python爬虫4猫眼电影的Top100
1 查看网页结构
(1)确定需要抓取的字段
电影名称
电影主演
电影上映时间
电影评分
(2) 分析页面结构
按住f12------->点击右上角(如下图2)---->鼠标点击需要观察的字段
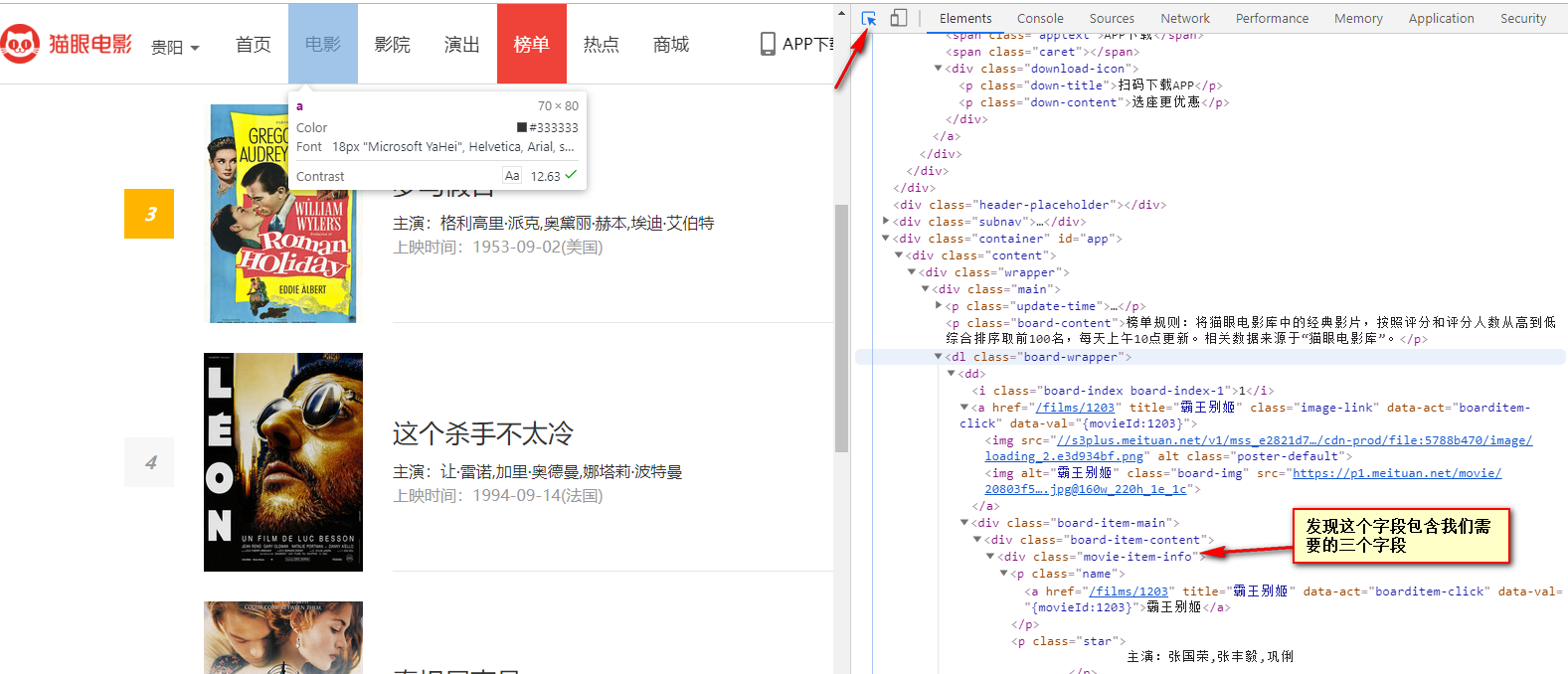
(3)BeautifulSoup解析源代码并设置过滤属性
soup = BeautifulSoup(htmll, 'lxml')
Movie_name = soup.find_all('div',class_='movie-item-info')
Movie_Score1=soup.find_all('p',class_='score')
(4)调试查看过滤属性是否正确

(5)提取对应字段
for cate,score in zip(Movie_name,Movie_Score1):
data={}
movie_name1 = cate.find('a').text.strip('\n')
data['title']=movie_name1
movie_actor = cate.find_all("p")[1].text.replace("\n"," ").strip()
data['actors']=movie_actor
movie_time=cate.find_all("p")[2].text.strip('\n').strip()
data['data']=movie_time
movie_score1=score.find_all("i")[0].string
movie_score2=score.find_all("i")[1].string
movie_score=movie_score1+movie_score2
data['score'] = movie_score
name = movie_name1 + "\t"+movie_actor+"\t" + movie_time+"\t"+movie_score
DATA.append(name)
with open('Movie1.txt', 'a+') as f:
f.write("\n{}".format(name))
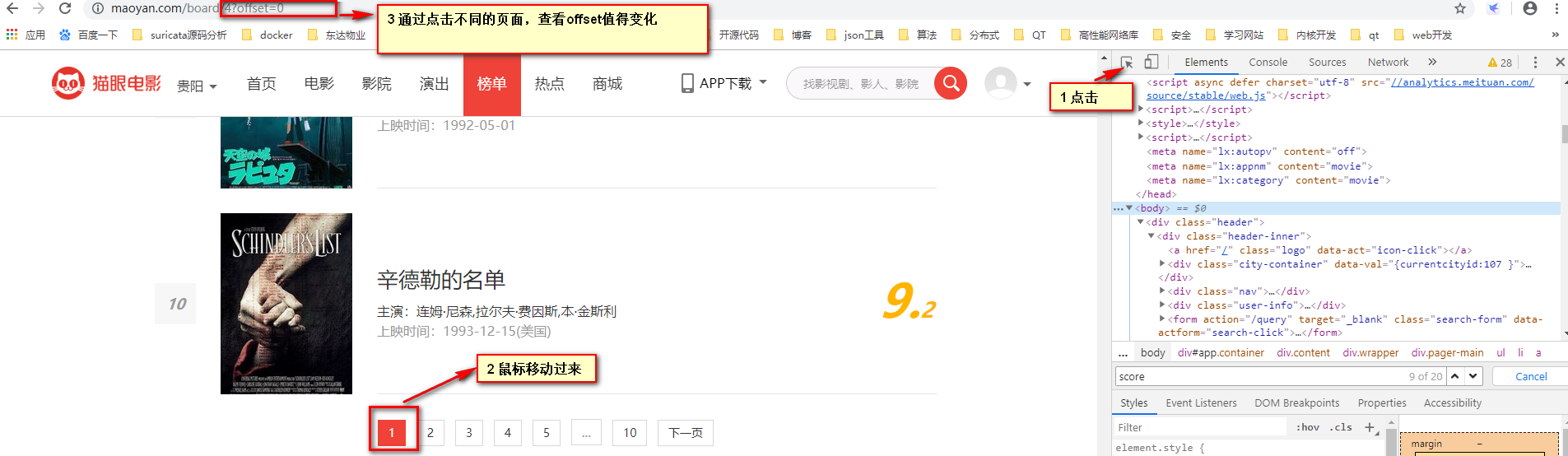
(6)翻页爬取
如下图,按照1 2 3步骤,发现页数是有这样子的规律。比如offset=0 offset=10......

2 存储excel
for datas in DATA:
datas=datas.split('\t')#因为我之前解析字段拼接的时候就是采用\t分割
print(len(datas))
print(datas)
for j in range(len(datas)):#列表中的每一项都包含按照\t分割的字段
print(j)
sheet1.write(i, j, datas[j])
i = i + 1
f.save("d.xls") # 保存文件
3 结果

python爬虫4猫眼电影的Top100的更多相关文章
- python爬取猫眼电影top100
最近想研究下python爬虫,于是就找了些练习项目试试手,熟悉一下,猫眼电影可能就是那种最简单的了. 1 看下猫眼电影的top100页面 分了10页,url为:https://maoyan.com/b ...
- 爬虫系列(1)-----python爬取猫眼电影top100榜
对于Python初学者来说,爬虫技能是应该是最好入门,也是最能够有让自己有成就感的,今天在整理代码时,整理了一下之前自己学习爬虫的一些代码,今天先上一个简单的例子,手把手教你入门Python爬虫,爬取 ...
- python 爬取猫眼电影top100数据
最近有爬虫相关的需求,所以上B站找了个视频(链接在文末)看了一下,做了一个小程序出来,大体上没有修改,只是在最后的存储上,由txt换成了excel. 简要需求:爬虫爬取 猫眼电影TOP100榜单 数据 ...
- Python正则表达式匹配猫眼电影HTML信息
爬虫项目爬取猫眼电影TOP100电影信息 项目内容来自:https://github.com/Germey/MaoYan/blob/master/spider.py 由于其中需要爬取的包含电影名字.电 ...
- Python 爬取猫眼电影最受期待榜
主要爬取猫眼电影最受期待榜的电影排名.图片链接.名称.主演.上映时间. 思路:1.定义一个获取网页源代码的函数: 2.定义一个解析网页源代码的函数: 3.定义一个将解析的数据保存为本地文件的函数: ...
- 【Python3爬虫】猫眼电影爬虫(破解字符集反爬)
一.页面分析 首先打开猫眼电影,然后点击一个正在热播的电影(比如:毒液).打开开发者工具,点击左上角的箭头,然后用鼠标点击网页上的票价,可以看到源码中显示的不是数字,而是某些根本看不懂的字符,这是因为 ...
- Python爬取猫眼电影100榜并保存到excel表格
首先我们前期要导入的第三方类库有; 通过猫眼电影100榜的源码可以看到很有规律 如: 亦或者是: 根据规律我们可以得到非贪婪的正则表达式 """<div class ...
- 用Python爬取猫眼上的top100评分电影
代码如下: # 注意encoding = 'utf-8'和ensure_ascii = False,不写的话不能输出汉字 import requests from requests.exception ...
- 爬虫_猫眼电影top100(正则表达式)
代码查看码云
随机推荐
- 10、Python迭代器与生成器(iterator、for循环、generator、yield)
一.迭代器(foreach) 1.可迭代的对象 内置有__iter__方法的都叫可迭代的对象. Python内置str.list.tuple.dict.set.file都是可迭代对象. x = 1._ ...
- 删除WordPress菜单wp-nav-menu中li的class或id样式
我们都知道wordpress已经集成了一些通用的css样式,比如wp-nav-menu菜单会有很多的class,不想看到那么多的选择器,想要清净的世界要如何操作呢?随ytkah一起来看看 <li ...
- 【游记】CSP2019 垫底记
考试时候的我: Day 1 做完 \(T1\) 和 \(T2\),还有 \(2.5 h\),我想阿克 \(Day1\).(\(T3\):不,你不想) 不过一会就想出来给每个点 dfs 贪心选一个点,然 ...
- maven 使用dependencyManagement统一管理依赖版本
今日思语:人生方方长长,努力把她磨成方圆,所以 加油咯~ 使用maven可以很方便的进行项目依赖的管理,即可以管理我们显示引入具体版本的依赖,也可以管理某些第三方引入的一些依赖的版本,从而能更好的实现 ...
- hdu2643&&hdu2512——斯特林数&&贝尔数
hdu2643 题意:$n$ 个人的排名情况数($n \leq 100$) 分析:考虑 $n$ 个有区别的球放到 $m$ 个有区别的盒子里.无空盒的方案数为 $m!\cdot S(n, m)$. 这题 ...
- 一. python 安装
1. 下载安装包 1 2 3 https://www.python.org/ftp/python/2.7.14/python-2.7.14.amd64.msi # 2.7安装包 https: ...
- 001_Visual Studio 显示数组波形
视频教程:https://v.qq.com/x/page/z3039pr02eh.html 资料下载:https://download.csdn.net/download/xiaoguoge11/12 ...
- urql 高度可自定义&&多功能的react graphql client
urql 是一个很不错的graphql client,使用简单,功能强大,通过exchanges 实现了完整的自定义特性 通过urql 的exchanges 我们可以实现灵活的cache策略 参考资料 ...
- MuPAD使用总结
MuPAD使用总结 一.打开notebook界面的方法: 二.notebook界面的三种区域 (一).输入区域 输入区域在打开来的时候就有,就是,但是之后如果还想再加,可以点击上方红色框内的图标. 这 ...
- CF1172E Nauuo and ODT
CF1172E Nauuo and ODT 神仙题orz 要算所有路径的不同颜色之和,多次修改,每次修改后询问. 对每种颜色\(c\)计算多少条路径包含了这个颜色,不好算所以算多少条路径不包含这个颜色 ...