入门大数据---Spark_Streaming与流处理
一、流处理
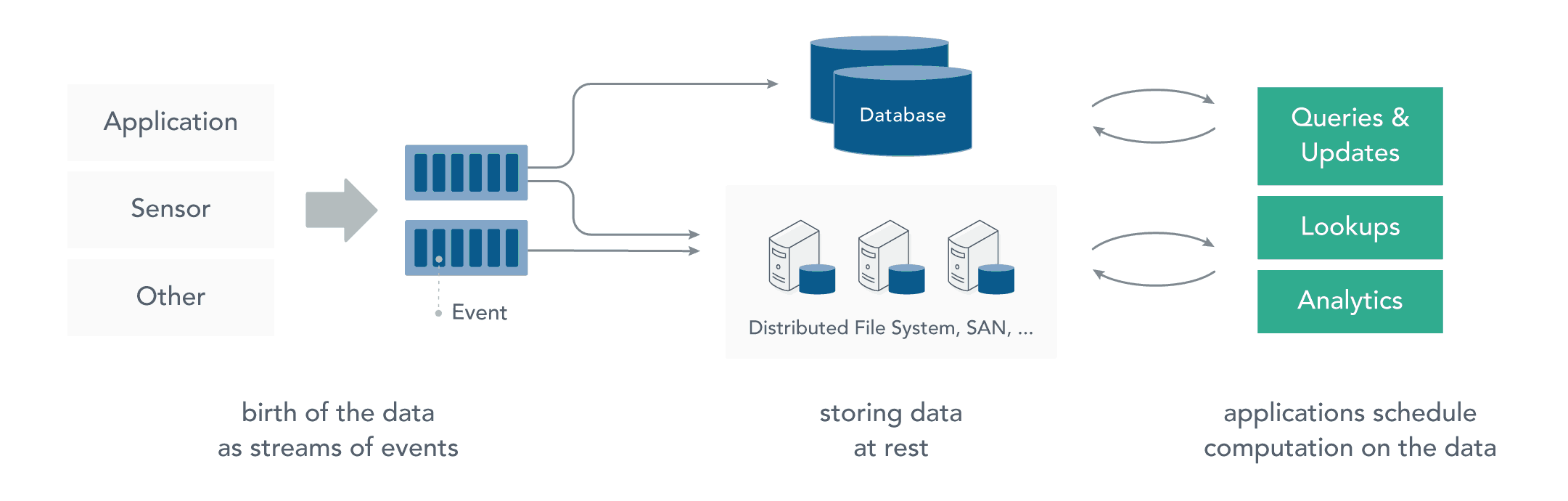
1.1 静态数据处理
在流处理之前,数据通常存储在数据库,文件系统或其他形式的存储系统中。应用程序根据需要查询数据或计算数据。这就是传统的静态数据处理架构。Hadoop 采用 HDFS 进行数据存储,采用 MapReduce 进行数据查询或分析,这就是典型的静态数据处理架构。
1.2 流处理
而流处理则是直接对运动中的数据的处理,在接收数据时直接计算数据。
大多数数据都是连续的流:传感器事件,网站上的用户活动,金融交易等等 ,所有这些数据都是随着时间的推移而创建的。
接收和发送数据流并执行应用程序或分析逻辑的系统称为流处理器。流处理器的基本职责是确保数据有效流动,同时具备可扩展性和容错能力,Storm 和 Flink 就是其代表性的实现。
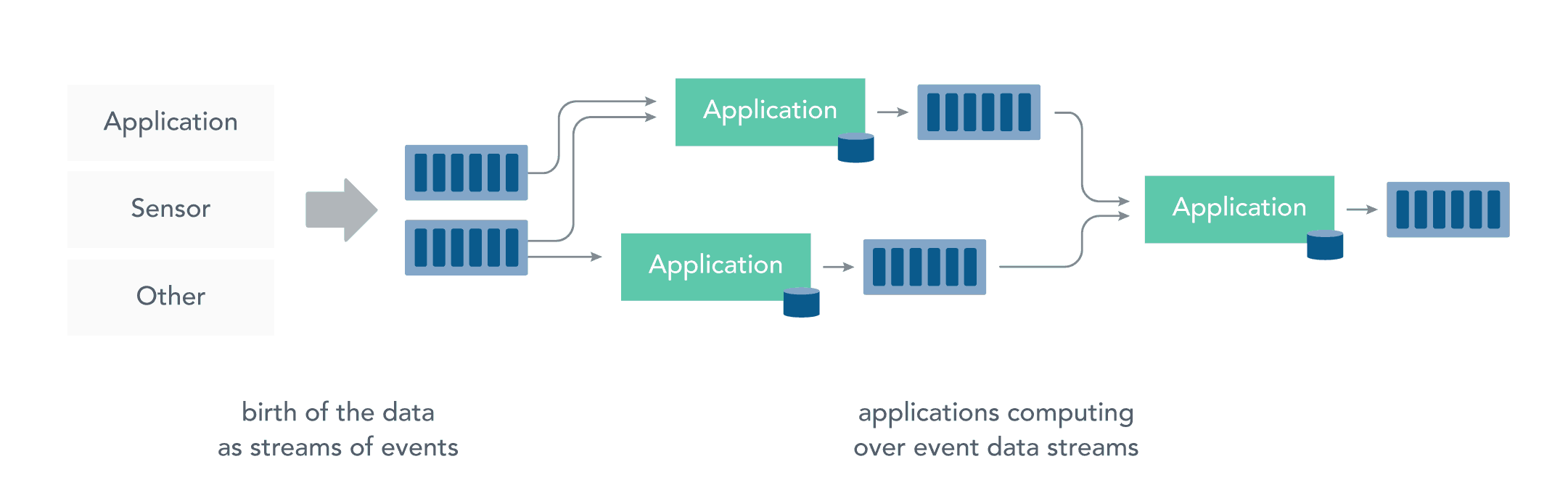
流处理带来了静态数据处理所不具备的众多优点:
- 应用程序立即对数据做出反应:降低了数据的滞后性,使得数据更具有时效性,更能反映对未来的预期;
- 流处理可以处理更大的数据量:直接处理数据流,并且只保留数据中有意义的子集,并将其传送到下一个处理单元,逐级过滤数据,降低需要处理的数据量,从而能够承受更大的数据量;
- 流处理更贴近现实的数据模型:在实际的环境中,一切数据都是持续变化的,要想能够通过过去的数据推断未来的趋势,必须保证数据的不断输入和模型的不断修正,典型的就是金融市场、股票市场,流处理能更好的应对这些数据的连续性的特征和及时性的需求;
- 流处理分散和分离基础设施:流式处理减少了对大型数据库的需求。相反,每个流处理程序通过流处理框架维护了自己的数据和状态,这使得流处理程序更适合微服务架构。
二、Spark Streaming
2.1 简介
Spark Streaming 是 Spark 的一个子模块,用于快速构建可扩展,高吞吐量,高容错的流处理程序。具有以下特点:
- 通过高级 API 构建应用程序,简单易用;
- 支持多种语言,如 Java,Scala 和 Python;
- 良好的容错性,Spark Streaming 支持快速从失败中恢复丢失的操作状态;
- 能够和 Spark 其他模块无缝集成,将流处理与批处理完美结合;
- Spark Streaming 可以从 HDFS,Flume,Kafka,Twitter 和 ZeroMQ 读取数据,也支持自定义数据源。

2.2 DStream
Spark Streaming 提供称为离散流 (DStream) 的高级抽象,用于表示连续的数据流。 DStream 可以从来自 Kafka,Flume 和 Kinesis 等数据源的输入数据流创建,也可以由其他 DStream 转化而来。在内部,DStream 表示为一系列 RDD。
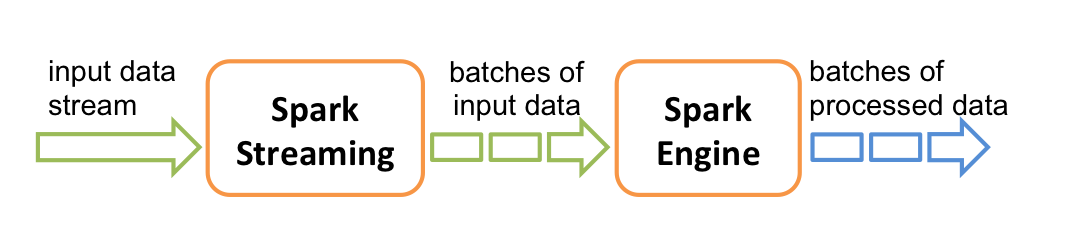
2.3 Spark & Storm & Flink
storm 和 Flink 都是真正意义上的流计算框架,但 Spark Streaming 只是将数据流进行极小粒度的拆分,拆分为多个批处理,使得其能够得到接近于流处理的效果,但其本质上还是批处理(或微批处理)。
参考资料
入门大数据---Spark_Streaming与流处理的更多相关文章
- 入门大数据---Spark_Streaming整合Flume
一.简介 Apache Flume 是一个分布式,高可用的数据收集系统,可以从不同的数据源收集数据,经过聚合后发送到分布式计算框架或者存储系统中.Spark Straming 提供了以下两种方式用于 ...
- 入门大数据---Spark_Streaming基本操作
一.案例引入 这里先引入一个基本的案例来演示流的创建:获取指定端口上的数据并进行词频统计.项目依赖和代码实现如下: <dependency> <groupId>org.apac ...
- 入门大数据---Spark_Streaming整合Kafka
一.版本说明 Spark 针对 Kafka 的不同版本,提供了两套整合方案:spark-streaming-kafka-0-8 和 spark-streaming-kafka-0-10,其主要区别如下 ...
- 大数据平台消息流系统Kafka
Kafka前世今生 随着大数据时代的到来,数据中蕴含的价值日益得到展现,仿佛一座待人挖掘的金矿,引来无数的掘金者.但随着数据量越来越大,如何实时准确地收集并分析如此大的数据成为摆在所有从业人员面前的难 ...
- 入门大数据---Flink学习总括
第一节 初识 Flink 在数据激增的时代,催生出了一批计算框架.最早期比较流行的有MapReduce,然后有Spark,直到现在越来越多的公司采用Flink处理.Flink相对前两个框架真正做到了高 ...
- 入门大数据---Flume整合Kafka
一.背景 先说一下,为什么要使用 Flume + Kafka? 以实时流处理项目为例,由于采集的数据量可能存在峰值和峰谷,假设是一个电商项目,那么峰值通常出现在秒杀时,这时如果直接将 Flume 聚合 ...
- 大数据-07-Spark之流数据
摘自 http://dblab.xmu.edu.cn/blog/1084-2/ 简介 DStream是Spark Streaming的编程模型,DStream的操作包括输入.转换和输出. Spark ...
- 入门大数据---SparkSQL外部数据源
一.简介 1.1 多数据源支持 Spark 支持以下六个核心数据源,同时 Spark 社区还提供了多达上百种数据源的读取方式,能够满足绝大部分使用场景. CSV JSON Parquet ORC JD ...
- 入门大数据---Hadoop是什么?
简单概括:Hadoop是由Apache组织使用Java语言开发的一款应对大数据存储和计算的分布式开源框架. Hadoop的起源 2003-2004年,Google公布了部分GFS和MapReduce思 ...
随机推荐
- Java-接口(另类抽象)
1.1 特点 用interface定义 接口中所有成员变量都默认是由public static final修饰的 接口中所有方法都默认是由public abstract修饰的 接口没有构造器 接口采用 ...
- Vue中导出Excel表格方法
本文记录一下在Vue中实现导出Excel表格的做法.参考度娘上各篇博客,最后实现功能 Excel表格,我的后端返回的是数据流,然后文件名是放进了content-disposition中,前端进行获取. ...
- Java实现 蓝桥杯 算法提高 合并石子
算法提高 合并石子 时间限制:2.0s 内存限制:256.0MB 问题描述 在一条直线上有n堆石子,每堆有一定的数量,每次可以将两堆相邻的石子合并,合并后放在两堆的中间位置,合并的费用为两堆石子的总数 ...
- Java实现 蓝桥杯VIP 算法提高 3-2求存款
算法提高 3-2求存款 时间限制:1.0s 内存限制:256.0MB 问题描述 见计算机程序设计基础(乔林)P50第5题. 接受两个数,一个是用户一年期定期存款金额,一个是按照百分比格式表示的利率,计 ...
- java实现平面点最小距离
已知平面上若干个点的坐标. 需要求出在所有的组合中,4个点间平均距离的最小值(四舍五入,保留2位小数). 比如有4个点:a,b,c,d, 则平均距离是指:ab, ac, ad, bc, bd, cd ...
- Java实现第九届蓝桥杯缩位求和
缩位求和 题目描述 在电子计算机普及以前,人们经常用一个粗略的方法来验算四则运算是否正确. 比如:248 * 15 = 3720 把乘数和被乘数分别逐位求和,如果是多位数再逐位求和,直到是1位数,得 ...
- 基于ABP做一个简单的系统——实战篇:1.项目准备
现阶段需要做一个小项目,体量很小,业务功能比较简单,就想到用最熟悉的.net来做,更何况现在.net core已经跨平台,也可以在linux服务器上部署.所以决定用.net core 3.1+mysq ...
- 氦元素 - CUBA 应用程序新样式主题
CUBA 框架一直以来定位的目标是业务系统的开发.业务系统的界面通常是给后台员工使用的,看重的是功能实现.多年来,界面外观和样式并不是后台管理系统的主要关注点,界面中的控件也更紧凑,唯一的原因 ...
- 轻量级进度条 – Nprogress.js
进度条库是前端中常见的库之一,bootstrap中提供了多种进度条样式.NProgress.js和nanobar.js是两款轻量级的进度条组件,使用简便. 官网: NProgress.js:http: ...
- Vue项目实战之改动饿了吗购物小球动画
html:没有写v-on: afterEnter函数了,因为执行不到,原因是enter的done: <div class="ball-container"><tr ...