如何确定Kafka的分区数、key和consumer线程数
【原创】如何确定Kafka的分区数、key和consumer线程数
def partition(key: Any, numPartitions: Int): Int = {
Utils.abs(key.hashCode) % numPartitions
}
这就保证了相同key的消息一定会被路由到相同的分区。如果你没有指定key,那么Kafka是如何确定这条消息去往哪个分区的呢?

if(key == null) { // 如果没有指定key
val id = sendPartitionPerTopicCache.get(topic) // 先看看Kafka有没有缓存的现成的分区Id
id match {
case Some(partitionId) =>
partitionId // 如果有的话直接使用这个分区Id就好了
case None => // 如果没有的话,
val availablePartitions = topicPartitionList.filter(_.leaderBrokerIdOpt.isDefined) //找出所有可用分区的leader所在的broker
if (availablePartitions.isEmpty)
throw new LeaderNotAvailableException("No leader for any partition in topic " + topic)
val index = Utils.abs(Random.nextInt) % availablePartitions.size // 从中随机挑一个
val partitionId = availablePartitions(index).partitionId
sendPartitionPerTopicCache.put(topic, partitionId) // 更新缓存以备下一次直接使用
partitionId
}
}
可以看出,Kafka几乎就是随机找一个分区发送无key的消息,然后把这个分区号加入到缓存中以备后面直接使用——当然了,Kafka本身也会清空该缓存(默认每10分钟或每次请求topic元数据时)
val nPartsPerConsumer = curPartitions.size / curConsumers.size // 每个consumer至少保证消费的分区数
val nConsumersWithExtraPart = curPartitions.size % curConsumers.size // 还剩下多少个分区需要单独分配给开头的线程们
...
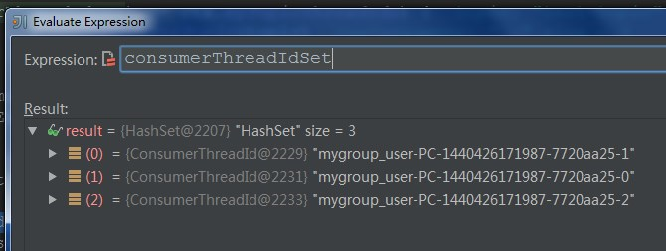
for (consumerThreadId <- consumerThreadIdSet) { // 对于每一个consumer线程
val myConsumerPosition = curConsumers.indexOf(consumerThreadId) //算出该线程在所有线程中的位置,介于[0, n-1]
assert(myConsumerPosition >= 0)
// startPart 就是这个线程要消费的起始分区数
val startPart = nPartsPerConsumer * myConsumerPosition + myConsumerPosition.min(nConsumersWithExtraPart)
// nParts 就是这个线程总共要消费多少个分区
val nParts = nPartsPerConsumer + (if (myConsumerPosition + 1 > nConsumersWithExtraPart) 0 else 1)
...
}
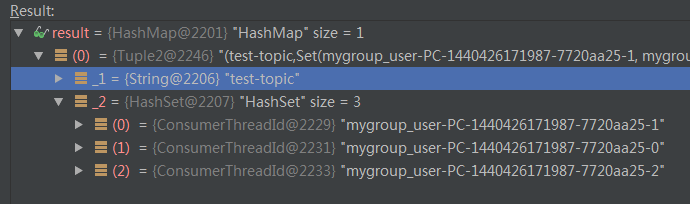
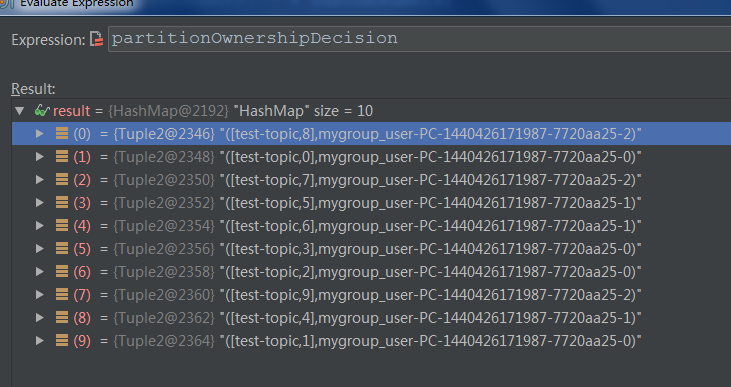
针对于这个例子,nPartsPerConsumer就是10/3=3,nConsumersWithExtraPart为10%3=1,说明每个线程至少保证3个分区,还剩下1个分区需要单独分配给开头的若干个线程。这就是为什么C0消费4个分区,后面的2个线程每个消费3个分区,具体过程详见下面的Debug截图信息:




如何确定Kafka的分区数、key和consumer线程数的更多相关文章
- 【原创】如何确定Kafka的分区数、key和consumer线程数
在Kafak中国社区的qq群中,这个问题被提及的比例是相当高的,这也是Kafka用户最常碰到的问题之一.本文结合Kafka源码试图对该问题相关的因素进行探讨.希望对大家有所帮助. 怎么确定分区数? ...
- 【转】如何确定Kafka的分区数、key和consumer线程数
文章来源:http://www.cnblogs.com/huxi2b/p/4583249.html -------------------------------------------------- ...
- springboot kafka集成(实现producer和consumer)
本文介绍如何在springboot项目中集成kafka收发message. 1.先解决依赖 springboot相关的依赖我们就不提了,和kafka相关的只依赖一个spring-kafka集成包 &l ...
- Apache Kafka - KIP-42: Add Producer and Consumer Interceptors
kafka 0.10.0.0 released Interceptors的概念应该来自flume 参考,http://blog.csdn.net/xiao_jun_0820/article/det ...
- kafka producer自定义partitioner和consumer多线程
为了更好的实现负载均衡和消息的顺序性,Kafka Producer可以通过分发策略发送给指定的Partition.Kafka Java客户端有默认的Partitioner,平均的向目标topic的各个 ...
- Kafka 学习笔记之 Producer/Consumer (Scala)
既然Kafka使用Scala写的,最近也在慢慢学习Scala的语法,虽然还比较生疏,但是还是想尝试下用Scala实现Producer和Consumer,并且用HashPartitioner实现消息根据 ...
- kafka 创建消费者报错 consumer zookeeper is not a recognized option
在做kafka测试的时候,使用命令bin/kafka-console-consumer.sh --zookeeper 192.168.0.140:2181,192.168.0.141:2181 --t ...
- Apache Samza流处理框架介绍——kafka+LevelDB的Key/Value数据库来存储历史消息+?
转自:http://www.infoq.com/cn/news/2015/02/apache-samza-top-project Apache Samza是一个开源.分布式的流处理框架,它使用开源分布 ...
- Kafka 0.10.0.1 consumer get earliest partition offset from Kafka broker cluster - scala code
Return: Map[TopicPartition, Long] Code: val props = new Properties() props.put(ConsumerConfig.BOOTST ...
随机推荐
- docker与虚拟机有何不同
docker与虚拟机有何不同 Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化. 容器技术有 ...
- ubuntu 通过apt安装jdk
需要先添加ppa sudo add-apt-repository ppa:webupd8team/java sudo apt-get update 安装jdk8 sudo apt-get instal ...
- 通过Visual Studio 2012 比较SQL Server 数据库的架构变更
一 需求 随着公司业务的发展,数据库实例也逐渐增多,数据库也会越来越多,有时候我们会发现正式生产数据库也测试数据库数据不一致,也有可能是预发布环境下的数据库与其他数据库架构不一致,或者,分布式数据库上 ...
- python3.x pool.map方法的实质
我使用多进程的一般方式,都是multiprocessing模块中的Pool.map()方法.下面写一个简单的示例和解析.至于此种方法使用多进程的效率问题,还希望大佬予以指正. 示例: "&q ...
- 无法启动mysql服务”1067 进程意外终止”解决办法【简记】
本文章主要是总结了各种导致mysql提示无法启动MYSQL服务”1067 进程意外终止”的一些解决办法,有碰到mysql无法启动的同学可尝试参考. 在win7的服务器里开启MySql服务提示“wind ...
- 我的第一个python web开发框架(22)——一个安全小事故
在周末的一个早上,小白还在做着美梦,就收到了小美的连环追魂call,电话一直响个不停. 小白打着哈欠拿起电话:早上好美女. 小美:出事了出事了,我们公司网站一早访问是一片空白,什么内容都没有了,你赶急 ...
- LivePhoto开发,你要知道的知识点
前言 Apple从iPhone6s开始支持Live Photo.Live Photo 会录下拍照前后 1.5 秒所发生的一切,因此用户获得的不仅仅是一张精美照片,还有拍照前后时刻的动作和声音.具体的操 ...
- 《常见排序算法--PHP实现》
原文地址: 本文地址:http://www.cnblogs.com/aiweixiao/p/8202360.html Original 2018-01-02 关注 微信公众号 程序员的文娱情怀 1.概 ...
- eclipse 创建springboot项目
eclipse创建springboot项目的三种方法: 引自:https://blog.csdn.net/mousede/article/details/81285693
- JS深度判断两个对象字段相同
代码: /** * 判断此对象是否是Object类型 * @param {Object} obj */ function isObject(obj){ return Object.prototype. ...