RNN 入门教程 Part 3 – 介绍 BPTT 算法和梯度消失问题
转载 - Recurrent Neural Networks Tutorial, Part 3 – Backpropagation Through Time and Vanishing Gradients
本文是 RNN入门教程 的第三部分.
In the previous part of the tutorial we implemented a RNN from scratch, but didn’t go into detail on how Backpropagation Through Time (BPTT) algorithms calculates the gradients. In this part we’ll give a brief overview of BPTT and explain how it differs from traditional backpropagation. We will then try to understand the vanishing gradient problem, which has led to the development of LSTMs and GRUs, two of the currently most popular and powerful models used in NLP (and other areas). The vanishing gradient problem was originally discovered by Sepp Hochreiter in 1991 and has been receiving attention again recently due to the increased application of deep architectures.
To fully understand this part of the tutorial I recommend being familiar with how partial differentiation and basic backpropagation works. If you are not, you can find excellent tutorials here and here and here, in order of increasing difficulty.
Backpropagation Through Time (BPTT)
Let’s quickly recap the basic equations of our RNN. Note that there’s a slight change in notation from $o$ to $\hat{y}$. That’s only to stay consistent with some of the literature out there that I am referencing.
\[\begin{aligned} s_t &= \tanh(Ux_t + Ws_{t-1}) \\ \hat{y}_t &= \mathrm{softmax}(Vs_t) \end{aligned} \]
We also defined our loss, or error, to be the cross entropy loss, given by:
\[\begin{aligned} E_t(y_t, \hat{y}_t) &= - y_{t} \log \hat{y}_{t} \\ E(y, \hat{y}) &=\sum\limits_{t} E_t(y_t,\hat{y}_t) \\ & = -\sum\limits_{t} y_{t} \log \hat{y}_{t} \end{aligned} \]
Here, $y_t$ is the correct word at time step $t$, and $\hat{y_t}$ is our prediction. We typically treat the full sequence (sentence) as one training example, so the total error is just the sum of the errors at each time step (word).
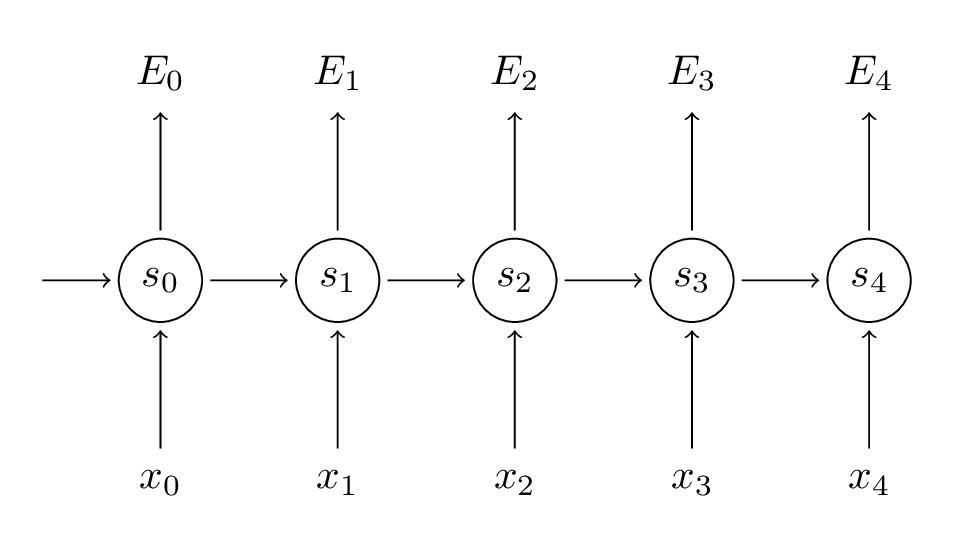
Remember that our goal is to calculate the gradients of the error with respect to our parameters $U,V$ and $W$ and then learn good parameters using Stochastic Gradient Descent. Just like we sum up the errors, we also sum up the gradients at each time step for one training example: $\frac{\partial E}{\partial W} = \sum\limits_{t} \frac{\partial E_t}{\partial W}$.
To calculate these gradients we use the chain rule of differentiation. That’s the backpropagation algorithm when applied backwards starting from the error. For the rest of this post we’ll use $E_3$ as an example, just to have concrete numbers to work with.
\[\begin{aligned} \frac{\partial E_3}{\partial V} &=\frac{\partial E_3}{\partial \hat{y}_3}\frac{\partial\hat{y}_3}{\partial V}\\ &=\frac{\partial E_3}{\partial \hat{y}_3}\frac{\partial\hat{y}_3}{\partial z_3}\frac{\partial z_3}{\partial V}\\ &=(\hat{y}_3 - y_3) \otimes s_3 \\ \end{aligned} \]
In the above, $z_3=Vs_3$, and $\otimes $ is the outer product of two vectors. Don’t worry if you don’t follow the above, I skipped several steps and you can try calculating these derivatives yourself (good exercise!). The point I’m trying to get across is that $\frac{\partial E_3}{\partial V} $ only depends on the values at the current time step, $\hat{y}_3, y_3, s_3 $. If you have these, calculating the gradient for $V$ a simple matrix multiplication.
But the story is different for $\frac{\partial E_3}{\partial W}$ (and for $U$). To see why, we write out the chain rule, just as above:
\[\begin{aligned} \frac{\partial E_3}{\partial W} &= \frac{\partial E_3}{\partial \hat{y}_3}\frac{\partial\hat{y}_3}{\partial s_3}\frac{\partial s_3}{\partial W}\\ \end{aligned} \]
Now, note that $s_3 = \tanh(Ux_t + Ws_2)$ depends on $s_2$, which depends on $W$ and $s_1$, and so on. So if we take the derivative with respect to $W$ we can’t simply treat $s_2$ as a constant! We need to apply the chain rule again and what we really have is this:
\[\begin{aligned} \frac{\partial E_3}{\partial W} &= \sum\limits_{k=0}^{3} \frac{\partial E_3}{\partial \hat{y}_3}\frac{\partial\hat{y}_3}{\partial s_3}\frac{\partial s_3}{\partial s_k}\frac{\partial s_k}{\partial W}\\ \end{aligned} \]
We sum up the contributions of each time step to the gradient. In other words, because $W$ is used in every step up to the output we care about, we need to backpropagate gradients from $t=3$ through the network all the way to $t=0$:
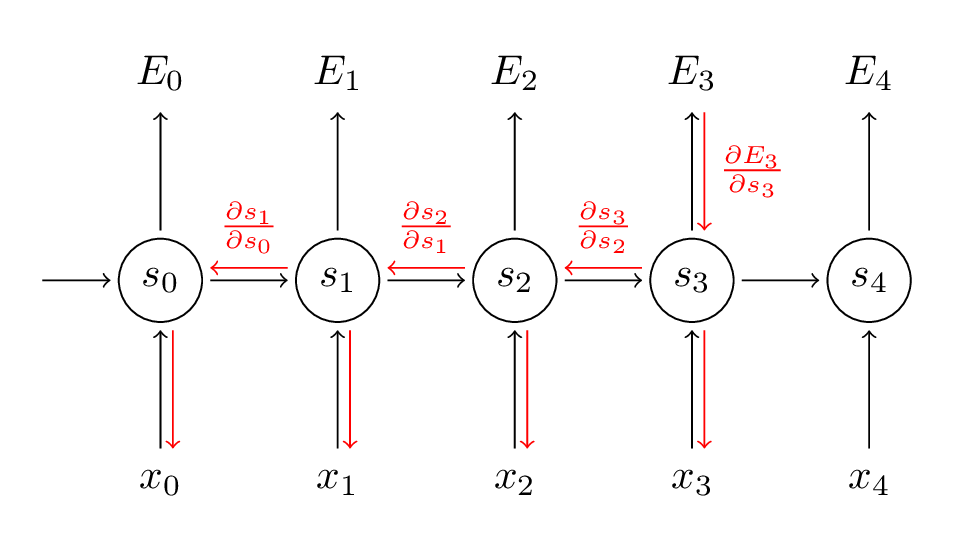
Note that this is exactly the same as the standard backpropagation algorithm that we use in deep Feedforward Neural Networks. The key difference is that we sum up the gradients for $W$at each time step. In a traditional NN we don’t share parameters across layers, so we don’t need to sum anything. But in my opinion BPTT is just a fancy name for standard backpropagation on an unrolled RNN. Just like with Backpropagation you could define a delta vector that you pass backwards, e.g.: $\delta_2^{(3)} = \frac{\partial E_3}{\partial z_2} =\frac{\partial E_3}{\partial s_3}\frac{\partial s_3}{\partial s_2}\frac{\partial s_2}{\partial z_2}$ with $z_2 = Ux_2+ Ws_1$. Then the same equations will apply.
In code, a naive implementation of BPTT looks something like this:
def bptt(self, x, y):
T = len(y)
# Perform forward propagation
o, s = self.forward_propagation(x)
# We accumulate the gradients in these variables
dLdU = np.zeros(self.U.shape)
dLdV = np.zeros(self.V.shape)
dLdW = np.zeros(self.W.shape)
delta_o = o
delta_o[np.arange(len(y)), y] -= 1.
# For each output backwards...
for t in np.arange(T)[::-1]:
dLdV += np.outer(delta_o[t], s[t].T)
# Initial delta calculation: dL/dz
delta_t = self.V.T.dot(delta_o[t]) * (1 - (s[t] ** 2))
# Backpropagation through time (for at most self.bptt_truncate steps)
for bptt_step in np.arange(max(0, t-self.bptt_truncate), t+1)[::-1]:
# print "Backpropagation step t=%d bptt step=%d " % (t, bptt_step)
# Add to gradients at each previous step
dLdW += np.outer(delta_t, s[bptt_step-1])
dLdU[:,x[bptt_step]] += delta_t
# Update delta for next step dL/dz at t-1
delta_t = self.W.T.dot(delta_t) * (1 - s[bptt_step-1] ** 2)
return [dLdU, dLdV, dLdW]
This should also give you an idea of why standard RNNs are hard to train: Sequences (sentences) can be quite long, perhaps 20 words or more, and thus you need to back-propagate through many layers. In practice many people truncate the backpropagation to a few steps.
The Vanishing Gradient Problem
In previous parts of the tutorial I mentioned that RNNs have difficulties learning long-range dependencies – interactions between words that are several steps apart. That’s problematic because the meaning of an English sentence is often determined by words that aren’t very close: “The man who wore a wig on his head went inside”. The sentence is really about a man going inside, not about the wig. But it’s unlikely that a plain RNN would be able capture such information. To understand why, let’s take a closer look at the gradient we calculated above:
\[\begin{aligned} \frac{\partial E_3}{\partial W} &= \sum\limits_{k=0}^{3} \frac{\partial E_3}{\partial \hat{y}_3}\frac{\partial\hat{y}_3}{\partial s_3}\frac{\partial s_3}{\partial s_k}\frac{\partial s_k}{\partial W}\\ \end{aligned} \]
Note that $\frac{\partial s_3}{\partial s_k} $ is a chain rule in itself! For example, $\frac{\partial s_3}{\partial s_1} =\frac{\partial s_3}{\partial s_2}\frac{\partial s_2}{\partial s_1}$. Also note that because we are taking the derivative of a vector function with respect to a vector, the result is a matrix (called theJacobian matrix) whose elements are all the pointwise derivatives. We can rewrite the above gradient:
\[\begin{aligned} \frac{\partial E_3}{\partial W} &= \sum\limits_{k=0}^{3} \frac{\partial E_3}{\partial \hat{y}_3}\frac{\partial\hat{y}_3}{\partial s_3} \left(\prod\limits_{j=k+1}^{3} \frac{\partial s_j}{\partial s_{j-1}}\right) \frac{\partial s_k}{\partial W}\\ \end{aligned} \]
It turns out (I won’t prove it here but this paper goes into detail) that the 2-norm, which you can think of it as an absolute value, of the above Jacobian matrix has an upper bound of 1. This makes intuitive sense because our $\tanh$ (or sigmoid) activation function maps all values into a range between -1 and 1, and the derivative is bounded by 1 (1/4 in the case of sigmoid) as well:
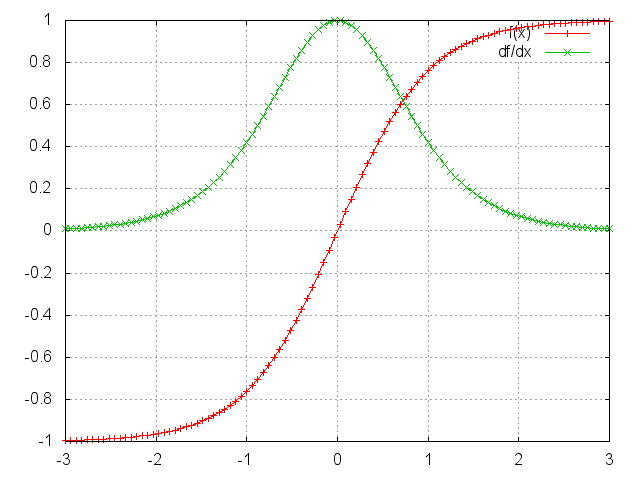
tanh and derivative.
You can see that the $\tanh$ and sigmoid functions have derivatives of 0 at both ends. They approach a flat line. When this happens we say the corresponding neurons are saturated. They have a zero gradient and drive other gradients in previous layers towards 0. Thus, with small values in the matrix and multiple matrix multiplications ($t-k$ in particular) the gradient values are shrinking exponentially fast, eventually vanishing completely after a few time steps. Gradient contributions from “far away” steps become zero, and the state at those steps doesn’t contribute to what you are learning: You end up not learning long-range dependencies. Vanishing gradients aren’t exclusive to RNNs. They also happen in deep Feedforward Neural Networks. It’s just that RNNs tend to be very deep (as deep as the sentence length in our case), which makes the problem a lot more common.
It is easy to imagine that, depending on our activation functions and network parameters, we could get exploding instead of vanishing gradients if the values of the Jacobian matrix are large. Indeed, that’s called the exploding gradient problem. The reason that vanishing gradients have received more attention than exploding gradients is two-fold. For one, exploding gradients are obvious. Your gradients will become NaN (not a number) and your program will crash. Secondly, clipping the gradients at a pre-defined threshold (as discussed in this paper) is a very simple and effective solution to exploding gradients. Vanishing gradients are more problematic because it’s not obvious when they occur or how to deal with them.
Fortunately, there are a few ways to combat the vanishing gradient problem. Proper initialization of the $W$ matrix can reduce the effect of vanishing gradients. So can regularization. A more preferred solution is to use ReLU instead of $\tanh$ or sigmoid activation functions. The ReLU derivative isn’t bounded by 1, so it isn’t as likely to suffer from vanishing gradients. An even more popular solution is to use Long Short-Term Memory (LSTM) or Gated Recurrent Unit (GRU) architectures. LSTMs were first proposed in 1997 and are the perhaps most widely used models in NLP today. GRUs, first proposed in 2014, are simplified versions of LSTMs. Both of these RNN architectures were explicitly designed to deal with vanishing gradients and efficiently learn long-range dependencies. We’ll cover them in the next part of this tutorial.
RNN 入门教程 Part 3 – 介绍 BPTT 算法和梯度消失问题的更多相关文章
- Recurrent Neural Network系列3--理解RNN的BPTT算法和梯度消失
作者:zhbzz2007 出处:http://www.cnblogs.com/zhbzz2007 欢迎转载,也请保留这段声明.谢谢! 这是RNN教程的第三部分. 在前面的教程中,我们从头实现了一个循环 ...
- RNN 入门教程 Part 1 – RNN 简介
转载 - Recurrent Neural Networks Tutorial, Part 1 – Introduction to RNNs Recurrent Neural Networks (RN ...
- VB6 GDI+ 入门教程[1] GDI+介绍
http://vistaswx.com/blog/article/category/tutorial/page/2 VB6 GDI+ 入门教程[1] GDI+介绍 2009 年 6 月 18 日 17 ...
- ASP.NET MVC4 新手入门教程之一 ---1.介绍ASP.NET MVC4
你会建造 您将实现一个简单的电影清单应用程序支持创建. 编辑. 搜索和清单数据库中的电影.下面是您将构建的应用程序的两个屏幕截图.它包括显示来自数据库的电影列表的网页: 应用程序还允许您添加. 编辑和 ...
- RNN 入门教程 Part 2 – 使用 numpy 和 theano 分别实现RNN模型
转载 - Recurrent Neural Networks Tutorial, Part 2 – Implementing a RNN with Python, Numpy and Theano 本 ...
- RNN 入门教程 Part 4 – 实现 RNN-LSTM 和 GRU 模型
转载 - Recurrent Neural Network Tutorial, Part 4 – Implementing a GRU/LSTM RNN with Python and Theano ...
- TensorFlow 实现 RNN 入门教程
转子:https://www.leiphone.com/news/201705/zW49Eo8YfYu9K03J.html 最近在看RNN模型,为简单起见,本篇就以简单的二进制序列作为训练数据,而不实 ...
- JavaScript 入门教程一 开篇介绍
一.JavaScript 刚开始是为了解决一些由服务器端进行的验证而开发的前端语言.在宽带还不普及的90年代,当用户辛苦输入很多信息并提交给服务器后,等了漫长的时间,等到的不是提交成功的提示而是某些必 ...
- gitbook 入门教程之插件介绍
插件是 gitbook 的扩展功能,很多炫酷有用的功能都是通过插件完成的,其中插件有官方插件和第三方插件之分. 推荐官方插件市场 https://plugins.gitbook.com/ 寻找或下载相 ...
随机推荐
- Resharper快捷键
建议你使用 Reshaper 的快捷键,不要担心 Reshaper 会把你原来的快捷键设置给覆盖了,因为如果某个快捷键和 VS 是冲突的,Reshaper会让你自己选择需要使用 VS 还是 Resha ...
- 彻底明白IP地址——IP地址的介绍
彻底明白IP地址——IP地址的介绍 [ 作者:担子 转贴自:赛迪网 点击数:9692 更新时间:2004-12-22 ] IP地址的介绍 1.IP地址的表示方法 IP地址 = ...
- 东大oj-1511: Caoshen like math
Worfzyq likes Permutation problems.Caoshen and Mengjuju are expert at these problems . They have n c ...
- stack 栈的实现
今天晚上去「南哪」听了场AI的讲座,除了话筒真心不给力之外,算是对微软这方面的进展有了更多了解,毕竟是半宣传性质的活动吧. 光听这些是没用的,眼下还是打好基础,多尝试学点新技术,拓宽能力和视野比较重要 ...
- 【jQuery EasyUI系列】使用属性介绍
1.ValidateBox The validatebox is designed to validate the form input fields.If users enter invalid v ...
- 59-chown 简明笔记
改变文件的所有者或与文件相关联的组 chown [options] owner file-list chown [options] owner: group file-list chown [opti ...
- C#中快速释放内存,任务管理器可查证
先close() 再dispose() 之后=null 最后GC.Collect() 如: ms.Close();//关闭流,并释放与之相关的资源 ms.Dispose();//如果是流的话,默认只会 ...
- linux 下第一个cordova android app
上篇博客写了linux下 cordova + ionic 环境的搭建 , 今天就来做下第一个app的简单讲解吧 首先昨天已经可以通过命令行的方式创建app了.经过今天好一段时间的研究发现使用 ioni ...
- Android下常见的四种对话框
摘要:在实际开发过程有时为了能够和用户进行很好的交互,需要使用到对话框,在Android中常用的对话框有四种:普通对话框.单选对话框.多选对话框.进度对话框. 一.普度对话框 public void ...
- json写入和读取代码
#写入new文件 import json dic = {'name':'alex'} i = 8 s = 'hello' l = [11,22] f = open("new_hello&qu ...