Introduction to Restricted Boltzmann Machines
转载,原贴地址:Introduction to Restricted Boltzmann Machines,by Edwin Chen, 2011/07/18.
Suppose you ask a bunch of users to rate a set of movies on a 0-100 scale. In classical factor analysis, you could then try to explain each movie and user in terms of a set of latent factors. For example, movies like Star Wars and Lord of the Rings might have strong associations with a latent science fiction and fantasy factor, and users who like Wall-E and Toy Story might have strong associations with a latent Pixar factor.
Restricted Boltzmann Machines essentially perform a binary version of factor analysis. (This is one way of thinking about RBMs; there are, of course, others, and lots of different ways to use RBMs, but I’ll adopt this approach for this post.) Instead of users rating a set of movies on a continuous scale, they simply tell you whether they like a movie or not, and the RBM will try to discover latent factors that can explain the activation of these movie choices.
More technically, a Restricted Boltzmann Machine is a stochastic neural network (neural network meaning we have neuron-like units whose binary activations depend on the neighbors they’re connected to; stochastic meaning these activations have a probabilistic element) consisting of:
- One layer of visible units (users’ movie preferences whose states we know and set);
- One layer of hidden units (the latent factors we try to learn); and
- A bias unit (whose state is always on, and is a way of adjusting for the different inherent popularities of each movie).
Furthermore, each visible unit is connected to all the hidden units (this connection is undirected, so each hidden unit is also connected to all the visible units), and the bias unit is connected to all the visible units and all the hidden units. To make learning easier, we restrict the network so that no visible unit is connected to any other visible unit and no hidden unit is connected to any other hidden unit.
For example, suppose we have a set of six movies (Harry Potter, Avatar, LOTR 3, Gladiator, Titanic, and Glitter) and we ask users to tell us which ones they want to watch. If we want to learn two latent units underlying movie preferences – for example, two natural groups in our set of six movies appear to be SF/fantasy (containing Harry Potter, Avatar, and LOTR 3) and Oscar winners (containing LOTR 3, Gladiator, and Titanic), so we might hope that our latent units will correspond to these categories – then our RBM would look like the following:
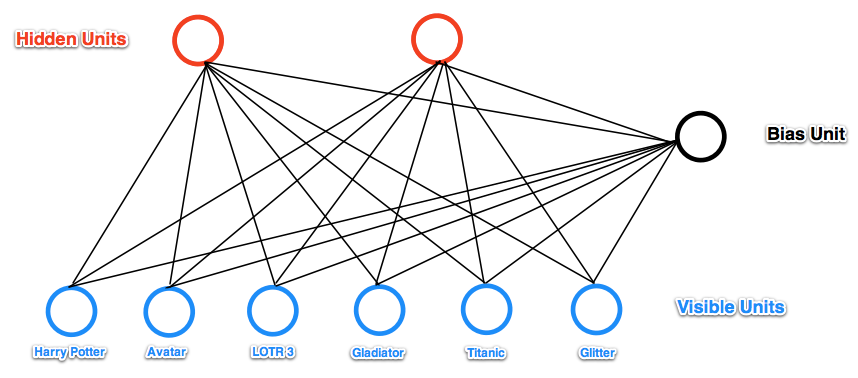
(Note the resemblance to a factor analysis graphical model.)
State Activation
Restricted Boltzmann Machines, and neural networks in general, work by updating the states of some neurons given the states of others, so let’s talk about how the states of individual units change. Assuming we know the connection weights in our RBM (we’ll explain how to learn these below), to update the state of unit i :

For example, let’s suppose our two hidden units really do correspond to SF/fantasy and Oscar winners.
- If Alice has told us her six binary preferences on our set of movies, we could then ask our RBM which of the hidden units her preferences activate (i.e., ask the RBM to explain her preferences in terms of latent factors). So the six movies send messages to the hidden units, telling them to update themselves. (Note that even if Alice has declared she wants to watch Harry Potter, Avatar, and LOTR 3, this doesn’t guarantee that the SF/fantasy hidden unit will turn on, but only that it will turn on with high probability. This makes a bit of sense: in the real world, Alice wanting to watch all three of those movies makes us highly suspect she likes SF/fantasy in general, but there’s a small chance she wants to watch them for other reasons. Thus, the RBM allows us to generate models of people in the messy, real world.)
- Conversely, if we know that one person likes SF/fantasy (so that the SF/fantasy unit is on), we can then ask the RBM which of the movie units that hidden unit turns on (i.e., ask the RBM to generate a set of movie recommendations). So the hidden units send messages to the movie units, telling them to update their states. (Again, note that the SF/fantasy unit being on doesn’t guarantee that we’ll always recommend all three of Harry Potter, Avatar, and LOTR 3 because, hey, not everyone who likes science fiction liked Avatar.)
Learning Weights
So how do we learn the connection weights in our network? Suppose we have a bunch of training examples, where each training example is a binary vector with six elements corresponding to a user’s movie preferences. Then for each epoch, do the following:

Continue until the network converges (i.e., the error between the training examples and their reconstructions falls below some threshold) or we reach some maximum number of epochs.
Why does this update rule make sense? Note that

(You may hear this update rule called contrastive divergence, which is basically a fancy term for “approximate gradient descent”.)
Examples
I wrote a simple RBM implementation in Python (the code is heavily commented, so take a look if you’re still a little fuzzy on how everything works), so let’s use it to walk through some examples.
First, I trained the RBM using some fake data.
- Alice: (Harry Potter = 1, Avatar = 1, LOTR 3 = 1, Gladiator = 0, Titanic = 0, Glitter = 0). Big SF/fantasy fan.
- Bob: (Harry Potter = 1, Avatar = 0, LOTR 3 = 1, Gladiator = 0, Titanic = 0, Glitter = 0). SF/fantasy fan, but doesn’t like Avatar.
- Carol: (Harry Potter = 1, Avatar = 1, LOTR 3 = 1, Gladiator = 0, Titanic = 0, Glitter = 0). Big SF/fantasy fan.
- David: (Harry Potter = 0, Avatar = 0, LOTR 3 = 1, Gladiator = 1, Titanic = 1, Glitter = 0). Big Oscar winners fan.
- Eric: (Harry Potter = 0, Avatar = 0, LOTR 3 = 1, Gladiator = 1, Titanic = 1, Glitter = 0). Oscar winners fan, except for Titanic.
- Fred: (Harry Potter = 0, Avatar = 0, LOTR 3 = 1, Gladiator = 1, Titanic = 1, Glitter = 0). Big Oscar winners fan.
The network learned the following weights:
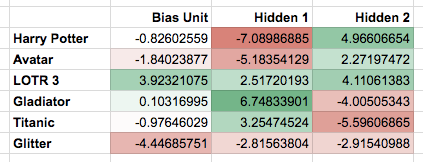
Note that the first hidden unit seems to correspond to the Oscar winners, and the second hidden unit seems to correspond to the SF/fantasy movies, just as we were hoping.
What happens if we give the RBM a new user, George, who has (Harry Potter = 0, Avatar = 0, LOTR 3 = 0, Gladiator = 1, Titanic = 1, Glitter = 0) as his preferences? It turns the Oscar winners unit on (but not the SF/fantasy unit), correctly guessing that George probably likes movies that are Oscar winners.
What happens if we activate only the SF/fantasy unit, and run the RBM a bunch of different times? In my trials, it turned on Harry Potter, Avatar, and LOTR 3 three times; it turned on Avatar and LOTR 3, but not Harry Potter, once; and it turned on Harry Potter and LOTR 3, but not Avatar, twice. Note that, based on our training examples, these generated preferences do indeed match what we might expect real SF/fantasy fans want to watch.
Modifications
I tried to keep the connection-learning algorithm I described above pretty simple, so here are some modifications that often appear in practice:

Introduction to Restricted Boltzmann Machines的更多相关文章
- 受限波兹曼机导论Introduction to Restricted Boltzmann Machines
Suppose you ask a bunch of users to rate a set of movies on a 0-100 scale. In classical factor analy ...
- (六)6.14 Neurons Networks Restricted Boltzmann Machines
1.RBM简介 受限玻尔兹曼机(Restricted Boltzmann Machines,RBM)最早由hinton提出,是一种无监督学习方法,即对于给定数据,找到最大程度拟合这组数据的参数.RBM ...
- CS229 6.14 Neurons Networks Restricted Boltzmann Machines
1.RBM简介 受限玻尔兹曼机(Restricted Boltzmann Machines,RBM)最早由hinton提出,是一种无监督学习方法,即对于给定数据,找到最大程度拟合这组数据的参数.RBM ...
- Convolutional Restricted Boltzmann Machines
参考论文:1.Stacks of Convolutional Restricted Boltzmann Machines for Shift-Invariant Feature Learning ...
- 限制波尔兹曼机(Restricted Boltzmann Machines)
能量模型的概念从统计力学中得来,它描述着整个系统的某种状态,系统越有序,系统能量波动越小,趋近于平衡状态,系统越无序,能量波动越大.例如:一个孤立的物体,其内部各处的温度不尽相同,那么热就从温度较高的 ...
- Restricted Boltzmann Machines
转自:http://deeplearning.net/tutorial/rbm.html http://blog.csdn.net/mytestmy/article/details/9150213 能 ...
- 受限玻尔兹曼机(RBM, Restricted Boltzmann machines)和深度信念网络(DBN, Deep Belief Networks)
受限玻尔兹曼机对于当今的非监督学习有一定的启发意义. 深度信念网络(DBN, Deep Belief Networks)于2006年由Geoffery Hinton提出.
- 限制Boltzmann机(Restricted Boltzmann Machine)
起源:Boltzmann神经网络 Boltzmann神经网络的结构是由Hopfield递归神经网络改良过来的,Hopfield中引入了统计物理学的能量函数的概念. 即,cost函数由统计物理学的能量函 ...
- 限制玻尔兹曼机(Restricted Boltzmann Machine)RBM
假设有一个二部图,每一层的节点之间没有连接,一层是可视层,即输入数据是(v),一层是隐藏层(h),如果假设所有的节点都是随机二值变量节点(只能取0或者1值)同时假设全概率分布满足Boltzmann 分 ...
随机推荐
- ipmitool管理工具
一.ipmitool简介 IPMI(Intelligent Platform Management Interface)智能平台管理接口 1.IPMI的核心是一个专用芯片/控制器(叫做服务器处理器或基 ...
- City Road
题目描述 从前有一个叫做”H湖”的地方,”H湖”的居民生活在不同的小岛上,当他们想去其他的小岛时都要通过划小船或者小岛之间的桥来实现.现在政府想实现”H湖”的全畅通!(不一定有直接的桥相连,只要互相间 ...
- mac docker --net=host
Docker 中的 host 模式指定是容器与主机享受相同的 network namespace. host 模式设计出来就是为了性能,但是这却对 docker 的隔离性造成了破坏,导致安全性降低. ...
- Python smtplib发邮件
常用邮箱SMTP.POP3域名及其端口号 发送普通文本内容的邮件 import smtplib from email.header import Header from email.mime.text ...
- flask内置的信号
from flask import Flask,request,template_rendered,render_template,got_request_exception from signals ...
- Linux文件权限基础知识
一.文件权限概述 Linux中每个文件或目录都有一组一组9个基础权限位,每三位字符被分为一组,他们分别是属主权限位(占三个字符).用户组权限位(占三个字符).其他用户权限位(占三个字符).比如rwxr ...
- P1494 小Z的袜子 【普通莫队】
我的第二道莫队题,对莫队又有了自己的看法. 在第一题的基础上之上,觉得莫队有个很关键的地方在于 莫队所维护的值是什么,怎么推出维护的公式来. 这道题就是这样,一开始还没自己推出公式来,也有几个坑点. ...
- setsockopt用法详解
最近做的一个程序用到了IOCP通信模型,里面用到了setsockopt对套接字进行设置,看源代码的时候最setsockopt函数很不理解,看了msdn以后还是不太明白这个函数的用法,于是就到网上找了一 ...
- linux:date 计算一组命令所花费的执行时间
date 命令可以用于计算一组命令所花费的执行时间 可以以不同的格式来读取.设置日期. (1) 读取日期: $ date Thu May 20 23:09:04 IST 2010 (2) 打印纪元时: ...
- 线程的同步控制synchronized和lock的对比和区别
转载. https://blog.csdn.net/wu1226419614/article/details/73740899 我们在面试的时候,时常被问到如何保证线程同步已经对共享资源的多线程编程 ...