2019-08-01【机器学习】有监督学习之分类 KNN,决策树,Nbayes算法实例 (人体运动状态信息评级)
样本:
使用的算法:
代码:
import numpy as np
import pandas as pd
import datetime from sklearn.impute import SimpleImputer #预处理模块
from sklearn.model_selection import train_test_split #训练集和测试集模块
from sklearn.metrics import classification_report #预测结果评估模块 from sklearn.neighbors import KNeighborsClassifier #K近邻分类器
from sklearn.tree import DecisionTreeClassifier #决策树分类器
from sklearn.naive_bayes import GaussianNB #高斯朴素贝叶斯函数 starttime = datetime.datetime.now() def load_datasets(feature_paths, label_paths):
feature = np.ndarray(shape=(0, 41)) #列数量和特征维度为41
label = np.ndarray(shape=(0, 1))
for file in feature_paths:
#逗号分隔符读取特征数据,将问号替换标记为缺失值,文件不包含表头
df = pd.read_table(file, delimiter=',', na_values='?', header=None)
#df = df.fillna(df.mean()) #若SimpleImputer无法处理nan,则用pandas本身处理
#使用平均值补全缺失值,然后将数据进行补全
imp = SimpleImputer(missing_values=np.nan, strategy='mean') #此处与教程不同,版本更新,需要使用最新的函数填充NAn,暂不明如何调用
imp.fit(df) #训练预处理器 此句有问题
df = imp.transform(df) #生产预处理结果
feature = np.concatenate((feature, df))#将新读入的数据合并到特征集中 for file in label_paths:
df = pd.read_table(file, header=None)
#将新读入的数据合并到标签集合中
label = np.concatenate((label, df))
#将标签归整为一维向量
label = np.ravel(label)
return feature, label if __name__ == '__main__':
#读取文件,根据本地目录文件夹而设定
path = 'D:\python_source\Machine_study\mooc_data\classification\dataset/'
featurePaths, labelPaths = [], []
for i in range(0, 5, 1): #chr(ord('A') + i)==B/C/D
featurePath = path + chr(ord('A') + i) + '/' + chr(ord('A') + i) + '.feature'
featurePaths.append(featurePath)
labelPath = path + chr(ord('A') + i) + '/' + chr(ord('A') + i) + '.label'
labelPaths.append(labelPath)
#将前4个数据作为训练集读入
x_train, y_train = load_datasets(featurePaths[:4], labelPaths[:4])
#将最后一个数据作为测试集读入
x_test, y_test = load_datasets(featurePaths[4:], labelPaths[4:])
#使用全量数据作为训练集,借助函数将训练数据打乱,便于后续分类器的初始化和训练
x_train, x_, y_train, y_ = train_test_split(x_train, y_train, test_size=0.0) print('Start training knn')
knn = KNeighborsClassifier().fit(x_train, y_train) #使用KNN算法进行训练
print('Training done')
answer_knn = knn.predict(x_test) print('Start training DT')
dt = DecisionTreeClassifier().fit(x_train, y_train) #使用决策树算法进行训练
print('Training done')
answer_dt = dt.predict(x_test)
print('Prediction done') print('Start training Bayes')
gnb = GaussianNB().fit(x_train, y_train) #使用贝叶斯算法进行训练
print('Training done')
answer_gnb = gnb.predict(x_test)
print('Prediction done') #对分类结果从 精确率precision 召回率recall f1值fl-score和支持度support四个维度进行衡量
print('\n\nThe classification report for knn:')
print(classification_report(y_test, answer_knn))
print('\n\nThe classification report for DT:')
print(classification_report(y_test, answer_dt))
print('\n\nThe classification report for Bayes:')
print(classification_report(y_test, answer_gnb))
endtime = datetime.datetime.now()
print(endtime - starttime) #时间统计
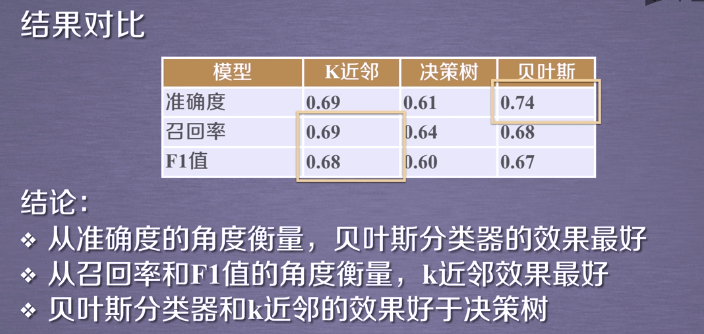
效果图:
2019-08-01【机器学习】有监督学习之分类 KNN,决策树,Nbayes算法实例 (人体运动状态信息评级)的更多相关文章
- 吴裕雄 python 机器学习——半监督学习标准迭代式标记传播算法LabelPropagation模型
import numpy as np import matplotlib.pyplot as plt from sklearn import metrics from sklearn import d ...
- 【纪中集训】2019.08.01【NOIP提高组】模拟 A 组TJ
T1 Description 给定一个\(N*N(N≤8)\)的矩阵,每一格有一个0~5的颜色.每次可将左上角的格子所在连通块变为一种颜色,求最少操作数. Solution IDA*=启发式迭代加深 ...
- 机器学习--最邻近规则分类KNN算法
理论学习: 3. 算法详述 3.1 步骤: 为了判断未知实例的类别,以所有已知类别的实例作为参照 选择参数K 计算未知实例与所有已知实例的距离 选 ...
- 机器学习——十大数据挖掘之一的决策树CART算法
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是机器学习专题的第23篇文章,我们今天分享的内容是十大数据挖掘算法之一的CART算法. CART算法全称是Classification ...
- 【Todo】【转载】Spark学习 & 机器学习(实战部分)-监督学习、分类与回归
理论原理部分可以看这一篇:http://www.cnblogs.com/charlesblc/p/6109551.html 这里是实战部分.参考了 http://www.cnblogs.com/shi ...
- Python 机器学习实战 —— 监督学习(下)
前言 近年来AI人工智能成为社会发展趋势,在IT行业引起一波热潮,有关机器学习.深度学习.神经网络等文章多不胜数.从智能家居.自动驾驶.无人机.智能机器人到人造卫星.安防军备,无论是国家级军事设备还是 ...
- Python 机器学习实战 —— 监督学习(上)
前言 近年来AI人工智能成为社会发展趋势,在IT行业引起一波热潮,有关机器学习.深度学习.神经网络等文章多不胜数.从智能家居.自动驾驶.无人机.智能机器人到人造卫星.安防军备,无论是国家级军事设备还是 ...
- python_机器学习_监督学习模型_决策树
决策树模型练习:https://www.kaggle.com/c/GiveMeSomeCredit/overview 1. 监督学习--分类 机器学习肿分类和预测算法的评估: a. 准确率 b.速度 ...
- 机器学习实战 - 读书笔记(07) - 利用AdaBoost元算法提高分类性能
前言 最近在看Peter Harrington写的"机器学习实战",这是我的学习笔记,这次是第7章 - 利用AdaBoost元算法提高分类性能. 核心思想 在使用某个特定的算法是, ...
随机推荐
- Spinner 用法
</Spinner> <TextView android:layout_width="wrap_content" android:layout_height=&q ...
- Nvue/Weex
Nvue/Weex 使用Uniapp做了一个App,感觉性能不是很好,了解过Uniapp的Nvue,就想做一个纯Nvue项目,其实基本就是做一个Weex项目,不得不说坑是真的多,但是渲染性能真的是没得 ...
- 攻防世界web新手区
攻防世界web新手区 第一题view_source 第二题get_post 第三题robots 第四题Backup 第五题cookie 第六题disabled_button 第七题simple_js ...
- 十 | 门控循环神经网络LSTM与GRU(附python演练)
欢迎大家关注我们的网站和系列教程:http://panchuang.net/ ,学习更多的机器学习.深度学习的知识! 目录: 门控循环神经网络简介 长短期记忆网络(LSTM) 门控制循环单元(GRU) ...
- Consul+upsync+Nginx 动态负载均衡
1,动态负载均衡 传统的负载均衡,如果修改了nginx.conf 的配置,必须需要重启nginx 服务,效率不高.动态负载均衡,就是可配置化,动态化的去配置负载均衡. 2,实现方案 1. Consul ...
- 使用SpringCloud将单体迁移至微服务
使用SpringBoot构建单体项目有一段时间了,准备对一个老项目重构时引入SpringCloud微服务,以此奠定后台服务能够应对未知的业务需求. 现在SOA架构下的服务管理面临很多挑战,比如面临一个 ...
- Ubuntu下已安装Anaconda但出现conda: command not found错误解决办法
原因:环境未配置 执行[vim ~/.bashrc]命令,进入配置文件,在最后一行按'o'插入一行,并添加语句: export PATH=/home/duanyongchun/anaconda3/bi ...
- RFID 有源,半源和无源的区别
RFID电子标签是由标签.解读器和数据传输和处理系统组成.内存带有天线的芯片,芯片中存储有能够识别目标的信息,主要作用都是为了识别货物.(更具体的自行搜索,本文单独讲三种的区别) RFID分为三种 有 ...
- 展示html/javascript/css------Live-Server
Live-server简介 这是一款带有热加载功能的小型开发服务器.用它来展示你的HTML / JavaScript / CSS,但不能用于部署最终的网站. 官网地址:https://www.npmj ...
- 【tensorflow2.0】处理时间序列数据
国内的新冠肺炎疫情从发现至今已经持续3个多月了,这场起源于吃野味的灾难给大家的生活造成了诸多方面的影响. 有的同学是收入上的,有的同学是感情上的,有的同学是心理上的,还有的同学是体重上的. 那么国内的 ...