python爬虫中的ip代理设置
设置ip代理是爬虫必不可少的技巧;
查看本机ip地址;打开百度,输入“ip地址”,可以看到本机的IP地址;
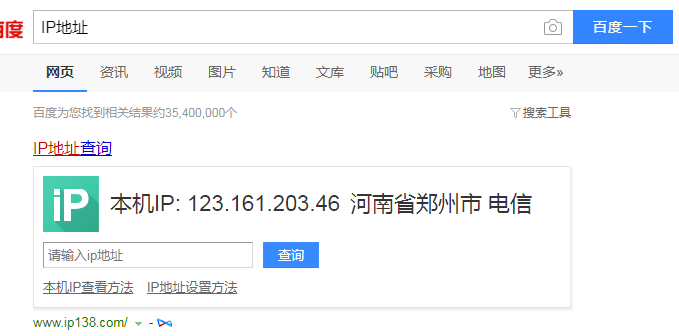
本文使用的是goubanjia.com里面的免费ip;

使用时注意要注意传输协议是http还是https,代码如下;
# 用到的库
import requests
# 写入获取到的ip地址到proxy
proxy = {
'https':'221.178.232.130:8080'
}
# 用百度检测ip代理是否成功
url = 'https://www.baidu.com/s?'
# 请求网页传的参数
params={
'wd':'ip地址'
}
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'
}
# 发送get请求
response = requests.get(url=url,headers=headers,params=params,proxies=proxy)
# 获取返回页面保存到本地,便于查看
with open('ip.html','w',encoding='utf-8') as f:
f.write(response.text)
打开存入的“ip.html”查看内容如下;
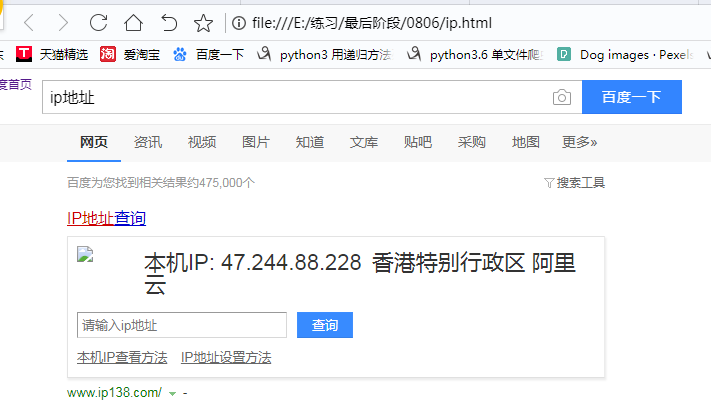
done.
python爬虫中的ip代理设置的更多相关文章
- 反爬虫之搭建IP代理池
反爬虫之搭建IP代理池 听说你又被封 ip 了,你要学会伪装好自己,这次说说伪装你的头部.可惜加了header请求头,加了cookie 还是被限制爬取了.这时就得祭出IP代理池!!! 下面就是requ ...
- scrapy中使用 IP 代理
在 scrapy 中使用 ip 代理需要借助中间件的功能 首先在settings 中设置好中间件,中间件优先级数字越小越先被执行 , } 然后编写中间件,拦截请求设置代理 class ProxyMid ...
- Python爬虫常用小技巧之设置代理IP
设置代理IP的原因 我们在使用Python爬虫爬取一个网站时,通常会频繁访问该网站.假如一个网站它会检测某一段时间某个IP的访问次数,如果访问次数过多,它会禁止你的访问.所以你可以设置一些代理服务器来 ...
- python爬虫简单的添加代理进行访问
在使用python对网页进行多次快速爬取的时候,访问次数过于频繁,服务器不会考虑User-Agent的信息,会直接把你视为爬虫,从而过滤掉,拒绝你的访问,在这种时候就需要设置代理,我们可以给proxi ...
- python爬虫——selenium+chrome使用代理
先看下本文中的知识点: python selenium库安装 chrome webdirver的下载安装 selenium+chrome使用代理 进阶学习 搭建开发环境: selenium库 chro ...
- python爬虫——selenium+firefox使用代理
本文中的知识点: python selenium库安装 firefox geckodriver的下载与安装 selenium+firefox使用代理 进阶学习 搭建开发环境: selenium库 fi ...
- selenium + chromeDriver的ip代理设置
from selenium import webdriver from selenium.webdriver.chrome.options import Options import zipfile ...
- python爬虫中图形验证码的处理
使用python爬虫自动登录时,遇到需要输入图形验证码的情况,一个比较简单的处理方法是使用打码平台识别验证码. 使用过两个打码平台,打码兔和若快,若快的价格更便宜,识别率相当.若快需要注册两个帐号:开 ...
- Python - 定时动态获取IP代理池,存放在文件中
定时功能通过module time + 死循环实现,因为time.sleep()会自动阻塞 get_ip_pool.py """ @__note__: while Tru ...
随机推荐
- Centos7无法播放mp4视频(待验证)
新安装Centos7后,发现无法正常播放本地mp4视频 可以尝试安装 yum -y install ffmpeg 安装之后,需要重启电脑才能生效 浏览器安装年flash,只能播放部分视频,也有可能是s ...
- 【NPDP笔记】第二章 组合管理
2.1 什么是产品组合 Product Portfolio 什么是组合管理,讲述的是完成正确的项目, 五大目标 财务稳健,财务目标 管道平衡,资源需求与可用资源之间的平衡 战略协同,与经营战略 组织战 ...
- 升级libstdc++、libgcc_s.so、libc.so.6
参考资料:https://blog.csdn.net/ltl451011/article/details/7763892/ https://blog.csdn.net/na_beginning/art ...
- 学习数据结构Day1
数据结构的分类: 线性结构 数组:栈:队列:链表:哈希表:... 树结构 二叉树:二分查找树:AVL;红黑树:Treap:Splay:堆:栈:Trie:线段树:K-D树:并查集:哈夫曼 ...
- Linux目录结构(目录结构详解是重点)
1.Linux目录与Windows目录对比 1.Windows目录结构 2.Linux目录结构 深刻理解Linux 树状文件目录是非常重要的,只有记住他们,你才能在命令行中任意切换,想去哪里去哪里 2 ...
- Python之路【第二十篇】:python项目之旧版抽屉新热榜
旧版抽屉新热榜 代码如下: <!DOCTYPE html> <html lang="en"> <head> <meta charset=& ...
- Go语言【开发】加载JSON配置文件
JSON配置加载 辅助网址,JSON转结构体对应 http://json2struct.mervine.net/ 从JSON文件中加载配置到全局变量中 配置文件 config.json { &quo ...
- Go基础编程实践(一)—— 操作字符串
修剪空格 strings包中的TrimSpace函数用于去掉字符串首尾的空格. package main import ( "fmt" "strings" ) ...
- 英语propretie房产
property (英文释义) 英 ['prɒpəti] 美 ['prɑːpərti] n.财产:所有物:地产,房地产:性质:道具 中文名:房产财产地产 外文名:property.propreti ...
- centos 7 搭建 k8s
环境 Centos 7.2 master 192.168.121.101node-1 192.168.121.134node-2 192.168.121.135 Kubernetes集群组件:– et ...