Python之爬虫(十八) Scrapy框架中Item Pipeline用法
当Item 在Spider中被收集之后,就会被传递到Item Pipeline中进行处理
每个item pipeline组件是实现了简单的方法的python类,负责接收到item并通过它执行一些行为,同时也决定此Item是否继续通过pipeline,或者被丢弃而不再进行处理
item pipeline的主要作用:
- 清理html数据
- 验证爬取的数据
- 去重并丢弃
- 讲爬取的结果保存到数据库中或文件中
编写自己的item pipeline
process_item(self,item,spider)
每个item piple组件是一个独立的pyhton类,必须实现以process_item(self,item,spider)方法
每个item pipeline组件都需要调用该方法,这个方法必须返回一个具有数据的dict,或者item对象,或者抛出DropItem异常,被丢弃的item将不会被之后的pipeline组件所处理
下面的方法也可以选择实现
open_spider(self,spider)
表示当spider被开启的时候调用这个方法
close_spider(self,spider)
当spider挂去年比时候这个方法被调用
from_crawler(cls,crawler)
这个和我们在前面说spider的时候的用法是一样的,可以用于获取settings配置文件中的信息,需要注意的这个是一个类方法,用法例子如下:
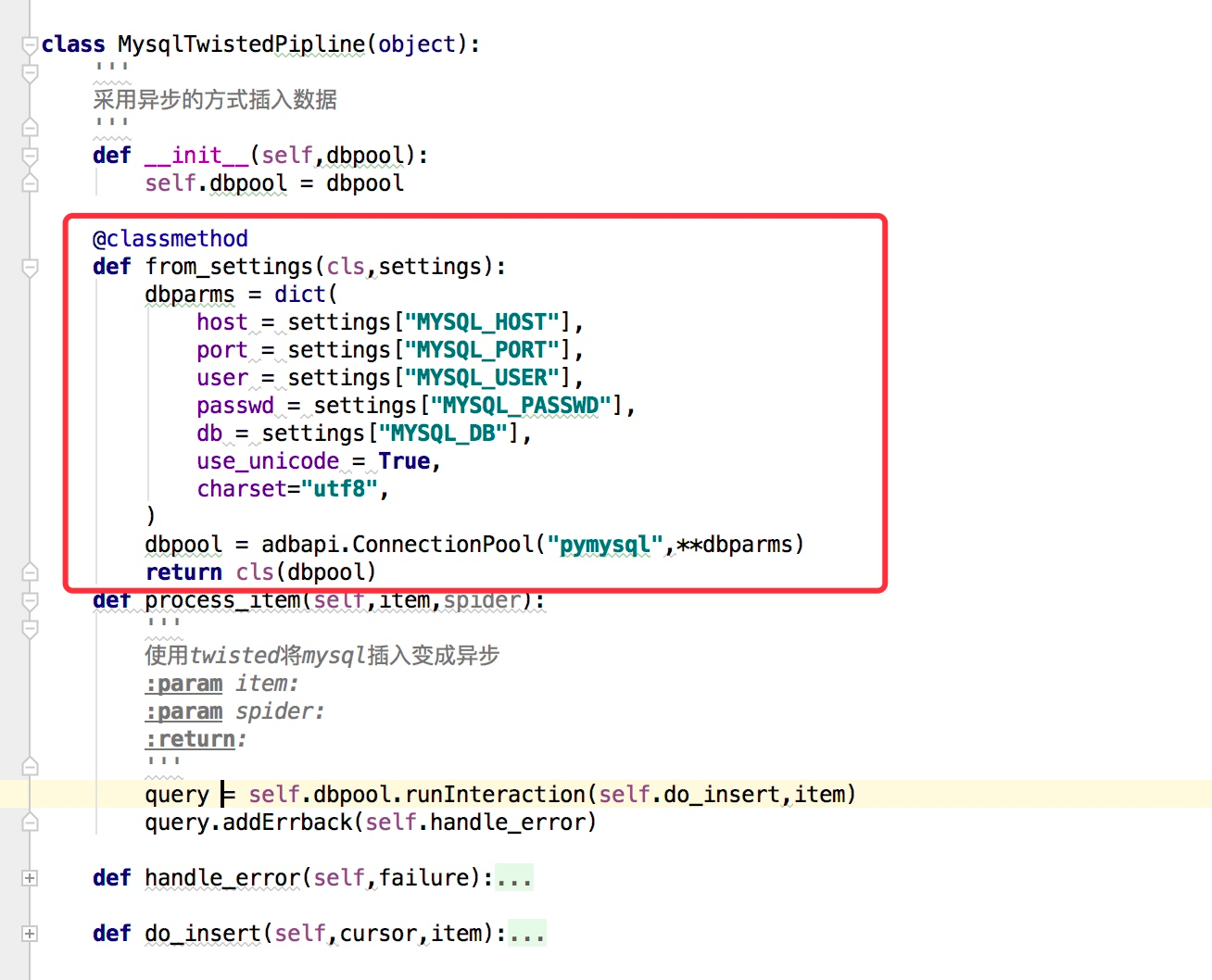
一些item pipeline的使用例子(官网说明)
例子1
这个例子实现的是判断item中是否包含price以及price_excludes_vat,如果存在则调整了price属性,都让item['price'] = item['price'] * self.vat_factor,如果不存在则返回DropItem
from scrapy.exceptions import DropItem
class PricePipeline(object):
vat_factor = 1.15
def process_item(self, item, spider):
if item['price']:
if item['price_excludes_vat']:
item['price'] = item['price'] * self.vat_factor
return item
else:
raise DropItem("Missing price in %s" % item)
例子2
这个例子是将item写入到json文件中
import json
class JsonWriterPipeline(object):
def __init__(self):
self.file = open('items.jl', 'wb')
def process_item(self, item, spider):
line = json.dumps(dict(item)) + "\n"
self.file.write(line)
return item
例子3
将item写入到MongoDB,同时这里演示了from_crawler的用法
import pymongo
class MongoPipeline(object):
collection_name = 'scrapy_items'
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DATABASE', 'items')
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def close_spider(self, spider):
self.client.close()
def process_item(self, item, spider):
self.db[self.collection_name].insert(dict(item))
return item
例子4:去重
一个用于去重的过滤器,丢弃那些已经被处理过的item,假设item有一个唯一的id,但是我们spider返回的多个item中包含了相同的id,去重方法如下:这里初始化了一个集合,每次判断id是否在集合中已经存在,从而做到去重的功能
from scrapy.exceptions import DropItem
class DuplicatesPipeline(object):
def __init__(self):
self.ids_seen = set()
def process_item(self, item, spider):
if item['id'] in self.ids_seen:
raise DropItem("Duplicate item found: %s" % item)
else:
self.ids_seen.add(item['id'])
return item
启用一个item Pipeline组件
在settings配置文件中y9ou一个ITEM_PIPELINES的配置参数,例子如下:
ITEM_PIPELINES = {
'myproject.pipelines.PricePipeline': 300,
'myproject.pipelines.JsonWriterPipeline': 800,
}
每个pipeline后面有一个数值,这个数组的范围是0-1000,这个数值确定了他们的运行顺序,数字越小越优先
Python之爬虫(十八) Scrapy框架中Item Pipeline用法的更多相关文章
- scrapy框架中Item Pipeline用法
scrapy框架中item pipeline用法 当Item 在Spider中被收集之后,就会被传递到Item Pipeline中进行处理 每个item pipeline组件是实现了简单的方法的pyt ...
- Python爬虫从入门到放弃(十六)之 Scrapy框架中Item Pipeline用法
当Item 在Spider中被收集之后,就会被传递到Item Pipeline中进行处理 每个item pipeline组件是实现了简单的方法的python类,负责接收到item并通过它执行一些行为, ...
- 6-----Scrapy框架中Item Pipeline用法
当Item 在Spider中被收集之后,就会被传递到Item Pipeline中进行处理 每个item pipeline组件是实现了简单的方法的python类,负责接收到item并通过它执行一些行为, ...
- Scrapy框架中选择器的用法【转】
Python爬虫从入门到放弃(十四)之 Scrapy框架中选择器的用法 请给作者点赞 --> 原文链接 Scrapy提取数据有自己的一套机制,被称作选择器(selectors),通过特定的Xpa ...
- scrapy框架中Download Middleware用法
scrapy框架中Download Middleware用法 Downloader Middleware处理的过程主要在调度器发送requests请求的时候以及网页将response结果返回给sp ...
- scrapy框架中选择器的用法
scrapy框架中选择器的用法 Scrapy提取数据有自己的一套机制,被称作选择器(selectors),通过特定的Xpath或者CSS表达式来选择HTML文件的某个部分Xpath是专门在XML文件中 ...
- PYTHON网络爬虫与信息提取[scrapy框架应用](单元十、十一)
scrapy 常用命令 startproject 创建一个新的工程 scrapy startproject <name>[dir] genspider 创建一个爬虫 ...
- 转:十八、java中this的用法
http://blog.csdn.net/liujun13579/article/details/7732443 我知道很多朋友都和我一样:在JAVA程序中似乎经常见到“this”,自己也偶尔用到它, ...
- Python之爬虫(十九) Scrapy框架中Download Middleware用法
这篇文章中写了常用的下载中间件的用法和例子.Downloader Middleware处理的过程主要在调度器发送requests请求的时候以及网页将response结果返回给spiders的时候,所以 ...
随机推荐
- map处理:map(str,[1,2,3,4,5,6])
#map(s1,s2)传入两个参数,s1是对该Iterable每个参数做处理的参数,s2是该Iterable print(list(map(str,[1,2,3,4,5,6]))) #map()传入的 ...
- 文本溢出后,隐藏显示"..."和margin边距重叠
一.隐藏加省略 单行文本: overflow: hidden; white-space: nowrap; text-overflow: ellipsis; 多行文本: overflow: hidden ...
- vim中的替换操作
在vim中 :s(substitute)命令用于查找并替换字符串.使用方法如下: :s/<find-this>/<replace-with-this>/<flags> ...
- Cookie 和 Session 关系详解
什么是 Cookie 和 Session ? 什么是 Cookie HTTP Cookie(也叫 Web Cookie或浏览器 Cookie)是服务器发送到用户浏览器并保存在本地的一小块数据,它会在 ...
- Spring系列.事务管理
Spring提供了一致的事务管理抽象.这个抽象是Spring最重要的抽象之一, 它有如下的优点: 为不同的事务API提供一致的编程模型,如JTA.JDBC.Hibernate和MyBatis数据库层 ...
- TopK问题,数组中第K大(小)个元素问题总结
问题描述: 在未排序的数组中找到第 k 个最大的元素.请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素. 面试中常考的问题之一,同时这道题由于解法众多,也是考察时间复杂 ...
- [ C++ ] 勿在浮沙筑高台 —— 内存管理(18~31p) std::alloc
部分内容个人感觉不是特别重要,所以没有记录了.其实还是懒 embedded pointers 把对象的前四字节当指针用. struct obj{ struct obj *free_list_link; ...
- 关于数据库客户端navicat创建新连接失败的问题
如图是navicat创建新连接的截图: 我就有一个疑问了,主机填localhost或者127.0.0.1都是本机,自然是可以连接成功的,那如果填本机的IP地址会怎样呢? 如下图,出现了报错: 说我的访 ...
- 暑假集训Day2 互不侵犯(状压dp)
这又是个状压dp (大型自闭现场) 题目大意: 在N*N的棋盘里面放K个国王,使他们互不攻击,共有多少种摆放方案.国王能攻击到它上下左右,以及左上左下右上右下八个方向上附近的各一个格子,共8个格子. ...
- Vue前端压缩图片
一.在组件包下新建compressImage.js // 压缩图片 // eslint-disable-next-line no-unused-vars export function compres ...