python 爬虫之beautifulsoup(bs4)环境准备
环境准备: bs4安装方法:https://blog.csdn.net/Bibabu135766/article/details/81662981
requests安装方法:https://blog.csdn.net/douguangyao/article/details/77922973 https://pypi.org/project/requests/#files 卸载pip:python -m pip uninstall pip 安装pip:https://pypi.python.org/pypi/pip#downloads
bs4用法介绍:Beautiful Soup和 lxml 一样, 也是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据。
https://www.cnblogs.com/amou/p/9184614.html
https://beautifulsoup.readthedocs.io/zh_CN/latest/
#!/usr/bin/env python
# -*- coding:utf- -*-
from bs4 import BeautifulSoup html = '''
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
'''
#创建Beautiful Soup 对象
soup = BeautifulSoup(html,'lxml')
print soup,"--------------------------------"
# #格式化输出soup对象的内容
# print soup.prettify() #四大对象种类 Tag、NavigableString、BeautifulSoup、Comment
#一、Tag通俗点讲就是 HTML 中的一个个标签
# print soup.html
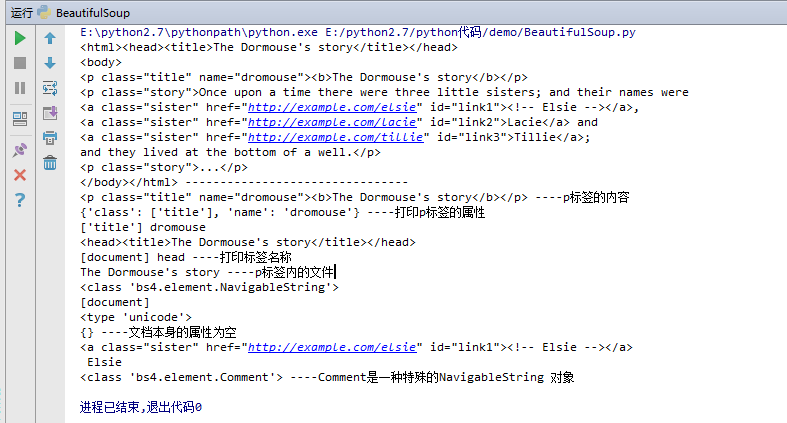
print soup.p,'----p标签的内容'
print soup.p.attrs,'----打印p标签的属性'
print soup.p['class'],soup.p['name']
print soup.head
print soup.name,soup.head.name,'----打印标签名称'
#二、NavigableString 要想获取标签内部的文字怎么办呢?很简单,用 .string 即可
print soup.p.string,'----p标签内的文字'
print type(soup.p.string)
#三、BeautifulSoup 对象表示的是一个文档的内容。大部分时候,可以把它当作 Tag 对象,是一个特殊的 Tag,我们可以分别获取它的类型,名称,以及属性
print soup.name
print type(soup.name)
print soup.attrs,'----文档本身的属性为空'
#四、Comment 对象是一个特殊类型的 NavigableString 对象,其输出的内容不包括注释符号。
print soup.a
print soup.a.string
print type(soup.a.string),'----Comment是一种特殊的NavigableString 对象'
打印结果如下:
BeautifulSoup4查找、正则使用:
#!/usr/bin/env python
# -*- coding:utf- -*-
from bs4 import BeautifulSoup
import resoup = BeautifulSoup(html,'lxml')
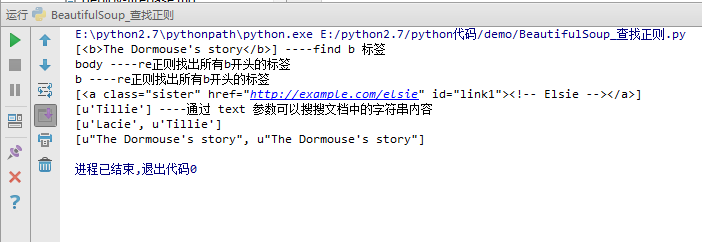
#print soup,'------------html文档--------------' print soup.find_all('b'),'----find b 标签'
for tag in soup.find_all(re.compile('^b')):
print tag.name,'----re正则找出所有b开头的标签'
print soup.find_all(id='link1')
print soup.find_all(text='Tillie'),'----通过 text 参数可以搜搜文档中的字符串内容'
print soup.find_all(text=["Tillie",'Lacie'])
print soup.find_all(text=re.compile('Dormouse'))
打印结果如下:
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
requests用法介绍:
http://docs.python-requests.org/zh_CN/latest/user/quickstart.html
https://cuiqingcai.com/2556.html
python 爬虫之beautifulsoup(bs4)环境准备的更多相关文章
- 使用Python爬虫库BeautifulSoup遍历文档树并对标签进行操作详解(新手必学)
为大家介绍下Python爬虫库BeautifulSoup遍历文档树并对标签进行操作的详细方法与函数下面就是使用Python爬虫库BeautifulSoup对文档树进行遍历并对标签进行操作的实例,都是最 ...
- Python爬虫——用BeautifulSoup、python-docx爬取廖雪峰大大的教程为word文档
版权声明:本文为博主原创文章,欢迎转载,并请注明出处.联系方式:460356155@qq.com 廖雪峰大大贡献的教程写的不错,写了个爬虫把教程保存为word文件,供大家方便下载学习:http://p ...
- 【Python爬虫】BeautifulSoup网页解析库
BeautifulSoup 网页解析库 阅读目录 初识Beautiful Soup Beautiful Soup库的4种解析器 Beautiful Soup类的基本元素 基本使用 标签选择器 节点操作 ...
- Python爬虫之BeautifulSoup的用法
之前看静觅博客,关于BeautifulSoup的用法不太熟练,所以趁机在网上搜索相关的视频,其中一个讲的还是挺清楚的:python爬虫小白入门之BeautifulSoup库,有空做了一下笔记: 一.爬 ...
- python爬虫入门--beautifulsoup
1,beautifulsoup的中文文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/ 2, from bs4 import Be ...
- python爬虫之Beautifulsoup学习笔记
相关内容: 什么是beautifulsoup bs4的使用 导入模块 选择使用解析器 使用标签名查找 使用find\find_all查找 使用select查找 首发时间:2018-03-02 00:1 ...
- Python爬虫系列-BeautifulSoup详解
安装 pip3 install beautifulsoup4 解析库 解析器 使用方法 优势 劣势 Python标准库 BeautifulSoup(markup,'html,parser') Pyth ...
- Python爬虫实践~BeautifulSoup+urllib+Flask实现静态网页的爬取
爬取的网站类型: 论坛类网站类型 涉及主要的第三方模块: BeautifulSoup:解析.遍历页面 urllib:处理URL请求 Flask:简易的WEB框架 介绍: 本次主要使用urllib获取网 ...
- Python爬虫之Beautifulsoup模块的使用
一 Beautifulsoup模块介绍 Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Be ...
随机推荐
- Python高级应用(3)—— 为你的项目添加验证码
验证码简介 验证码的作用: 验证码在现在来说,是很常见的东西,可以一定程度的保护网站,比如防止网络爬虫恶意爬取网站数据啊,减少低级的攻击啊什么的.但是高级点的骚操作还是不太好防范,所以现在的验证码平台 ...
- c/c++ 重载运算符 关系,下标,递增减,成员访问的重载
重载运算符 关系,下标,递增减,成员访问的重载 为了演示关系,下标,递增减,成员访问的重载,创建了下面2个类. 1,类StrBlob重载了关系,下标运算符 2,类StrBlobPtr重载了递增,抵减, ...
- Ubuntukylin 14.04 系统语言改成中文[转]
1.在左侧点击"system setting" 2.按在图中方法设置 3.重启系统 参考地址:http://hi.baidu.com/thj2080/item/ae8e5dce ...
- 使用PlanViz进行ABAP CDS性能分析
如管理学学者彼得·德鲁克所说:你无法管理你不能衡量的东西( If you can't measure it, you can't manage it).要对已有程序进行性能优化,首先要对它的运行状况做 ...
- RabbitMQ持久化
我们知道,如果消息接收端挂了,消息会保存在队列里.下次接收端启动就会接收到消息. 如果RabbitMQ挂了怎么办呢?这时候需要将消息持久化到硬盘 消息发送端:producer ........... ...
- 【Teradata SQL】禁用和启用数据库用户登录
1.禁用数据库用户登录 禁用登录后,再次登录会报用户或密码错误.执行命令如下: //使用dbc用户执行SELECT 'REVOKE LOGON ON ALL FROM '||USERNAME||';' ...
- gpio led学习
2.弄清楚寄存器,gpio等之间的关系,to thi tha 比如: https://www.ggdoc.com/bGludXggZ3Bpb_aTjeS9nA2/NmIzNDIyZGZmMTExZjE ...
- Java注解开发与应用案例
Java注解开发与应用案例 Annotation(注解)是JDK5.0及以后版本引入的,可以对包.类.属性.方法的描述,给被述对象打上标签,被打上标签后的类.属性.方法将被赋予特殊的“功能”:打个比喻 ...
- 采用synchronized关键字写一个显示锁
采用synchronized写一个显示锁 public interface MyLock { void lock () throws InterruptedException; void lock(l ...
- i春秋 百度杯”CTF比赛 十月场 login
出现敏感的信息,然后进行登录 登录成功发现奇怪的show 然后把show放到发包里面试一下 出现了源码,审计代码开始 出flag的条件要user 等于春秋 然后进行login来源于反序列化后的logi ...