Dropout原理与实现
Dropout是深度学习中的一种防止过拟合手段,在面试中也经常会被问到,因此有必要搞懂其原理。
1 Dropout的运作方式
在神经网络的训练过程中,对于一次迭代中的某一层神经网络,先随机选择中的一些神经元并将其临时隐藏(丢弃),然后再进行本次训练和优化。在下一次迭代中,继续随机隐藏一些神经元,如此直至训练结束。由于是随机丢弃,故而每一个mini-batch都在训练不同的网络。
在训练时,每个神经单元以概率$p$被保留(Dropout丢弃率为$1-p$);在预测阶段(测试阶段),每个神经单元都是存在的,权重参数$w$要乘以$p$,输出是:$pw$。示意图如下:
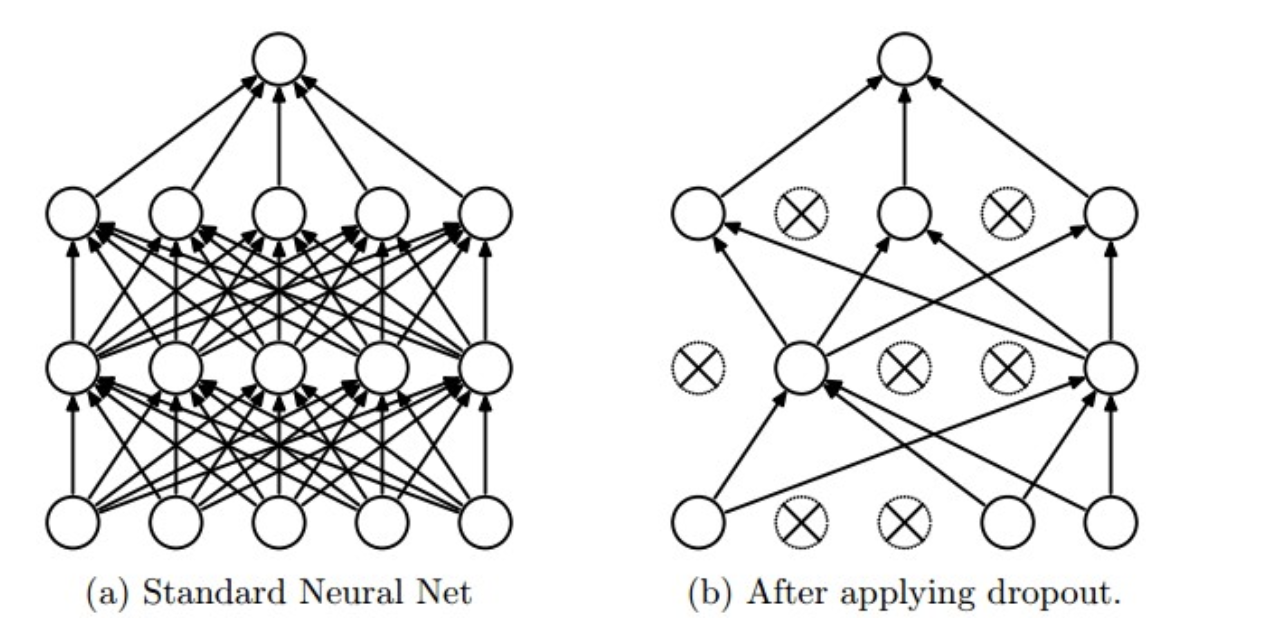
预测阶段需要乘上$p$的原因:
前一层隐藏层的一个神经元在$dropout$之前的输出是$x$,训练时$dropout$之后的期望值是$E=px+(1−p) \dot 0$; 在预测阶段该层神经元总是激活,为了保持同样的输出期望值并使下一层也得到同样的结果,需要调整$x->px$. 其中$p$是Bernoulli分布(0-1分布)中值为1的概率。
2 Dropout 实现
如前文所述,在训练时随机隐藏部分神经元,在预测时必须要乘上p。代码如下:
import numpy as np p = 0.5 # 神经元激活概率 def train_step(X):
""" X contains the data """ # 三层神经网络前向传播为例
H1 = np.maximum(0, np.dot(W1, X) + b1)
U1 = np.random.rand(*H1.shape) < p # first dropout mask
H1 *= U1 # drop!
H2 = np.maximum(0, np.dot(W2, H1) + b2)
U2 = np.random.rand(*H2.shape) < p # second dropout mask
H2 *= U2 # drop!
out = np.dot(W3, H2) + b3 def predict(X):
# ensembled forward pass
H1 = np.maximum(0, np.dot(W1, X) + b1) * p # NOTE: scale the activations
H2 = np.maximum(0, np.dot(W2, H1) + b2) * p # NOTE: scale the activations
out = np.dot(W3, H2) + b3
3 反向Dropout
一个略有不同的方法是使用反向Dropout(Inverted Dropout)。该方法包括在训练阶段缩放激活函数,从而使得其测试阶段保持不变。比例因子是保持概率的倒数即$1/p$。所以我们换一个思路,在训练时候对数据进行1/p缩放,在训练时,就不需要做什么了。
反向Dropout只定义一次模型并且只改变了一个参数(保持/丢弃概率)以使用同一模型进行训练和测试。相反,直接Dropout,必须要在测试阶段修改网络。因为如果你不乘以比例因子p,神经网络的输出将产生更高的相对于连续神经元所期望的值(因此神经元可能饱和):因此反向Dropout是更加常见的实现方式。代码如下:
p = 0.5 # probability of keeping a unit active. higher = less dropout def train_step(X):
# forward pass for example 3-layer neural network
H1 = np.maximum(0, np.dot(W1, X) + b1)
U1 = (np.random.rand(*H1.shape) < p) / p # first dropout mask. Notice /p!
H1 *= U1 # drop!
H2 = np.maximum(0, np.dot(W2, H1) + b2)
U2 = (np.random.rand(*H2.shape) < p) / p # second dropout mask. Notice /p!
H2 *= U2 # drop!
out = np.dot(W3, H2) + b3 # backward pass: compute gradients... (not shown)
# perform parameter update... (not shown) def predict(X):
# ensembled forward pass
H1 = np.maximum(0, np.dot(W1, X) + b1) # no scaling necessary
H2 = np.maximum(0, np.dot(W2, H1) + b2)
out = np.dot(W3, H2) + b3
4 Dropout为什么可以防止过拟合?
(1)取平均的作用
先回到标准的模型即没有dropout,我们用相同的训练数据去训练5个不同的神经网络,一般会得到5个不同的结果,此时我们可以采用 “5个结果取均值”或者“多数取胜的投票策略”去决定最终结果。例如3个网络判断结果为数字9,那么很有可能真正的结果就是数字9,其它两个网络给出了错误结果。这种“综合起来取平均”的策略通常可以有效防止过拟合问题。因为不同的网络可能产生不同的过拟合,取平均则有可能让一些“相反的”拟合互相抵消。dropout掉不同的隐藏神经元就类似在训练不同的网络,随机删掉一半隐藏神经元导致网络结构已经不同,整个dropout过程就相当于对很多个不同的神经网络取平均。而不同的网络产生不同的过拟合,一些互为“反向”的拟合相互抵消就可以达到整体上减少过拟合。
(2)减少神经元之间复杂的共适应关系
用作者原话是“在标准神经网络中,每个参数接收的导数表明其应该如何变化才能使最终损失函数降低,并给定所有其它神经网络单元的状态。因此神经单元可能以一种可以修正其它神经网络单元的错误的方式进行改变。而这就可能导致复杂的共适应(co-adaptations)。由于这些共适应现象没有推广到未见的数据,将导致过拟合。我们假设对每个隐藏层的神经网络单元,Dropout通过使其它隐藏层神经网络单元不可靠从而阻止了共适应的发生。因此,一个隐藏层神经元不能依赖其它特定神经元去纠正其错误。”
因为dropout程序导致两个神经元不一定每次都在一个dropout网络中出现。这样权值的更新不再依赖于有固定关系的隐含节点的共同作用,阻止了某些特征仅仅在其它特定特征下才有效果的情况 。迫使网络去学习更加鲁棒的特征 ,这些特征在其它的神经元的随机子集中也存在。换句话说假如我们的神经网络是在做出某种预测,它不应该对一些特定的线索片段太过敏感,即使丢失特定的线索,它也应该可以从众多其它线索中学习一些共同的特征。从这个角度看dropout就有点像L1,L2正则,减少权重使得网络对丢失特定神经元连接的鲁棒性提高。
(3)Dropout类似于性别在生物进化中的角色
物种为了生存往往会倾向于适应这种环境,环境突变则会导致物种难以做出及时反应,性别的出现可以繁衍出适应新环境的变种,有效的阻止过拟合,即避免环境改变时物种可能面临的灭绝。
5 参考
1 http://cs231n.github.io/neural-networks-2/#reg
2 http://jmlr.org/papers/volume15/srivastava14a.old/srivastava14a.pdf
Dropout原理与实现的更多相关文章
- 深度学习中Dropout原理解析
1. Dropout简介 1.1 Dropout出现的原因 在机器学习的模型中,如果模型的参数太多,而训练样本又太少,训练出来的模型很容易产生过拟合的现象. 在训练神经网络的时候经常会遇到过拟合的问题 ...
- Dropout原理解析
1. Dropout简介 1.1 Dropout出现的原因 在机器学习的模型中,如果模型的参数太多,而训练样本又太少,训练出来的模型很容易产生过拟合的现象.在训练神经网络的时候经常会遇到过拟合的问题, ...
- Hebye 深度学习中Dropout原理解析
1. Dropout简介 1.1 Dropout出现的原因 在机器学习的模型中,如果模型的参数太多,而训练样本又太少,训练出来的模型很容易产生过拟合的现象. 在训练神经网络的时候经常会遇到过拟合的问题 ...
- Dropout原理分析
工作流程 dropout用于解决过拟合,通过在每个batch中删除某些节点(cell)进行训练,从而提高模型训练的效果. 通过随机化一个伯努利分布,然后于输入y进行乘法,将对应位置的cell置零.然后 ...
- 神经网络之dropout层
一:引言 因为在机器学习的一些模型中,如果模型的参数太多,而训练样本又太少的话,这样训练出来的模型很容易产生过拟合现象.在训练bp网络时经常遇到的一个问题,过拟合指的是模型在训练数据上损失函数比较小, ...
- TensorFlow学习---tf.nn.dropout防止过拟合
一. Dropout原理简述: tf.nn.dropout是TensorFlow里面为了防止或减轻过拟合而使用的函数,它一般用在全连接层. Dropout就是在不同的训练过程中随机扔掉一部分神经元.也 ...
- 深度学习基础系列(九)| Dropout VS Batch Normalization? 是时候放弃Dropout了
Dropout是过去几年非常流行的正则化技术,可有效防止过拟合的发生.但从深度学习的发展趋势看,Batch Normalizaton(简称BN)正在逐步取代Dropout技术,特别是在卷积层.本文将首 ...
- caffe dropout解读
先上caffe dropout_layer.cpp源码,如下: // LayerSetUp DCHECK(threshold_ > 0.); DCHECK(threshold_ < 1.) ...
- Task5.PyTorch实现L1,L2正则化以及Dropout
1.了解知道Dropout原理 深度学习网路中,参数多,可能出现过拟合及费时问题.为了解决这一问题,通过实验,在2012年,Hinton在其论文<Improving neural network ...
随机推荐
- Mysql高手系列 - 第5天:DML操作汇总,确定你都会?
这是Mysql系列第5篇. 环境:mysql5.7.25,cmd命令中进行演示. DML(Data Manipulation Language)数据操作语言,以INSERT.UPDATE.DELETE ...
- CF990C Bracket Sequences Concatenation Problem 思维 第五道 括号经典处理题目
Bracket Sequences Concatenation Problem time limit per test 2 seconds memory limit per test 256 meg ...
- 蚂蚁SOFA系列(1) - 聊聊SOFA的模块化
作者:404,转载请注明出处.欢迎关注公众号:404P. SOFA是蚂蚁自研的一套金融级分布式中间件,目前正在逐步向业界开源.SOFA的全称有两个,最早是Service Oriented Fabric ...
- Wannafly挑战赛16---A 取石子
链接:https://www.nowcoder.com/acm/contest/113/A来源:牛客网 时间限制:C/C++ 1秒,其他语言2秒空间限制:C/C++ 262144K,其他语言52428 ...
- Cookie与Seesion的作用
1.什么是Cookie与Session? cookie:首次访问服务器,服务器返回cookie置浏览器,存到用户电脑.之后去访问同一服务器,浏览器会携带相应cookie判断是否是同一浏览器的访问,告知 ...
- Myeclipse项目工程目录中各种Libraries的含义
MyEclipse工程目录下一般会有以下几类Libraries,如图: 各种Libraries的含义如下: JRE System Library:Java SE 的常用库文件集合,构建任何Java项目 ...
- idea控制台乱码解决方案
第一步:修改intellij idea配置文件: 找到intellij idea安装目录,bin文件夹下面idea64.exe.vmoptions和idea.exe.vmoptions这两个文件,分别 ...
- OkHttp3使用教程,实现get、post请求发送,自动重试,打印响应日志。
一.创建线程安全的okhttp单例 import service.NetworkIntercepter;import service.RetryIntercepter;import okhttp3.* ...
- TestNG(四) 基本注解BeforeSuite和AfterSuite
package com.course.testng; import org.testng.annotations.*; public class BasicAnnotation { @Test //最 ...
- mysql 函数 存取过程
1.打开数据库 2.选择函数,点击新建函数,选择过程,点击完成 4.写入自己要添加的sql语句 5.点击CTAL + S 保存,如若报错则语法或函数错误