写论文的第一天 hadoop环境搭建
毕设日志_____2019.1.23
实验集群环境搭建
三台阿里云服务器
|
公网ip |
内网ip |
|
120.79.63.130 node2 |
172.17.17.58 |
|
112.74.50.240 主节点master |
172.17.17.79 |
|
39.108.232.147 node1 |
172.16.50.183 |
通过filezilla上传 jdk1.8.01_192.tar.gz 以及hadoop.2.6.0.tar.gz到主节点
下载Xshell作为远程连接工具
1:更改名称
用Xshell连接三台服务器 分别修改其主机名为 master node1 node2 对应服务器表格
命令如下 vim /etc/hostname
2:修改主机映射
Vim /etc/hosts
在原有文件上增加
120.79.63.130 node2
112.74.50.240 master
39.108.232.147 node1
通过scp将映射文件复制到子节点并且覆盖原有文件
命令:scp /etc/hosts node1:/etc/hosts
scp /etc/hosts node2:/etc/hosts
3:ssh免密
主节点执行命令 ssh-keygen –t rsa 产生公共密钥 一直回车会将公钥默认保存到~/.ssh/id_rsa.pub中
命令:ssh-copy-id -i node1
ssh-copy-id -i node2
将公钥导入到node1和node2中 来实现master到子节点的免密
命令:cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
将master密钥导入到本地 实现本地ssh免密登陆
4:jdk安装
将filezilla传到主节点的jdk压缩包解压
命令: tar –zxf ./jdk1.8.0_192 /usr/local 解压到/usr/local目录
配置JAVA_HOME
命令: vim /etc/profile
进入文件增加如下
#set JAVA_HOME
export JAVA_HOME=/usr/local/jdk1.8.0_192
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
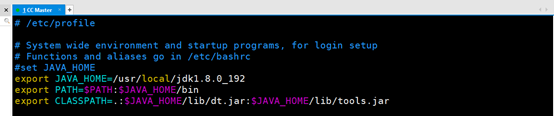
保存并且退出 执行命令: source /etc/profile使配置生效
通过在端口键入 java –version查看是否安装并且配置成功
至此配置jdk成功

将jdk传到两个子节点上并且配置JAVA_HOME 步骤如上
命令:scp –r /usr/local/jdk1.8.0_192 node1:/usr/local/
scp –r /usr/local/jdk1.8.0_192 node2:/usr/local/
5:hadoop安装
在主节点将hadoop2.6.0的压缩包解压
命令: tar –zxf ./hadoop2.6.0.tar.gz /usr/local/
解压到/usr/local目录下生成hadoop.2.6.0
为了以后方便使用 改名为hadoop
命令:mv ./hadoop.2.6.0 ./hadoop
配置主节点hadoop中的core-site.xml hdfs-site.xml yarn-site.xml mapred-site.xml
配置如下
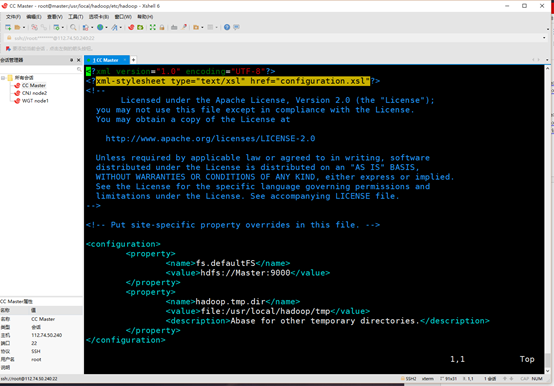
在core-site.xml中增加
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
</configuration>
在hdfs-site.xml中增加
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
在yarn-site.xml中增加
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
将mapred-site.xml.template复制一份为mapred-site.xml.并增加
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>Master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>Master:19888</value>
</property>
</configuration>
主节点搭建完毕 复制到两个子节点
命令: scp /usr/local/hadoop node1:/usr/local
scp /usr/local/hadoop node2:/usr/local
检测集群是否搭建成功 为了方便以后使用为hadoop配置PATH
命令: vim /etc/profile
#set HADOOP_HOME
export PATH=$PATH:/usr/local/hadoop/bin:/usr/local/hadoop/sbin

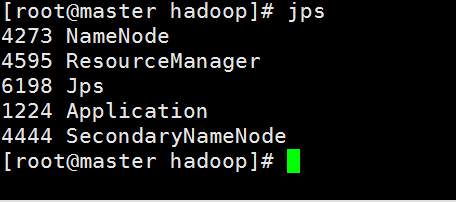
开始测试hadoop集群是否搭建成功
命令: start-all.sh
查看主节点进程
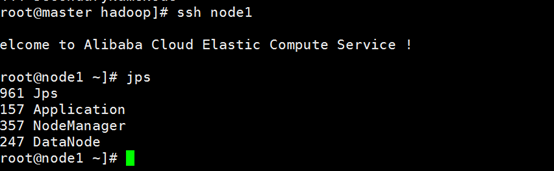
查看node1进程
查看node2进程

所有进程启动正常 Hadoop集群配置成功
注意:在使用Xshell时可以粘贴复制配置文件,但是在linux中,hadoop集群启动时会对core-site.xml hdfs-site.xml 等等进行解析
这里要注意在copy的时候在xml文件的开始行有默认的xml注释,表明这是该xml文件的版本以及编码格式。这个标明前面不要有任何其他内容(空格 空行都不行)否则启动hadoop集群的时候会出现解析错误从而导致hadoop集群启动失败。
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
写论文的第一天 hadoop环境搭建的更多相关文章
- 【转】RHadoop实践系列之一:Hadoop环境搭建
RHadoop实践系列之一:Hadoop环境搭建 RHadoop实践系列文章,包含了R语言与Hadoop结合进行海量数据分析.Hadoop主要用来存储海量数据,R语言完成MapReduce 算法,用来 ...
- 转 史上最详细的Hadoop环境搭建
GitChat 作者:鸣宇淳 原文:史上最详细的Hadoop环境搭建 关注公众号:GitChat 技术杂谈,一本正经的讲技术 [不要错过文末活动哦] 前言 Hadoop在大数据技术体系中的地位至关重要 ...
- hadoop环境搭建之关于NAT模式静态IP的设置 ---VMware12+CentOs7
很久没有更新了,主要是没有时间,今天挤出时间验证了一下,果然还是有些问题的,不过已经解决了,就发上来吧. PS:小豆腐看仔细了哦~ 关于hadoop环境搭建,从单机模式,到伪分布式,再到完全分布式,我 ...
- eclipse工具下hadoop环境搭建
eclipse工具下hadoop环境搭建: window10操作系统中搭建eclipse64开发系统,配置hadoop的eclipse插件,让eclipse可以查看Hdfs中的文件内容. ...
- 大数据学习之Hadoop环境搭建
一.Hadoop的优势 1)高可靠性:因为Hadoop假设计算元素和存储会出现故障,因为它维护多个工作数据副本,在出现故障时可以对失败的节点重新分布处理. 2)高扩展性:在集群间分配任务数据,可方便的 ...
- Hadoop环境搭建、启动和管理界面查看
一.hadoop环境搭建: 1. hadoop 6个核心配置文件的作用:core-site.xml:核心配置文件,主要定义了我们文件访问的格式 hdfs://hadoop-env.sh:主要配置我们的 ...
- Ubuntu中Hadoop环境搭建
Ubuntu中Hadoop环境搭建 JDK安装 方法一:通过命令行直接安装(不建议) 有两种java可以安装oracle-java8-installer以及openjdk (1)安装oracle-ja ...
- Linux集群搭建与Hadoop环境搭建
今天是8月19日,距离开学还有15天,假期作业完成还是遥遥无期,看来开学之前的恶补是躲不过了 今天总结一下在Linux环境下安装Hadoop的过程,首先是对Linux环境的配置,设置主机名称,网络设置 ...
- Hadoop环境搭建(centos)
Hadoop环境搭建(centos) 本平台密码83953588abc 配置Java环境 下载JDK(本实验从/cgsrc 文件中复制到指定目录) mkdir /usr/local/java cp / ...
随机推荐
- java学习笔记(基础篇)—抽象与接口的区别
抽象与接口的区别 一.抽象(abstract) 1. 抽象方法 1) 作用:定义规范 2) 抽象方法用来描述具有什么功能,但不提供实现. 3) 如果类中一个方法没有实现就要定义一个抽象方法. 2. 抽 ...
- 精美的在线icon
super-tiny-icons(0.2.1)列表 序号 名称 图标 地址 是否使用 1 acast.svg https://cdn.jsdelivr.net/npm/super-tiny-icons ...
- 创建 gif
1.动态创建 <Container name="layLoading"/> if (m_pLoadingGif == NULL) { m_pLoadingGif ...
- xpath路径的写法
关于xpath路径的写法 1.选取节点 表达式 描述 nodename 选取此节点的所有子节点. / 从根节点选取. // 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置. . 选取当前节点 ...
- NameNode和SecondaryNameNode的工作机制
NameNode&Secondary NameNode 工作机制 NameNode: 1.启动时,加载编辑日志和镜像文件到内存 2.当客户端对元数据进行增删改,请求NameNode 3.Nam ...
- [leetcode] 7. Reverse Integer (easy)
原题 水题 唯一注意的点就是数字溢出 class Solution { public: int reverse(int x) { long long MAX = ((long long)1 <& ...
- laravel5.6 使用迁移创建表
laravel 使用迁移创建表 创建迁移文件 --table 和 --create 选项可以用于指定表名以及该迁移是否要创建一个新的数据表.这些选项只需要简单放在上述迁移命令后面并指定表名: php ...
- sysctl -p详解
个人一般sysctl -p 或sysctl -a比较多使用 sysctl配置与显示在/proc/sys目录中的内核参数.可以用sysctl来设置或重新设置联网功能,如IP转发.IP碎片去除以及源路由检 ...
- Spring 整合 ibatis
是的,真的是那个不好用的ibatis,不是好用的mybatis. 由于工作需要用到ibatis需要自己搭建环境,遇到了不少的坑,做一下记录. 一.环境配置 Maven JDK1.6 (非常重要,使用S ...
- 在 dotnet core (C#)下的颜色渐变
直接使用等比例抽样算法,连同透明度一起计算. public IList<Color> ShadeColors(Color c1, Color c2, int resultCount) { ...