python爬虫入门四:BeautifulSoup库(转)
正则表达式可以从html代码中提取我们想要的数据信息,它比较繁琐复杂,编写的时候效率不高,但我们又最好是能够学会使用正则表达式。
我在网络上发现了一篇关于写得很好的教程,如果需要使用正则表达式的话,参照此篇文章即可:正则表达式30分钟入门教程
在这里我们学习使用另一种简便的方法用来解析网页:BeautifulSoup库。
BeautifulSoup是一种灵活又方便的网页解析库,处理高效,支持多种解析器。利用它就可以不编写正则表达式也可以方便地实现网页信息的提取。
接下来内容转载自python爬虫从入门到放弃(六)之 BeautifulSoup库的使用:
快速使用
通过下面的一个例子,对bs4有个简单的了解,以及看一下它的强大之处:
from bs4 import BeautifulSoup
html = '''
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
'''
soup = BeautifulSoup(html,'lxml')
print(soup.prettify())
print(soup.title)
print(soup.title.name)
print(soup.title.string)
print(soup.title.parent.name)
print(soup.p)
print(soup.p["class"])
print(soup.a)
print(soup.find_all('a'))
print(soup.find(id='link3'))
结果如下:

使用BeautifulSoup解析这段代码,能够得到一个 BeautifulSoup 的对象,并能按照标准的缩进格式的结构输出。
同时我们通过下面代码可以分别获取所有的链接,以及文字内容:
for link in soup.find_all('a'):
print(link.get('href'))
print(soup.get_text())
解析器
Beautiful Soup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,如果我们不安装它,则 Python 会使用 Python默认的解析器,lxml 解析器更加强大,速度更快,推荐安装。
下面是常见解析器:
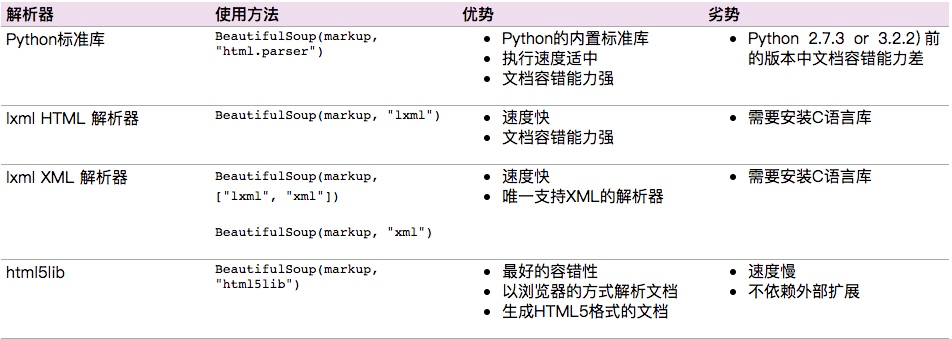
推荐使用lxml作为解析器,因为效率更高. 在Python2.7.3之前的版本和Python3中3.2.2之前的版本,必须安装lxml或html5lib, 因为那些Python版本的标准库中内置的HTML解析方法不够稳定.
基本使用
标签选择器
在快速使用中我们添加如下代码:
print(soup.title)
print(type(soup.title))
print(soup.head)
print(soup.p)
通过这种soup.标签名 我们就可以获得这个标签的内容
这里有个问题需要注意,通过这种方式获取标签,如果文档中有多个这样的标签,返回的结果是第一个标签的内容,如上面我们通过soup.p获取p标签,而文档中有多个p标签,但是只返回了第一个p标签内容
获取名称
当我们通过soup.title.name的时候就可以获得该title标签的名称,即title
获取属性
print(soup.p.attrs['name'])
print(soup.p['name'])
上面两种方式都可以获取p标签的name属性值
获取内容
print(soup.p.string)
结果就可以获取第一个p标签的内容:
The Dormouse's story
嵌套选择
我们直接可以通过下面嵌套的方式获取
print(soup.head.title.string)
子节点和子孙节点
contents的使用
通过下面例子演示:
html = """
<html>
<head>
<title>The Dormouse's story</title>
</head>
<body>
<p class="story">
Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">
<span>Elsie</span>
</a>
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a>
and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>
and they lived at the bottom of a well.
</p>
<p class="story">...</p>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html,'lxml')
print(soup.p.contents)
结果是将p标签下的所有子标签存入到了一个列表中
列表中会存入如下元素
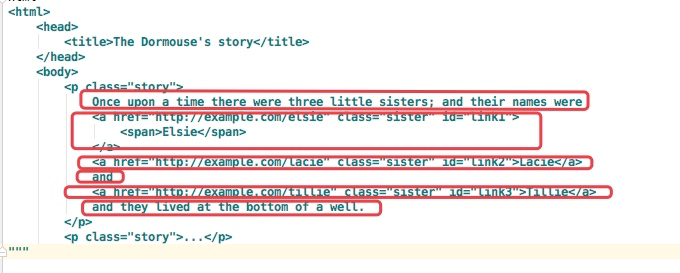
children的使用
通过下面的方式也可以获取p标签下的所有子节点内容和通过contents获取的结果是一样的,但是不同的地方是soup.p.children是一个迭代对象,而不是列表,只能通过循环的方式获取素有的信息
print(soup.p.children)
for i,child in enumerate(soup.p.children):
print(i,child)
通过contents以及children都是获取子节点,如果想要获取子孙节点可以通过descendants
print(soup.descendants)同时这种获取的结果也是一个迭代器
父节点和祖先节点
通过soup.a.parent就可以获取父节点的信息
通过list(enumerate(soup.a.parents))可以获取祖先节点,这个方法返回的结果是一个列表,会分别将a标签的父节点的信息存放到列表中,以及父节点的父节点也放到列表中,并且最后还会讲整个文档放到列表中,所有列表的最后一个元素以及倒数第二个元素都是存的整个文档的信息
兄弟节点
soup.a.next_siblings 获取后面的兄弟节点
soup.a.previous_siblings 获取前面的兄弟节点
soup.a.next_sibling 获取下一个兄弟标签
souo.a.previous_sinbling 获取上一个兄弟标签
标准选择器
find_all
find_all(name,attrs,recursive,text,**kwargs)
可以根据标签名,属性,内容查找文档
name的用法
html='''
<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Foo</li>
<li class="element">Bar</li>
</ul>
</div>
</div>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.find_all('ul'))
print(type(soup.find_all('ul')[0]))
结果返回的是一个列表的方式

同时我们是可以针对结果再次find_all,从而获取所有的li标签信息
for ul in soup.find_all('ul'):
print(ul.find_all('li'))
attrs
例子如下:
html='''
<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1" name="elements">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Foo</li>
<li class="element">Bar</li>
</ul>
</div>
</div>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.find_all(attrs={'id': 'list-1'}))
print(soup.find_all(attrs={'name': 'elements'}))
attrs可以传入字典的方式来查找标签,但是这里有个特殊的就是class,因为class在python中是特殊的字段,所以如果想要查找class相关的可以更改attrs={'class_':'element'}或者soup.find_all('',{"class":"element}),特殊的标签属性可以不写attrs,例如id
text
例子如下:
html='''
<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Foo</li>
<li class="element">Bar</li>
</ul>
</div>
</div>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.find_all(text='Foo'))
结果返回的是查到的所有的text='Foo'的文本

find
find(name,attrs,recursive,text,**kwargs)
find返回的匹配结果的第一个元素
其他一些类似的用法:
find_parents()返回所有祖先节点,find_parent()返回直接父节点。
find_next_siblings()返回后面所有兄弟节点,find_next_sibling()返回后面第一个兄弟节点。
find_previous_siblings()返回前面所有兄弟节点,find_previous_sibling()返回前面第一个兄弟节点。
find_all_next()返回节点后所有符合条件的节点, find_next()返回第一个符合条件的节点
find_all_previous()返回节点后所有符合条件的节点, find_previous()返回第一个符合条件的节点
CSS选择器
通过select()直接传入CSS选择器就可以完成选择
熟悉前端的人对CSS可能更加了解,其实用法也是一样的
.表示class #表示id
标签1,标签2 找到所有的标签1和标签2
标签1 标签2 找到标签1内部的所有的标签2
[attr] 可以通过这种方法找到具有某个属性的所有标签
[atrr=value] 例子[target=_blank]表示查找所有target=_blank的标签
<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Foo</li>
<li class="element">Bar</li>
</ul>
</div>
</div>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.select('.panel .panel-heading'))
print(soup.select('ul li'))
print(soup.select('#list-2 .element'))
print(type(soup.select('ul')[0]))
获取内容
通过get_text()就可以获取文本内容
html='''
<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Foo</li>
<li class="element">Bar</li>
</ul>
</div>
</div>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
for li in soup.select('li'):
print(li.get_text())
获取属性
或者属性的时候可以通过[属性名]或者attrs[属性名]
html='''
<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Foo</li>
<li class="element">Bar</li>
</ul>
</div>
</div>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
for ul in soup.select('ul'):
print(ul['id'])
print(ul.attrs['id'])
参考资料:
1. python爬虫从入门到放弃(六)之 BeautifulSoup库的使用
2. 史上最全的BeautifulSoup解析(基本选择器,标准选择器,css选择器)
3. CSS 选择器参考手册
python爬虫入门四:BeautifulSoup库(转)的更多相关文章
- Python爬虫入门四之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- 转 Python爬虫入门四之Urllib库的高级用法
静觅 » Python爬虫入门四之Urllib库的高级用法 1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我 ...
- Python爬虫入门之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- Python爬虫入门之Urllib库的基本使用
那么接下来,小伙伴们就一起和我真正迈向我们的爬虫之路吧. 1.分分钟扒一个网页下来 怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器解 ...
- Python爬虫利器:BeautifulSoup库
Beautiful Soup parses anything you give it, and does the tree traversal stuff for you. BeautifulSoup ...
- PYTHON 爬虫笔记五:BeautifulSoup库基础用法
知识点一:BeautifulSoup库详解及其基本使用方法 什么是BeautifulSoup 灵活又方便的网页解析库,处理高效,支持多种解析器.利用它不用编写正则表达式即可方便实现网页信息的提取库. ...
- 4.Python爬虫入门四之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- Python爬虫入门:Urllib库的高级使用
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- Python爬虫入门:Urllib库的基本使用
1.分分钟扒一个网页下来 怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器解释才呈现出来的,实质它 是一段HTML代码,加 JS.CS ...
随机推荐
- CSS 两边是线 中间是文字的效果
刚开始做的时候 想了一下 这个是怎么做出来的,后来在网上看到有个类似的效果,研究一下 <!DOCTYPE html> <html lang="en"> &l ...
- HDU-1029-Ignatius aned the Princess IV
链接:https://vjudge.net/problem/HDU-1029#author=0 题意: 给你n个数字,请你找出出现至少(n+1)/2次的数字. 思路: dp,hash超时了,不知道是不 ...
- 12.Maps
1 Maps 1.1 Map声明和访问 maps中的元素是key-value对儿,key与value之间使用冒号(:)分割.创建一个空value的map,使用[:].默认情况下,map的 ...
- Linux、UNIX设置开机自动运行命令、脚本配置
一般我们不建议人工部署开机自动启动的脚本.而是建议通过crontab 部署脚本监控,理由如下: 1.自动开机部署脚本不好定位问题,有可能导致主机重启过慢. 2.自动开机部署脚本不好定位问题,有可能导致 ...
- 复习线程——状态和几个Thread方法
一.线程的状态 (参考文章:https://blog.csdn.net/a58220655/article/details/76695142) 状态介绍 新建(new):处于该状态的时间很短暂.已被分 ...
- (转)C#文件操作大全
转自:https://www.cnblogs.com/wangshenhe/archive/2012/05/09/2490438.html 文件与文件夹操作主要用到以下几个类: 1.File类: 提供 ...
- yii2 操作数据库
1.查询 User::find()->all(); 此方法返回所有数据: User::findOne($id); 此方法返回 主键 id=1 的一条数据(举个例子): User::find()- ...
- aspx页面调用webapi接口报错:远程服务器返回错误:(500)内部服务器错误
代码在运行到response = (HttpWebResponse)request.GetResponse();就开始报错 原因:可能因为所调用的接口不存在或者接口中存在错误,可用postman测试接 ...
- 第十章 设计用户界面 之 构建UI布局
1. 概述 本章内容包括:实现可在不同区域重用的片段.使用Razor模板设计和实现页面.设计可视结构的布局.基于模板页开发. 2. 主要内容 2.1 实现可在不同区域重用的片段 最简单的重用方式就是在 ...
- TCP简单程序
服务器段: package com.dcz.socket; import java.io.IOException; import java.io.OutputStream; import java.n ...