Kafka消息模型
一、消息传递模型
传统的消息队列最少提供两种消息模型,一种P2P,一种PUB/SUB,而Kafka并没有这么做,巧妙的,它提供了一个消费者组的概念,一个消息可以被多个消费者组消费,但是只能被一个消费者组里的一个消费者消费,这样当只有一个消费者组时就等同与P2P模型,当存在多个消费者组时就是PUB/SUB模型。

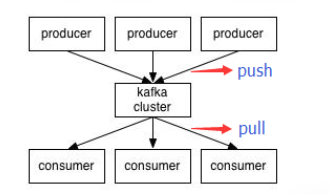
Kafka 的 consumer 是以pull的形式获取消息数据的。 pruducer push消息到kafka cluster ,consumer从集群中pull消息,如下图。该博客主要讲解. Parts在消费者中的分配、以及相关的消费者顺序、底层结构元数据信息、Kafka数据读取和存储等。
二、消息持久化
很多系统、组件为了提升效率一般恨不得把所有数据都扔到内存里,然后定期flush到磁盘上;可实际上,现代操作系统也是这样,所有的现代操作系统都乐于将空闲内存转作磁盘缓存(页面缓存),想不用都难;对于这样的系统,他的数据在内存中保存了一份,同时也在OS的页面缓存中保存了一份,这样不但多了一个步骤还让内存的使用率下降了一半;因此,Kafka决定直接使用页面缓存;但是随机写入的效率很慢,为了维护彼此的关系顺序还需要额外的操作和存储,而线性的写入可以避免这些,实际上,线性写入(linear write)的速度大约是300MB/秒,但随即写入却只有50k/秒,其中的差别接近10000倍。这样,Kafka以页面缓存为中间的设计在保证效率的同时还提供了消息的持久化,每个消费者自己维护当前读取数据的offser(也可委托给zookeeper),以此可同时支持在线和离线的消费。
三、Push vs. Pull
对于消息的消费,ActiveMQ使用PUSH模型,而Kafka使用PULL模型,两者各有利弊,对于PUSH,broker很难控制数据发送给不同消费者的速度,而PULL可以由消费者自己控制,但是PULL模型可能造成消费者在没有消息的情况下盲等,这种情况下可以通过long polling机制缓解,而对于几乎每时每刻都有消息传递的流式系统,这种影响可以忽略。
四、消息投递可靠性
一个消息如何算投递成功,Kafka提供了三种模式:
- 第一种是啥都不管,发送出去就当作成功,这种情况当然不能保证消息成功投递到broker;
- 第二种是Master-Slave模型,只有当Master和所有Slave都接收到消息时,才算投递成功,这种模型提供了最高的投递可靠性,但是损伤了性能;
- 第三种模型,即只要Master确认收到消息就算投递成功;实际使用时,根据应用特性选择,绝大多数情况下都会中和可靠性和性能选择第三种模型
消息在broker上的可靠性,因为消息会持久化到磁盘上,所以如果正常stop一个broker,其上的数据不会丢失;但是如果不正常stop,可能会使存在页面缓存来不及写入磁盘的消息丢失,这可以通过配置flush页面缓存的周期、阈值缓解,但是同样会频繁的写磁盘会影响性能,又是一个选择题,根据实际情况配置。
消息消费的可靠性,Kafka提供的是“At least once”模型,因为消息的读取进度由offset提供,offset可以由消费者自己维护也可以维护在zookeeper里,但是当消息消费后consumer挂掉,offset没有即时写回,就有可能发生重复读的情况,这种情况同样可以通过调整commit offset周期、阈值缓解,甚至消费者自己把消费和commit offset做成一个事务解决,但是如果你的应用不在乎重复消费,那就干脆不要解决,以换取最大的性能。
Kafka消息模型的更多相关文章
- RabbitMQ,RocketMQ,Kafka 消息模型对比分析
消息模型 消息队列的演进 消息队列模型 发布订阅模型 RabbitMQ的消息模型 交换器的类型 direct topic fanout headers Kafka的消息模型 RocketMQ的消息模型 ...
- RabbitMQ消息模型概览(简明教程)
小菜最近用到RabbitMQ,由于之前了解过其他消息中间件,算是有些基础,所以随手从网上搜了几篇文章,准备大概了解下RabbitMQ的消息模型,没想到网上文章千篇一律,写一大堆内容,就是说不明白到底怎 ...
- kafka消息队列的简单理解
kafka在大数据.分布式架构中都很流行.kafka可以进行流式计算,也可以做为日志系统,还可以用于消息队列. 本篇主要是消息队列相关的知识. 零.kafka作为消息队列的优点: 分布式的系统 高吞吐 ...
- Kafka实战:如何把Kafka消息时延秒降10倍
背景 国内某大型税务系统,业务应用分布式上云改造. 业务难题 如上图所示是模拟客户的业务网页构建的一个并发访问模型.用户在页面点击从而产生一个HTTP请求,这个请求发送到业务生产进程,就会启动一个投递 ...
- 如何保证kafka消息不丢失
背景 这里的kafka值得是broker,broker消息丢失的边界需要对齐一下: 1 已经提交的消息 2 有限度的持久化 如果消息没提交成功,并不是broke丢失了消息: 有限度的持久化(broke ...
- 为什么会有kafka消息系统?小问题藏着大细节!
前言:老刘今天写这篇文章首先想对一些复制粘贴的博客表达不满:其次是想用通俗易懂的话解释消息系统:最后欢迎各位英雄好汉.女中豪杰前来battle. 1. 为什么有消息系统? 1.1 背景 今天复习kaf ...
- Kafka消息时间戳(kafka message timestamp)
最近碰到了消息时间戳的问题,于是花了一些功夫研究了一下,特此记录一下. Kafka消息的时间戳 在消息中增加了一个时间戳字段和时间戳类型.目前支持的时间戳类型有两种: CreateTime 和 L ...
- Kafka 消息监控 - Kafka Eagle
1.概述 在开发工作当中,消费 Kafka 集群中的消息时,数据的变动是我们所关心的,当业务并不复杂的前提下,我们可以使用 Kafka 提供的命令工具,配合 Zookeeper 客户端工具,可以很方便 ...
- 简析android消息模型
android总结系列 一.消息系统构成要素和基本原理 l 消息队列 l 发送消息 l 消息读取 l 消息分发 l 消息循环线程 消息系统必须要依赖一个消息循环线程来轮询自己的消息队列,如果 ...
随机推荐
- Python多线程学习资料1
一.Python中的线程使用: Python中使用线程有两种方式:函数或者用类来包装线程对象. 1. 函数式:调用thread模块中的start_new_thread()函数来产生新线程.如下例: ...
- qemu 模拟-arm-mini2440开发板-启动u-boot,kernel和nfs文件系统
qemu 本文介绍了如何编译u-boot.linux kernel,然后用qemu启动u-boot和linux kernel,达到与开发板上一样的学习效果! 虽然已经买了2440开发板,但是在实际学习 ...
- rqnoj-396-SY学语文-dp
纯动态规划. 注意初始化为-INF #include<stdio.h> #include<algorithm> #include<iostream> #includ ...
- 如何在Visual Studio中选择C++和C#的编译器版本
博客搬到了fresky.github.io - Dawei XU,请各位看官挪步.最新的一篇是:如何在Visual Studio中选择C++和C#的编译器版本.
- 【Python3】SMTP发送邮件
犹豫和反复浪费了大量时间. 与朋友言 在完成一个邮件发送程序之前我根本不明白什么是邮件,哪怕已经读过廖雪峰大神的文章,没有贬低大神的意思,大神的博客已经非常的详细, 是我的眼大肚皮小毛病在作祟,由一个 ...
- MEF 编程指南(十):重组
有些应用程序被设计成在运行时动态地改变.例如,一个新的扩展可能被下载,或者其他原因变得不可用.MEF 依靠我们称之为重组(Composition)的技术处理,在初始化组合以后改变导入值的场景. 导 ...
- MVC4 EF6 MYSQL
在MVC的框架下连接mysql数据库 将EF框架升级到EF6 将NEW JSON升级到与之相匹配的版本 然后进行相应的配置就可以了
- SQL SERVER 设置自动备份和删除旧的数据库文件
打开SQL SERVER MANAGEMENT STUDIO,启动SQL SERVER代理服务(注意在“控制面板-管理工具-服务”中设置SQL SERVER AGENT的启动类型为自动).启动后点击“ ...
- 偶然发现关于网页JavaScript脚本无法正常运行的原因
客户常常打电话投诉公司的销售系统有问题, 后来发现有的客户直接把网址设为受限网站,才导致系统无法正常执行.改动后正常.
- ethtool 在 Linux 中的实现框架和应用
转载:http://www.ibm.com/developerworks/cn/linux/1304_wangjy_ethtools/index.html?ca=dat- 王 俊元, 软件工程师, I ...