Python爬虫从入门到放弃(十六)之 Scrapy框架中Item Pipeline用法
当Item 在Spider中被收集之后,就会被传递到Item Pipeline中进行处理
每个item pipeline组件是实现了简单的方法的python类,负责接收到item并通过它执行一些行为,同时也决定此Item是否继续通过pipeline,或者被丢弃而不再进行处理
item pipeline的主要作用:
- 清理html数据
- 验证爬取的数据
- 去重并丢弃
- 讲爬取的结果保存到数据库中或文件中
编写自己的item pipeline
process_item(self,item,spider)
每个item piple组件是一个独立的pyhton类,必须实现以process_item(self,item,spider)方法
每个item pipeline组件都需要调用该方法,这个方法必须返回一个具有数据的dict,或者item对象,或者抛出DropItem异常,被丢弃的item将不会被之后的pipeline组件所处理
下面的方法也可以选择实现
open_spider(self,spider)
表示当spider被开启的时候调用这个方法
close_spider(self,spider)
当spider挂去年比时候这个方法被调用
from_crawler(cls,crawler)
这个和我们在前面说spider的时候的用法是一样的,可以用于获取settings配置文件中的信息,需要注意的这个是一个类方法,用法例子如下:
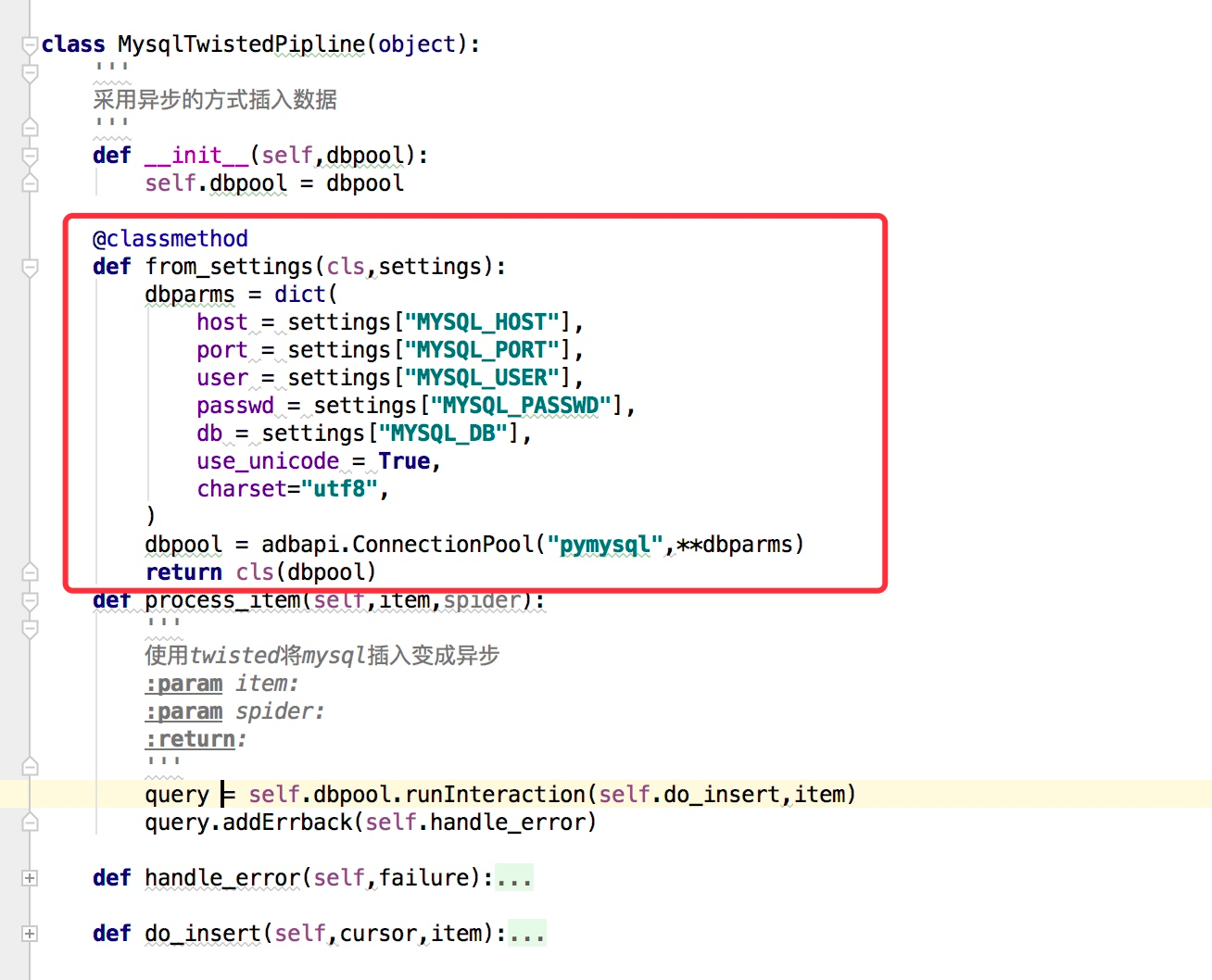
一些item pipeline的使用例子(官网说明)
例子1
这个例子实现的是判断item中是否包含price以及price_excludes_vat,如果存在则调整了price属性,都让item['price'] = item['price'] * self.vat_factor,如果不存在则返回DropItem
from scrapy.exceptions import DropItem
class PricePipeline(object):
vat_factor = 1.15
def process_item(self, item, spider):
if item['price']:
if item['price_excludes_vat']:
item['price'] = item['price'] * self.vat_factor
return item
else:
raise DropItem("Missing price in %s" % item)
例子2
这个例子是将item写入到json文件中
import json
class JsonWriterPipeline(object):
def __init__(self):
self.file = open('items.jl', 'wb')
def process_item(self, item, spider):
line = json.dumps(dict(item)) + "\n"
self.file.write(line)
return item
例子3
将item写入到MongoDB,同时这里演示了from_crawler的用法
import pymongo
class MongoPipeline(object):
collection_name = 'scrapy_items'
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DATABASE', 'items')
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def close_spider(self, spider):
self.client.close()
def process_item(self, item, spider):
self.db[self.collection_name].insert(dict(item))
return item
例子4:去重
一个用于去重的过滤器,丢弃那些已经被处理过的item,假设item有一个唯一的id,但是我们spider返回的多个item中包含了相同的id,去重方法如下:这里初始化了一个集合,每次判断id是否在集合中已经存在,从而做到去重的功能
from scrapy.exceptions import DropItem
class DuplicatesPipeline(object):
def __init__(self):
self.ids_seen = set()
def process_item(self, item, spider):
if item['id'] in self.ids_seen:
raise DropItem("Duplicate item found: %s" % item)
else:
self.ids_seen.add(item['id'])
return item
启用一个item Pipeline组件
在settings配置文件中y9ou一个ITEM_PIPELINES的配置参数,例子如下:
ITEM_PIPELINES = {
'myproject.pipelines.PricePipeline': 300,
'myproject.pipelines.JsonWriterPipeline': 800,
}
每个pipeline后面有一个数值,这个数组的范围是0-1000,这个数值确定了他们的运行顺序,数字越小越优先
Python爬虫从入门到放弃(十六)之 Scrapy框架中Item Pipeline用法的更多相关文章
- Python之爬虫(十八) Scrapy框架中Item Pipeline用法
当Item 在Spider中被收集之后,就会被传递到Item Pipeline中进行处理 每个item pipeline组件是实现了简单的方法的python类,负责接收到item并通过它执行一些行为, ...
- Python之爬虫(十六) Scrapy框架中选择器的用法
Scrapy提取数据有自己的一套机制,被称作选择器(selectors),通过特定的Xpath或者CSS表达式来选择HTML文件的某个部分Xpath是专门在XML文件中选择节点的语言,也可以用在HTM ...
- Python之爬虫从入门到放弃(十三) Scrapy框架整体的了解
这里是通过爬取伯乐在线的全部文章为例子,让自己先对scrapy进行一个整理的理解 该例子中的详细代码会放到我的github地址:https://github.com/pythonsite/spider ...
- python爬虫从入门到放弃(六)之 BeautifulSoup库的使用
上一篇文章的正则,其实对很多人来说用起来是不方便的,加上需要记很多规则,所以用起来不是特别熟练,而这节我们提到的beautifulsoup就是一个非常强大的工具,爬虫利器. beautifulSoup ...
- Python之爬虫(十九) Scrapy框架中Download Middleware用法
这篇文章中写了常用的下载中间件的用法和例子.Downloader Middleware处理的过程主要在调度器发送requests请求的时候以及网页将response结果返回给spiders的时候,所以 ...
- Python爬虫开发【第1篇】【Scrapy框架】
Scrapy 框架介绍 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架. Srapy框架,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以 ...
- Python爬虫从入门到放弃(十二)之 Scrapy框架的架构和原理
这一篇文章主要是为了对scrapy框架的工作流程以及各个组件功能的介绍 Scrapy目前已经可以很好的在python3上运行Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是 ...
- Python爬虫从入门到放弃(十九)之 Scrapy爬取所有知乎用户信息(下)
在上一篇文章中主要写了关于爬虫过程的分析,下面是代码的实现,完整代码在:https://github.com/pythonsite/spider items中的代码主要是我们要爬取的字段的定义 cla ...
- Python爬虫从入门到放弃(十五)之 Scrapy框架中Spiders用法
Spider类定义了如何爬去某个网站,包括爬取的动作以及如何从网页内容中提取结构化的数据,总的来说spider就是定义爬取的动作以及分析某个网页 工作流程分析 以初始的URL初始化Request,并设 ...
随机推荐
- SQL写操作 设置内容 (数组转字符串)
SQL写操作 设置内容 (数组转字符串) SQL set内容 SQL操作数组转字符串 SQL写操作 set内容 (数组转字符串) [ 封装方法 ] function getSqlSet( $data ...
- C#码农的大数据之路 - 使用Ambari自动化安装HDP2.6(基于Ubuntu16.04)并运行.NET Core编写的MR作业
准备主机 准备3台主机,名称作用如下: 昵称 Fully Qualified Domain Name IP 作用 Ubuntu-Parrot head1.parrot 192.168.9.126 Am ...
- 【小练习02】CSS--网易产品
要求用css和HTML实现下图效果: 代码: <!DOCTYPE html> <html> <head> <meta charset="UTF-8& ...
- 543. Diameter of Binary Tree
https://leetcode.com/problems/diameter-of-binary-tree/#/description Given a binary tree, you need to ...
- (转) Unicode(UTF-8, UTF-16)令人混淆的概念
原文地址:http://www.cnblogs.com/kingcat/archive/2012/10/16/2726334.html 为啥需要Unicode 我们知道计算机其实挺笨的,它只认识010 ...
- JS实现AOP拦截方法调用
//JS实现AOP拦截方法调用function jsAOP(obj,handlers) { if(typeof obj == 'function'){ obj = obj.prot ...
- C语言和go语言之间的交互
一.go代码中使用C代码 go代码中使用C代码,在go语言的函数块中,以注释的方式写入C代码,然后紧跟import "C" 即可在go代码中使用C函数 代码示例: go代码:tes ...
- js判断是否是ie浏览器且给出ie版本
之前懒得写判断ie版本js,因为网上关于这方面的代码太多了,所以从网上拷贝了一个,放到项目上才发现由于时效性的问题,代码不生效.就自己写一个吧. 怎么去看浏览器的内核等信息 ---- js的全局对象w ...
- 移动端响应式布局+rem+calc()
1.媒体查询:@media only screen and (max-width: ) {},在最初做pc端时,使用各种媒体查询,因为pc的屏幕分辨率总共就几种,不嫌麻烦的重复使用类名.有很大的缺陷就 ...
- Centos使用vsfotd配置fpt服务
---恢复内容开始--- vsftp简介 vsftpd 是一个 UNIX 类操作系统上运行的服务器的名字,它可以运行在诸如 Linux, BSD, Solaris, HP-UX 以及 IRIX 上面. ...