我重新写了一下,基本没变. 这个 ...
- spark分组统计及二次排序案例一枚
组织数据形式: aa 11 bb 11 cc 34 aa 22 bb 67 cc 29 aa 36 bb 33 cc 30 aa 42 bb 44 cc 49 需求: 1.对上述数据按key值进行分组 ...
- Spark基础排序+二次排序(java+scala)
1.基础排序算法 sc.textFile()).reduceByKey(_+_,).map(pair=>(pair._2,pair._1)).sortByKey(false).map(pair= ...
- Hadoop MapReduce编程 API入门系列之二次排序(十六)
不多说,直接上代码. -- ::, INFO [org.apache.hadoop.metrics.jvm.JvmMetrics] - Initializing JVM Metrics with pr ...
- Hadoop MapReduce 二次排序原理及其应用
关于二次排序主要涉及到这么几个东西: 在0.20.0 以前使用的是 setPartitionerClass setOutputkeyComparatorClass setOutputValueGrou ...
- 详细讲解MapReduce二次排序过程
我在15年处理大数据的时候还都是使用MapReduce, 随着时间的推移, 计算工具的发展, 内存越来越便宜, 计算方式也有了极大的改变. 到现在再做大数据开发的好多同学都是直接使用spark, hi ...
- Haoop MapReduce 的Partition和reduce端的二次排序
先贴一张原理图(摘自hadoop权威指南第三版) 实际中看了半天还是不太理解其中的Partition,和reduce端的二次排序,最终根据实验来结果来验证自己的理解 1eg 数据如下 20140101 ...
- Hadoop案例(八)辅助排序和二次排序案例(GroupingComparator)
辅助排序和二次排序案例(GroupingComparator) 1.需求 有如下订单数据 订单id 商品id 成交金额 0000001 Pdt_01 222.8 0000001 Pdt_05 25.8 ...
- Hadoop Mapreduce分区、分组、二次排序过程详解[转]
原文地址:Hadoop Mapreduce分区.分组.二次排序过程详解[转]作者: 徐海蛟 教学用途 1.MapReduce中数据流动 (1)最简单的过程: map - reduce (2) ...
随机推荐
- C++敲代码前的准备工作
#pragma GCC target("avx,sse2,sse3,sse4,popcnt") #pragma GCC optimize("O2,Ofast,inline ...
- python 爬虫写入txt:UnicodeEncodeError: ‘gbk’ codec can’t encode character 错误的解决办法
原链接:https://blog.csdn.net/vito21/article/details/53490435 今天爬一个网站的内容,在写入TXT文件时,某些页面总是报UnicodeEncodeE ...
- 数据可视化之powerBI技巧(十)利用度量值,轻松进行动态指标分析
在一个图表中,可以将多项指标数据放进去同时显示,如果不想同时显示在一起,可以根据需要动态显示数据吗?在 PowerBI 中当然是可以的. 下面就看看如何利用度量值进行动态分析. 假如要分析的指标有销售 ...
- python爬虫学习01--电子书爬取
python爬虫学习01--电子书爬取 1.获取网页信息 import requests #导入requests库 ''' 获取网页信息 ''' if __name__ == '__main__': ...
- Visual SVN Server+TortoiseSVN进行源代码管理
安装VisualSVN Server 安装完之后,可配置SVN Server的IP地址,右键下图红色部分,选择属性,然后可配置ServeName和IP Address 之后可以创建用户.用户组和项目库 ...
- 09-Python异常
一.简介 在实际的工作过程中,我们会遇到各种问题,比如文件不存在,代码运行不符合某些特定逻辑等,程序在运行时,遇到这些问题便会发生异常.英文是Exception. a = float(input('请 ...
- 【高性能Mysql 】读书笔记(一)
第1章 Mysql架构与历史 MYSQL最重要.最与众不同的特性是它的存储引擎架构,这种架构的设计将查询处理( Query Processing)及其他系统任务( Server Task)和数据的存储 ...
- 洛谷P2365/5785 任务安排 题解 斜率优化DP
任务安排1(小数据):https://www.luogu.com.cn/problem/P2365 任务安排2(大数据):https://www.luogu.com.cn/problem/P5785 ...
- elementUI 级联选择框 表单验证
今天遇到了一个需求:进行级联选择框的表单验证,突然有点懵逼.感觉应该和正常的表单验证类似,但不是很清晰,后来还是在博客园找到了相关参考文章. 先上代码: <el-form :model=&quo ...
- Vue使用定时器定时刷新页面
1. 需求说明 在前端开发中,往往会遇到页面需要实时刷新数据的情况,给用户最新的数据展示. 2. 逻辑分析 如果需要数据实时更新,我们自然是需要使用定时器,不断的调用接口数据,会相对的消耗内存. 3. ...