关联规则之FpGrowth算法
Aprori算法利用频繁集的两个特性,过滤了很多无关的集合,效率提高不少,但是我们发现Apriori算法是一个候选消除算法,每一次消除都需要扫描一次所有数据记录,造成整个算法在面临大数据集时显得无能为力。今天我们介绍一个新的算法挖掘频繁项集,效率比Aprori算法高很多。
FpGrowth算法通过构造一个树结构来压缩数据记录,使得挖掘频繁项集只需要扫描两次数据记录,而且该算法不需要生成候选集合,所以效率会比较高。我们还是以上一篇中用的数据集为例:
| TID | Items |
| T1 | {牛奶,面包} |
| T2 | {面包,尿布,啤酒,鸡蛋} |
| T3 | {牛奶,尿布,啤酒,可乐} |
| T4 | {面包,牛奶,尿布,啤酒} |
| T5 | {面包,牛奶,尿布,可乐} |
一、构造FpTree
FpTree是一种树结构,树结构定义如下:
public class FpNode {
String idName;// id号
List<FpNode> children;// 孩子结点
FpNode parent;// 父结点
FpNode next;// 下一个id号相同的结点
long count;// 出现次数
}
树的每一个结点代表一个项,这里我们先不着急看树的结构,我们演示一下FpTree的构造过程,FpTree构造好后自然明白了树的结构。假设我们的最小绝对支持度是3。
Step 1:扫描数据记录,生成一级频繁项集,并按出现次数由多到少排序,如下所示:
| Item | Count |
| 牛奶 | 4 |
| 面包 | 4 |
| 尿布 | 4 |
| 啤酒 | 3 |
可以看到,鸡蛋和可乐没有出现在上表中,因为可乐只出现2次,鸡蛋只出现1次,小于最小支持度,因此不是频繁项集,根据Apriori定理,非频繁项集的超集一定不是频繁项集,所以可乐和鸡蛋不需要再考虑。
Step 2:再次扫描数据记录,对每条记录中出现在Step 1产生的表中的项,按表中的顺序排序。初始时,新建一个根结点,标记为null;
1)第一条记录:{牛奶,面包},按Step 1表过滤排序得到依然为{牛奶,面包},新建一个结点,idName为{牛奶},将其插入到根节点下,并设置count为1,然后新建一个{面包}结点,插入到{牛奶}结点下面,插入后如下所示:

2)第二条记录:{面包,尿布,啤酒,鸡蛋},过滤并排序后为:{面包,尿布,啤酒},发现根结点没有包含{面包}的儿子(有一个{面包}孙子但不是儿子),因此新建一个{面包}结点,插在根结点下面,这样根结点就有了两个孩子,随后新建{尿布}结点插在{面包}结点下面,新建{啤酒}结点插在{尿布}下面,插入后如下所示:
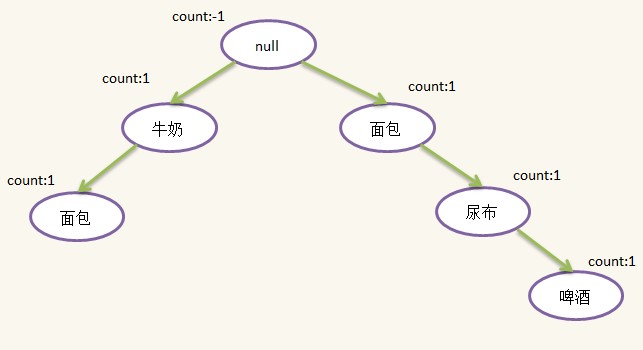
3)第三条记录:{牛奶,尿布,啤酒,可乐},过滤并排序后为:{牛奶,尿布,啤酒},这时候发现根结点有儿子{牛奶},因此不需要新建结点,只需将原来的{牛奶}结点的count加1即可,往下发现{牛奶}结点有一个儿子{尿布},于是新建{尿布}结点,并插入到{牛奶}结点下面,随后新建{啤酒}结点插入到{尿布}结点后面。插入后如下图所示:

4)第四条记录:{面包,牛奶,尿布,啤酒},过滤并排序后为:{牛奶,面包,尿布,啤酒},这时候发现根结点有儿子{牛奶},因此不需要新建结点,只需将原来的{牛奶}结点的count加1即可,往下发现{牛奶}结点有一个儿子{面包},于是也不需要新建{面包}结点,只需将原来{面包}结点的count加1,由于这个{面包}结点没有儿子,此时需新建{尿布}结点,插在{面包}结点下面,随后新建{啤酒}结点,插在{尿布}结点下面,插入后如下图所示:
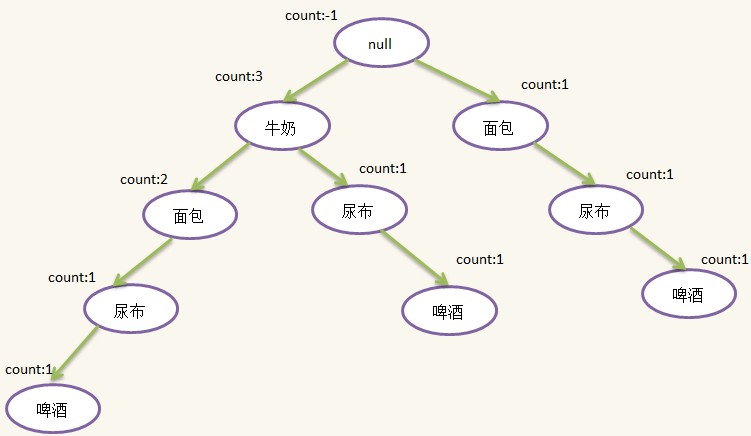
5)第五条记录:{面包,牛奶,尿布,可乐},过滤并排序后为:{牛奶,面包,尿布},检查发现根结点有{牛奶}儿子,{牛奶}结点有{面包}儿子,{面包}结点有{尿布}儿子,本次插入不需要新建结点只需更新count即可,示意图如下:
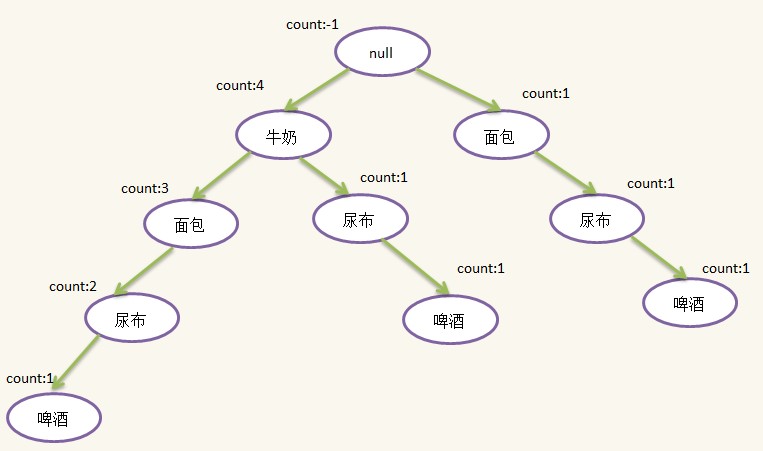
按照上面的步骤,我们已经基本构造了一棵FpTree(Frequent Pattern Tree),树中每天路径代表一个项集,因为许多项集有公共项,而且出现次数越多的项越可能是公公项,因此按出现次数由多到少的顺序可以节省空间,实现压缩存储,另外我们需要一个表头和对每一个idName相同的结点做一个线索,方便后面使用,线索的构造也是在建树过程形成的,但为了简化FpTree的生成过程,我没有在上面提到,这个在代码有体现的,添加线索和表头的Fptree如下:
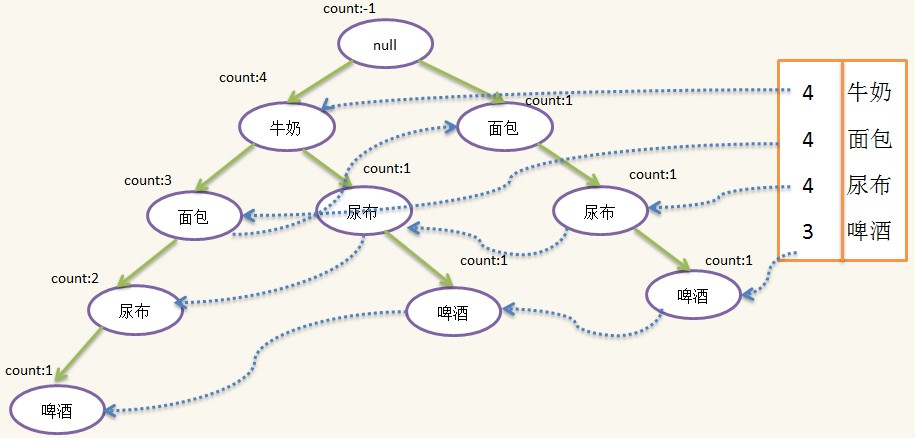
至此,整个FpTree就构造好了,在下面的挖掘过程中我们会看到表头和线索的作用。
二、利用FpTree挖掘频繁项集
FpTree建好后,就可以进行频繁项集的挖掘,挖掘算法称为FpGrowth(Frequent Pattern Growth)算法,挖掘从表头header的最后一个项开始。
1)此处即从{啤酒}开始,根据{啤酒}的线索链找到所有{啤酒}结点,然后找出每个{啤酒}结点的分支:{牛奶,面包,尿布,啤酒:1},{牛奶,尿布,啤酒:1},{面包,尿布,啤酒:1},其中的“1”表示出现1次,注意,虽然{牛奶}出现4次,但{牛奶,面包,尿布,啤酒}只同时出现1次,因此分支的count是由后缀结点{啤酒}的count决定的,除去{啤酒},我们得到对应的前缀路径{牛奶,面包,尿布:1},{牛奶,尿布:1},{面包,尿布:1},根据前缀路径我们可以生成一颗条件FpTree,构造方式跟之前一样,此处的数据记录变为:
| TID | Items |
| T1 | {牛奶,面包,尿布} |
| T2 | {牛奶,尿布} |
| T3 | {面包,尿布} |
绝对支持度依然是3,构造得到的FpTree为:
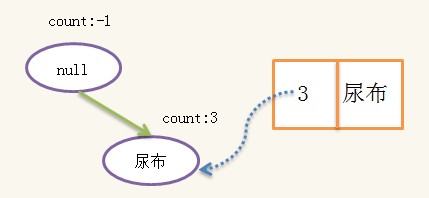
构造好条件树后,对条件树进行递归挖掘,当条件树只有一条路径时,路径的所有组合即为条件频繁集,假设{啤酒}的条件频繁集为{S1,S2,S3},则{啤酒}的频繁集为{S1+{啤酒},S2+{啤酒},S3+{啤酒}},即{啤酒}的频繁集一定有相同的后缀{啤酒},此处的条件频繁集为:{{},{尿布}},于是{啤酒}的频繁集为{{啤酒}{尿布,啤酒}}。
2)接下来找header表头的倒数第二个项{尿布}的频繁集,同上可以得到{尿布}的前缀路径为:{面包:1},{牛奶:1},{牛奶,面包:2},条件FpTree的数据集为:
| TID | Items |
| T1 | {面包} |
| T2 | {牛奶} |
| T3 | {牛奶,面包} |
| T4 | {牛奶,面包} |
注意{牛奶,面包:2},即{牛奶,面包}的count为2,所以在{牛奶,面包}重复了两次,这样做的目的是可以利用之前构造FpTree的算法来构造条件Fptree,不过这样效率会降低,试想如果{牛奶,面包}的count为20000,那么就需要展开成20000条记录,然后进行20000次count更新,而事实上只需要对count更新一次到20000即可。这是实现上的优化细节,实践中当注意。构造的条件FpTree为:

这颗条件树已经是单一路径,路径上的所有组合即为条件频繁集:{{},{牛奶},{面包},{牛奶,面包}},加上{尿布}后,又得到一组频繁项集{{尿布},{牛奶,尿布},{面包,尿布},{牛奶,面包,尿布}},这组频繁项集一定包含一个相同的后缀:{尿布},并且不包含{啤酒},因此这一组频繁项集与上一组不会重复。
重复以上步骤,对header表头的每个项进行挖掘,即可得到整个频繁项集,可以证明(严谨的算法和证明可见参考文献[1]),频繁项集即不重复也不遗漏。
程序的实现代码还是放在我的github上,这里看一下运行结果:
绝对支持度: 3
频繁项集:
面包 尿布 3
尿布 牛奶 3
牛奶 4
面包 牛奶 3
尿布 啤酒 3
面包 4
另外我下载了一个购物篮的数据集,数据量较大,测试了一下FpGrowth的效率还是不错的。FpGrowth算法的平均效率远高于Apriori算法,但是它并不能保证高效率,它的效率依赖于数据集,当数据集中的频繁项集的没有公共项时,所有的项集都挂在根结点上,不能实现压缩存储,而且Fptree还需要其他的开销,需要存储空间更大,使用FpGrowth算法前,对数据分析一下,看是否适合用FpGrowth算法。
参考文档:http://www.cnblogs.com/fengfenggirl/p/associate_fpgowth.html
关联规则之FpGrowth算法的更多相关文章
- 数据挖掘进阶之关联规则挖掘FP-Growth算法
数据挖掘进阶之关联规则挖掘FP-Growth算法 绪 近期在写论文方面涉及到了数据挖掘,需要通过数据挖掘方法实现软件与用户间交互模式的获取.分析与分类研究.主要涉及到关联规则与序列模式挖掘两块.关联规 ...
- FP-growth算法思想和其python实现
第十二章 使用FP-growth算法高效的发现频繁项集 一.导语 FP-growth算法是用于发现频繁项集的算法,它不能够用于发现关联规则.FP-growth算法的特殊之处在于它是通过构建一棵Fp树, ...
- 机器学习之Apriori算法和FP-growth算法
1 关联分析 无监督机器学习方法中的关联分析问题.关联分析可以用于回答"哪些商品经常被同时购买?"之类的问题. 2 Apriori算法 频繁项集即出现次数多的数据集 支持度 ...
- 机器学习(九)—FP-growth算法
本来老师是想让我学Hadoop的,也装了Ubuntu,配置了Hadoop,一时间却不知从何学起,加之自己还是想先看点自己喜欢的算法,学习Hadoop也就暂且搁置了,不过还是想问一下园子里的朋友有什么学 ...
- 数据挖掘系列(2)--关联规则FpGrowth算法
上一篇介绍了关联规则挖掘的一些基本概念和经典的Apriori算法,Aprori算法利用频繁集的两个特性,过滤了很多无关的集合,效率提高不少,但是我们发现Apriori算法是一个候选消除算法,每一次消除 ...
- 数据挖掘算法之关联规则挖掘(二)FPGrowth算法
之前介绍的apriori算法中因为存在许多的缺陷,例如进行大量的全表扫描和计算量巨大的自然连接,所以现在几乎已经不再使用 在mahout的算法库中使用的是PFP算法,该算法是FPGrowth算法的分布 ...
- 使用 FP-growth 算法高效挖掘海量数据中的频繁项集
前言 对于如何发现一个数据集中的频繁项集,前文讲解的经典 Apriori 算法能够做到. 然而,对于每个潜在的频繁项,它都要检索一遍数据集,这是比较低效的.在实际的大数据应用中,这么做就更不好了. 本 ...
- 机器学习实战 - 读书笔记(12) - 使用FP-growth算法来高效发现频繁项集
前言 最近在看Peter Harrington写的"机器学习实战",这是我的学习心得,这次是第12章 - 使用FP-growth算法来高效发现频繁项集. 基本概念 FP-growt ...
- 使用Apriori算法和FP-growth算法进行关联分析
系列文章:<机器学习实战>学习笔记 最近看了<机器学习实战>中的第11章(使用Apriori算法进行关联分析)和第12章(使用FP-growth算法来高效发现频繁项集).正如章 ...
随机推荐
- SpringCloud学习之Stream消息驱动【默认通道】(十)
在实际开发过程中,服务与服务之间通信经常会使用到消息中间件,而以往使用了中间件比如RabbitMQ,那么该中间件和系统的耦合性就会非常高,如果我们要替换为Kafka那么变动会比较大,这时我们可以使用S ...
- Win10 MySQL5.7中文乱码问题
https://blog.csdn.net/hh___56789/article/details/87900923 最好把 utf8 都换成utf8mb4 ,以免以后遇到意想不到的错误.utf8有漏洞 ...
- Linux(CENTOS7) Nginx负载均衡简单配置
负载均衡的作用 1.转发功能 按照一定的算法[权重.轮询],将客户端请求转发到不同应用服务器上,减轻单个服务器压力,提高系统并发量. 2.故障移除 通过心跳检测的方式,判断应用服务器当前是否可以正常工 ...
- 36. docker swarm docker secret 的使用和管理
1.secret management 的作用 用来存储 其他人不想看到 的数据 2.secret management 存在 swarm manager 节点 raft database 里. se ...
- 小程序Java多次请求Session不变
微信小程序每次请求的sessionid是变化的,导致对应后台的session不一致,无法获取之前保存在session中的openid和sessionKey. 为了解决这个问题,需要强制同意每次小程序前 ...
- LeetCode——324. 摆动排序 II
给定一个无序的数组 nums,将它重新排列成 nums[0] < nums[1] > nums[2] < nums[3]... 的顺序. 示例 1: 输入: nums = [1, 5 ...
- 【转载】Github上优秀的.NET Core项目
Github上优秀的.NET Core项目 Github上优秀的.NET Core开源项目的集合.内容包括:库.工具.框架.模板引擎.身份认证.数据库.ORM框架.图片处理.文本处理.机器学习.日志. ...
- dotnet core 链接mongodb
导入命名空间 using MongoDB.Bson; using MongoDB.Driver; 测试示例: var client = new MongoClient("mongodb:// ...
- Java web之javascript(2020.1.6)
1.js输出: windows.alert()---警告框 document.write()---写到html文档中 innerHTML---写到HTML元素 console.log()---写到浏览 ...
- 10. 通过 Dockerfile 编写 linux 命令行工具
测试 linux 压力的工具 一. 实际操作 1. 创建一个 ubuntu 的容器 docker run -it ubuntu 2. 安装 stress 工具 apt-get update & ...