遍历二叉树 - 基于队列的BFS
之前学过利用递归实现BFS二叉树搜索(http://www.cnblogs.com/webor2006/p/7262773.html),这次学习利用队列(Queue)来实现,关于什么时BFS这里不多说了,先贴张图来直观回忆下:
实现一个队列【采用数组实现】:
这时同样采用模版技术可以往队列中去放任何类型的数据,而这个队列同样是声明在头文件中,以便在需要用到队列的地方去随时包含它,下面先来定个初步框架:
/**
* 利用数组来实现队列
*/ template <typename T> class queue
{
T* data;//用数组来实现队列
int head/* 头指向的位置 */, tail/* 尾指向的位置 */, size/* 当前队列存放的元素个数 */, data_length/* 总队列的大小 */;
public:
queue(int length):head(), tail(), size(), data_length(length) {
data = new T[length];
} //入队列
void push(T value) { } //出队列
void pop() { } //取出队列最早的元素
T top() { } //判断队列是否为空
bool isEmpty() { }
};
具体实现如下:
/**
* 利用数组来实现队列
*/ template <typename T> class queue
{
T* data;//用数组来实现队列
int head/* 头指向的位置 */, tail/* 尾指向的位置 */, size/* 当前队列存放的元素个数 */, data_length/* 总队列的大小 */;
public:
queue(int length):head(), tail(), size(), data_length(length) {
data = new T[length];
} //入队列
void push(T value) {
if(size == data_length) {
throw "queue is full";//如果队列已经满了则直接抛异常,实际可以去将数组扩容,这里简单处理,重在学习数据结构
}
data[head] = value;
head = (head + ) % data_length;//这是为了循环利用,如果队列还有空间的话
size++;
} //出队列
void pop() {
if(isEmpty()) {
throw "queue is empty";
}
tail = (tail + ) % data_length;//这是为了循环利用
size--;
} //取出队列最早的元素
T top() {
if(isEmpty())
throw "You cannot get the top element from an empty queue";
return data[tail];
} //判断队列是否为空
bool isEmpty() {
return size == ;
}
};
这里先来使用一下它,看入队跟出队的结果是否如预期:
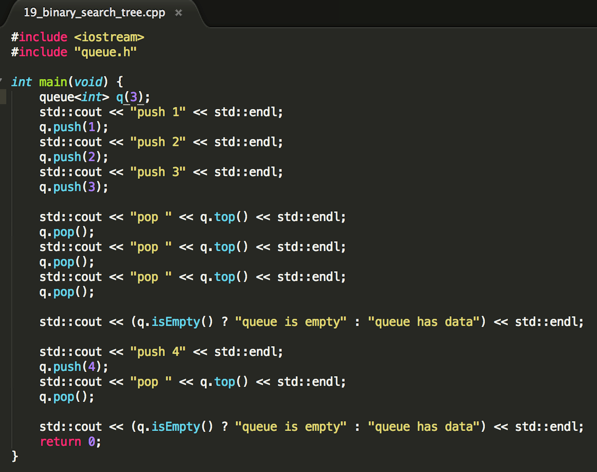
编译运行:

对于上面的写法下面用图来将其整个过程画出来:
①、
创建一个大小为3的队列,其中head、tail指向数组0的位置,其中目前是一个size=0空数组

②、
往队列中插入元素1:
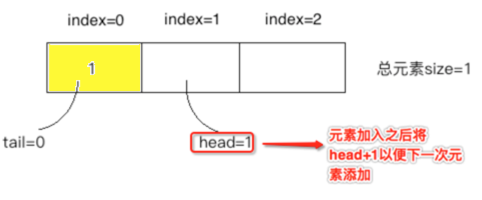
③、
往队列中插入元素2:
④、
往队列中插入元素3,这里需要注意啦!!!head会循环利用,指向数组0的位置:

⑤、
根据队列先进先出的原则拿最早放入的元素也就是tail所指向的元素:

⑥、
根据队列先进先出的原则拿最早放入的元素也就是tail所指向的元素:
⑦、
根据队列先进先出的原则拿最早放入的元素也就是tail所指向的元素:
这时注意啦!!!tail跟head一样也会循环利用,又回到index=0的位置了:

⑧、
由于此时size=0了,所以会打印出"queue is empty"。
⑨、
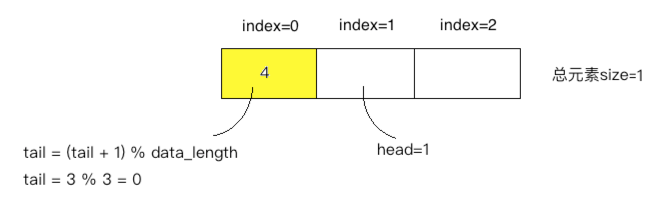
⑩、
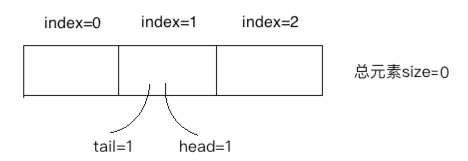
⑪、
由于此时size=0了,所以会打印出"queue is empty"。
总结:
1、添加元素放到head处,添加完成之后将head+1以便下次进行存放。
2、拿元素时是从tail处拿,拿完之后也是将tail+1以便拿下一个元素,因为是先进先出原则。
基于上节的实现来利用队列实现二叉树的BFS遍历:
先贴一下上节的代码,基于这个二叉树利用队列去实现:
#include <iostream>
#include "stack.h"
#include "queue.h" //用来表示二叉树
struct treenode{
int data;
treenode* left;//左结点
treenode* right;//右结点
treenode(int value):data(value), left(nullptr), right(nullptr){}
}; //前序遍历
void pre_order(treenode* root){
Stack<treenode*> stack;//声明一个栈
treenode* current_node = root;
while(current_node) {
//1、首先打印当前结点,因为是前序遍历
std::cout << current_node->data << std::endl;
//2、如果存在右结点则将其入栈暂存,待左结点输出完之后再去处理这些右结点
if(current_node->right) stack.push(current_node->right);
//3、不断去处理左结点,直到左结点处理完了,则从栈中拿右点进行处理
if(current_node->left)//如果有左结点,则将它做为当前处理的结点不断输出
current_node = current_node->left;
else {
//这时左结点已经处理完了
if(stack.isEmpty())//如果缓存栈已经为空了则说明整个二叉树的遍历结束了
current_node = nullptr;
else {
//则取出栈顶的右结点进行处理,由于是后进先出,所以拿出来的永远是最新插入的右结点
current_node = stack.top();
stack.pop();//将其元素从栈顶弹出
} }
}
} //利用队列实现BFS
void level_order(treenode* root){
//TODO
} int main(void) { //构建二叉树:
//1、第一层根结点
treenode* root = new treenode();
//2、第二层结点
root->left = new treenode();
root->right = new treenode();
//3、第三层结点
root->left->left = new treenode();
root->left->right = new treenode();
root->right->left = new treenode();
//4、第四层结点
root->right->left->left = new treenode(); pre_order(root); std::cout << "##################" << std::endl; level_order(root); return ;
}
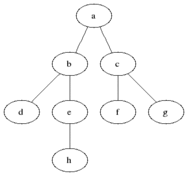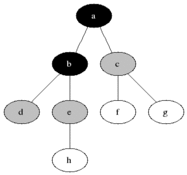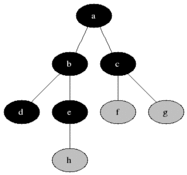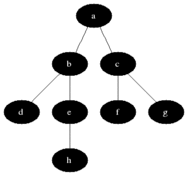
其二叉树为: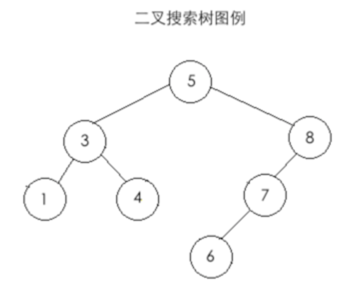
下面具体来实现level_order:
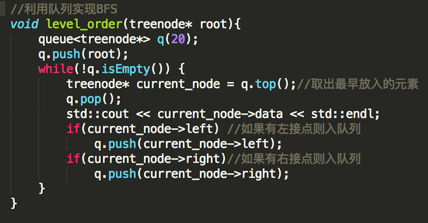
只要理解的队列的先进先出的特点上面的实现比较容易理解,不多解释,编译运行:

下面看一下它的时间复杂度:由于队列中有多少元素就会遍历多次次,所以很明显是O(n)。
遍历二叉树 - 基于队列的BFS的更多相关文章
- 遍历二叉树 - 基于栈的DFS
之前已经学过二叉树的DFS的遍历算法[http://www.cnblogs.com/webor2006/p/7244499.html],当时是基于递归来实现的,这次利用栈不用递归也来实现DFS的遍历, ...
- 遍历二叉树 - 基于递归的DFS(前序,中序,后序)
上节中已经学会了如何构建一个二叉搜索数,这次来学习下树的打印-基于递归的DFS,那什么是DFS呢? 有个概念就行,而它又分为前序.中序.后序三种遍历方式,这个也是在面试中经常会被问到的,下面来具体学习 ...
- java二叉树遍历——深度优先(DFS)与广度优先(BFS) 递归版与非递归版
介绍 深度优先遍历:从根节点出发,沿着左子树方向进行纵向遍历,直到找到叶子节点为止.然后回溯到前一个节点,进行右子树节点的遍历,直到遍历完所有可达节点为止. 广度优先遍历:从根节点出发,在横向遍历二叉 ...
- 基于循环队列的BFS的原理及实现
文章首发于微信公众号:几何思维 1.故事起源 有一只蚂蚁出去寻找食物,无意中进入了一个迷宫.蚂蚁只能向上.下.左.右4个方向走,迷宫中有墙和水的地方都无法通行.这时蚂蚁犯难了,怎样才能找出到食物的最短 ...
- 基于visual Studio2013解决面试题之0401非递归遍历二叉树
题目
- 基于递归的BFS(Level-order)
上篇中学习了二叉树的DFS深度优先搜索算法,这次学习另外一种二叉树的搜索算法:BFS,下面看一下它的概念: 有些抽象是不?下面看下整个的遍历过程的动画演示就晓得是咋回事啦: 了解其概念之后,下面看下如 ...
- UVa 122 Trees on the level (动态建树 && 层序遍历二叉树)
题意 :输入一棵二叉树,你的任务是按从上到下.从左到右的顺序输出各个结点的值.每个结 点都按照从根结点到它的移动序列给出(L表示左,R表示右).在输入中,每个结点的左 括号和右括号之间没有空格,相邻 ...
- Java遍历二叉树深度宽度
节点数据结构 class TreeNode { TreeNode left = null; TreeNode right = null; } 最大深度,基本思路是:使用递归,分别求出左子树的深度.右子 ...
- PHP遍历二叉树
遍历二叉树,这个相对比较复杂. 二叉树的便利,主要有两种,一种是广度优先遍历,一种是深度优先遍历. 什么是广度优先遍历?就是根节点进入,水平一行一行的便利. 什么是深度优先遍历呢?就是根节点进入,然后 ...
随机推荐
- php display_errors
// 检测开发环境 public function setReporting() { if (APP_DEBUG === true) { error_reporting(E_ALL); ini_set ...
- MSSQL 获取数据库、表、字段信息语句
--获取所有数据库名称 SELECT Name FROM Master..SysDatabases ORDER BY Name --获取库里所有表名 SELECT * FROM SysObjects ...
- 自己对flash memory的总结
1.综述类文章 1.A Survey of Storage Management in Flash based Data 2.Understanding the Flash Translation L ...
- Reactor系列(六)Exception异常系列(六)Exception异常
#java##reactor##flux##error##exception# 视频解说: https://www.bilibili.com/video/av79468713/ FluxMonoTes ...
- 《MIT 6.828 Lab 1 Exercise 4》实验报告
本实验链接:mit 6.828 lab1 Exercise 4. 题目 Exercise 4. Read about programming with pointers in C. The best ...
- [转帖]电源ac和dc有什么区别_dc ac分别代表什么
电源ac和dc有什么区别_dc ac分别代表什么 发表于 2017-10-28 17:18:58 电源设计应用 +关注 http://m.elecfans.com/article/571712.htm ...
- SpringBoot起步
1.SpringBoot依赖包导入 方式一:将spring-boot的依赖为父pom出现 <parent> <groupId>org.springframework.boot& ...
- 什么是DataV数据可视化
DataV数据可视化是使用可视化大屏的方式来分析并展示庞杂数据的产品.DataV旨让更多的人看到数据可视化的魅力,帮助非专业的工程师通过图形化的界面轻松搭建专业水准的可视化应用,满足您会议展览.业务监 ...
- LC 599. Minimum Index Sum of Two Lists
题目描述 Suppose Andy and Doris want to choose a restaurant for dinner, and they both have a list of fav ...
- easyUI datagrid 刷新取消加载信息 自动刷新闪屏问题
<style type="text/css"> /*-- 消除grid屏闪问题 --//*/ .datagrid-mask { opacity: 0; filter: ...