scrapy框架中Item Pipeline用法
scrapy框架中item pipeline用法
当Item 在Spider中被收集之后,就会被传递到Item Pipeline中进行处理
每个item pipeline组件是实现了简单的方法的python类,负责接收到item并通过它执行一些行为,同时也决定此Item是否继续通过pipeline,或者被丢弃而不再进行处理
item pipeline的主要作用:
- 清理html数据
- 验证爬取的数据
- 去重并丢弃
- 将爬取的结果保存到数据库中或文件中
持久化存储
import pymysql
import redis # 只要涉及到持久化相关的操作,必须写在管道文件中 # 管道文件:需要接收爬虫文件提交过来的数据,并对数据进行持久化存储(IO操作)
class ThreePipeline(object):
fp = None # 只会被执行一次(开始爬虫的时候执行一次)
def open_spider(self, spider):
print('开始爬虫')
self.fp = open('./job.txt', "w") # 链接数据库啊,数据库的写入等操作 # 只能处理item
# 和items联合使用的
# process_item核心方法被调用 将item中数据写入磁盘本地
# 爬虫每提交一次item,该方法就会被调用一次
def process_item(self, item, spider):
# 爬虫每提交一次item,该方法就会被调用一次
# print(item['company'])
self.fp.write(item['title'] + "\t" + item['salary'] + '\t' + item['salary'] + '\n') return item def close_spider(self, spider):
print('爬虫结束')
self.fp.close() # 注意:默认情况下管道机制并没有开启,需要手动在配置文件中手动开启 # 使用管道进行持久化存储的流程:
"""
1 获取解析到的数据值
2 将解析的数据值存储到item对象(item类中进行相关属性的声明)
3 通过yield关键字将item提交到管道
4 管道文件中进行持久化存储代码的编写(process_item)
5 在配置文件中开启管道
""" # 存入mysql
class MysqlPipeline(object):
conn = None
cursor = None def open_spider(self, spider):
print("mysql-start")
self.conn = pymysql.Connect(host='127.0.0.1', port=3306, user='root', password='', db='spider')
print(self.conn) def process_item(self, item, spider):
self.cursor = self.conn.cursor()
sql = 'insert into boss values ("%s", "%s", "%s")' % (item['title'], item['salary'], item['company'])
try:
self.cursor.execute(sql)
self.conn.commit()
except Exception as e:
print(e)
self.conn.rollback() return item def close_spider(self, spider):
self.cursor.close()
self.conn.close()
print('mysql-end') # 存入redis
class RedisPipeline(object):
conn = None def open_spider(self, spider):
print('redis-start')
self.conn = redis.Redis(host='127.0.0.1', port=6379) def process_item(self, item, spider):
dic = {
"title": item['title'],
"salary": item['salary'],
"company": item['company']
}
self.conn.lpush('job_info', dic) return item def close_spider(self, spider):
print('redis-end') # 注意: 一定要保证每一个管道类的process_item方法有返回值
持久化存储-mysql-文件-redis
编写自己的item pipeline
process_item(self,item,spider)
每个item piple组件是一个独立的pyhton类,必须实现以process_item(self,item,spider)方法
每个item pipeline组件都需要调用该方法,这个方法必须返回一个具有数据的dict,或者item对象,或者抛出DropItem异常,被丢弃的item将不会被之后的pipeline组件所处理
下面的方法也可以选择实现
open_spider(self,spider)
表示当spider被开启的时候调用这个方法
close_spider(self,spider)
当spider挂去年比时候这个方法被调用
from_crawler(cls,crawler)
这个和我们在前面说spider的时候的用法是一样的,可以用于获取settings配置文件中的信息,需要注意的这个是一个类方法,用法例子如下:
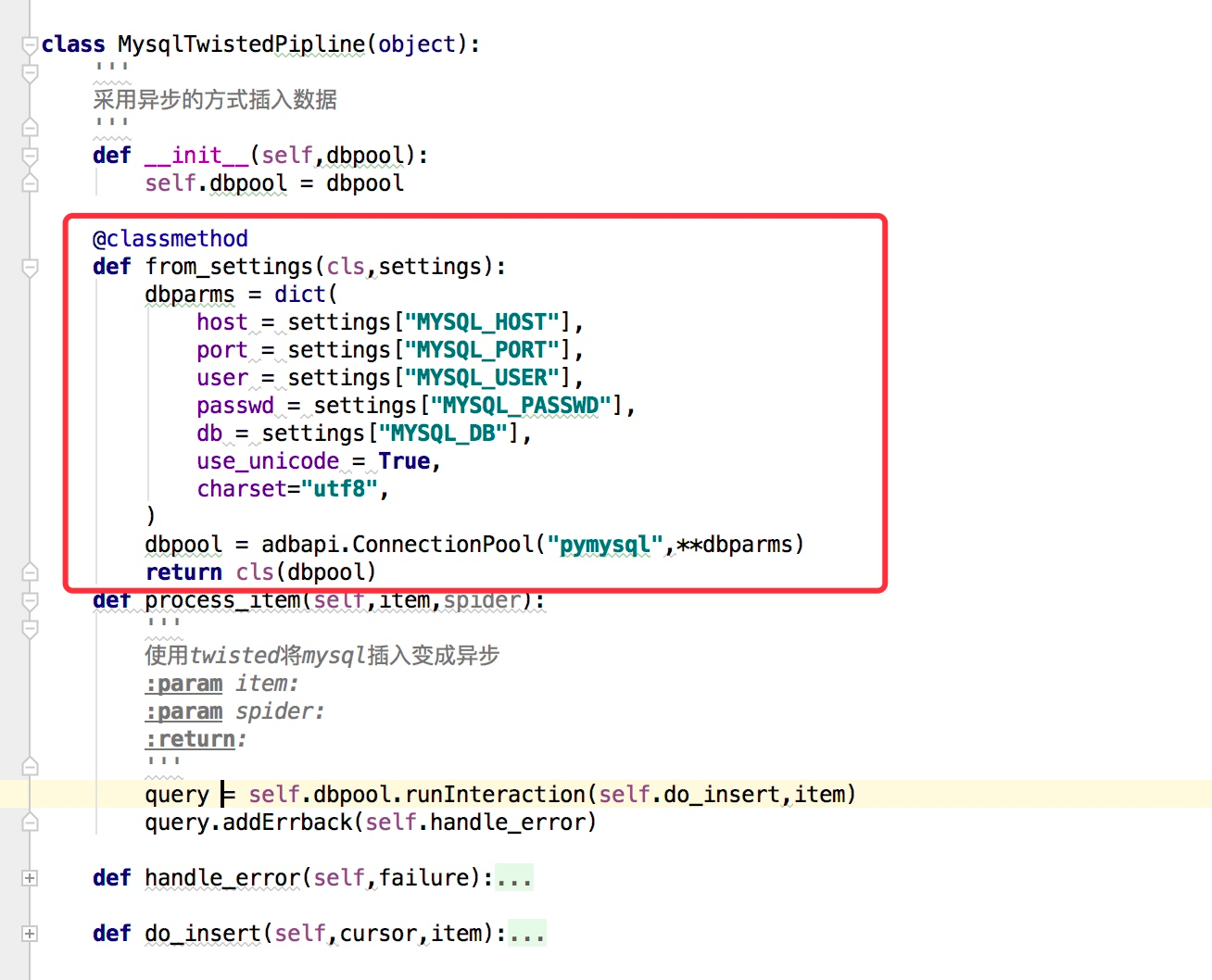
一些item pipeline的使用例子(官网说明)
例子1
这个例子实现的是判断item中是否包含price以及price_excludes_vat,如果存在则调整了price属性,都让item['price'] = item['price'] * self.vat_factor,如果不存在则返回DropItem
from scrapy.exceptions import DropItem
class PricePipeline(object):
vat_factor = 1.15
def process_item(self, item, spider):
if item['price']:
if item['price_excludes_vat']:
item['price'] = item['price'] * self.vat_factor
return item
else:
raise DropItem("Missing price in %s" % item)
例子2
这个例子是将item写入到json文件中
import json
class JsonWriterPipeline(object):
def __init__(self):
self.file = open('items.jl', 'wb')
def process_item(self, item, spider):
line = json.dumps(dict(item)) + "\n"
self.file.write(line)
return item
例子3
将item写入到MongoDB,同时这里演示了from_crawler的用法
import pymongo
class MongoPipeline(object):
collection_name = 'scrapy_items'
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DATABASE', 'items')
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def close_spider(self, spider):
self.client.close()
def process_item(self, item, spider):
self.db[self.collection_name].insert(dict(item))
return item
例子4:去重
一个用于去重的过滤器,丢弃那些已经被处理过的item,假设item有一个唯一的id,但是我们spider返回的多个item中包含了相同的id,去重方法如下:这里初始化了一个集合,每次判断id是否在集合中已经存在,从而做到去重的功能
from scrapy.exceptions import DropItem
class DuplicatesPipeline(object):
def __init__(self):
self.ids_seen = set()
def process_item(self, item, spider):
if item['id'] in self.ids_seen:
raise DropItem("Duplicate item found: %s" % item)
else:
self.ids_seen.add(item['id'])
return item
启用一个item Pipeline组件
在settings配置文件中y9ou一个ITEM_PIPELINES的配置参数,例子如下:
ITEM_PIPELINES = {
'myproject.pipelines.PricePipeline': 300,
'myproject.pipelines.JsonWriterPipeline': 800,
}
每个pipeline后面有一个数值,这个数组的范围是0-1000,这个数值确定了他们的运行顺序,数字越小越优先
scrapy框架中Item Pipeline用法的更多相关文章
- Python爬虫从入门到放弃(十六)之 Scrapy框架中Item Pipeline用法
当Item 在Spider中被收集之后,就会被传递到Item Pipeline中进行处理 每个item pipeline组件是实现了简单的方法的python类,负责接收到item并通过它执行一些行为, ...
- Python之爬虫(十八) Scrapy框架中Item Pipeline用法
当Item 在Spider中被收集之后,就会被传递到Item Pipeline中进行处理 每个item pipeline组件是实现了简单的方法的python类,负责接收到item并通过它执行一些行为, ...
- 6-----Scrapy框架中Item Pipeline用法
当Item 在Spider中被收集之后,就会被传递到Item Pipeline中进行处理 每个item pipeline组件是实现了简单的方法的python类,负责接收到item并通过它执行一些行为, ...
- Scrapy框架中选择器的用法【转】
Python爬虫从入门到放弃(十四)之 Scrapy框架中选择器的用法 请给作者点赞 --> 原文链接 Scrapy提取数据有自己的一套机制,被称作选择器(selectors),通过特定的Xpa ...
- scrapy框架中Download Middleware用法
scrapy框架中Download Middleware用法 Downloader Middleware处理的过程主要在调度器发送requests请求的时候以及网页将response结果返回给sp ...
- scrapy框架中选择器的用法
scrapy框架中选择器的用法 Scrapy提取数据有自己的一套机制,被称作选择器(selectors),通过特定的Xpath或者CSS表达式来选择HTML文件的某个部分Xpath是专门在XML文件中 ...
- Scrapy框架中的Pipeline组件
简介 在下图中可以看到items.py与pipeline.py,其中items是用来定义抓取内容的实体:pipeline则是用来处理抓取的item的管道 Item管道的主要责任是负责处理有蜘蛛从网页中 ...
- Python爬虫从入门到放弃(十四)之 Scrapy框架中选择器的用法
Scrapy提取数据有自己的一套机制,被称作选择器(selectors),通过特定的Xpath或者CSS表达式来选择HTML文件的某个部分Xpath是专门在XML文件中选择节点的语言,也可以用在HTM ...
- Python之爬虫(十六) Scrapy框架中选择器的用法
Scrapy提取数据有自己的一套机制,被称作选择器(selectors),通过特定的Xpath或者CSS表达式来选择HTML文件的某个部分Xpath是专门在XML文件中选择节点的语言,也可以用在HTM ...
随机推荐
- 对于pod导入第三方库文件终端语言记录
//换成 pod install --verbose --no-repo-update //生成Podfile文件 touch Podfile 加上--verbose --no-repo-update ...
- ubuntu安装ros indigo
版本是14.04.1 一.先配置 1.点击新立得软件包管理器,输入密码exbot123, 2,点击最上面一栏的设置,选择软件源,前四个打勾,后一个不打,把sevice america改成mainsev ...
- Appium——adb 启动问题Invalid argument: cannot open transport registration socketpair could not read ok from ADB Server failed to start daemon * error: cannot connect to daemon
adb启动问题:Invalid argument: cannot open transport registration socketpair could not read ok from ADB S ...
- Windows内存性能分析(一)内存泄漏
判断内存性能表现主要是为了解决如下两个问题: 1. 当前web应用是否存在内存泄漏,如果有,问题的程度有多大? 2. 如果web应用的代码无法进一步改进,当前web应用所在的服务器是否存在内存上的瓶颈 ...
- 解决Spring MVC中文乱码
在web.xml中设置编码过滤器 <filter> <filter-name>characterEncodingFilter</filter-name> <f ...
- coeforces 665D D. Simple Subset(最大团orsb题)
题目链接: D. Simple Subset time limit per test 1 second memory limit per test 256 megabytes input standa ...
- 多线程之:lock和synchronized的区别
多次思考过这个问题,都没有形成理论,今天有时间了,我把他总结出来,希望对大家有所帮助 1.ReentrantLock 拥有Synchronized相同的并发性和内存语义,此外还多了 锁投票,定时锁等候 ...
- 阻止Eclipse一直building workspace
Eclipse 一直不停 building workspace完美解决总结 一.产生这个问题的原因多种 1.自动升级 2.未正确关闭 3.maven下载lib挂起 等.. 二.解决总结 (1).解决方 ...
- darknet源码学习
darknet是一个较为轻型的完全基于C与CUDA的开源深度学习框架,其主要特点就是容易安装,没有任何依赖项(OpenCV都可以不用),移植性非常好,支持CPU与GPU两种计算方式.1.test源码( ...
- SQL Server 2008将数据导出为脚本 [SQL Server]
之前我们要将一个表中的数据导出为脚本,那么只有在网上找一个导出数据的Script,然后运行就可以导出数据脚本了.现在在SQL Server 2008的Management Studio中增加了一个新特 ...