SQLServer之创建辅助XML索引
创建辅助XML索引
使用 CREATE INDEX (Transact-SQL)Transact-SQL DDL 语句可创建辅助 XML 索引并且可指定所需的辅助 XML 索引的类型。
创建辅助 XML 索引时注意下列事项:
除了 IGNORE_DUP_KEY 和 ONLINE 之外,允许对辅助 XML 索引使用所有适用于非聚集索引的索引选项。 对于辅助 XML 索引,这两个选项必须始终设置为 OFF。
辅助索引的分区方式类似于主 XML 索引。
DROP_EXISTING 可以删除用户表的辅助索引并为用户表创建其他辅助索引。
可以查询 sys.xml_indexes 目录视图来检索 XML 索引信息。 请注意, sys.xml_indexes 目录视图中的 secondary_type_desc 列中提供了辅助索引的类型:secondary_type_desc 列中返回的值可以是 NULL、PATH、VALUE 或 PROPERTY。 对于主 XML 索引而言,返回的值为 NULL。
使用SSMS数据库管理工具创建辅助XML索引
使用表设计器创建辅助XML索引
1、连接数据库,选择数据库,选择数据表-》右键点击表-》选择设计。

2、在表设计器窗口-》选择要添加辅助XML索引的数据列-》右键点击-》选择XML索引。

3、在XML索引弹出框-》点击添加,添加索引-》在常规窗口选择次要类型-》选择值则创建XML值辅助索引,选择属性则创建XML属性辅助索引,选择路径则创建XML路径辅助索引。
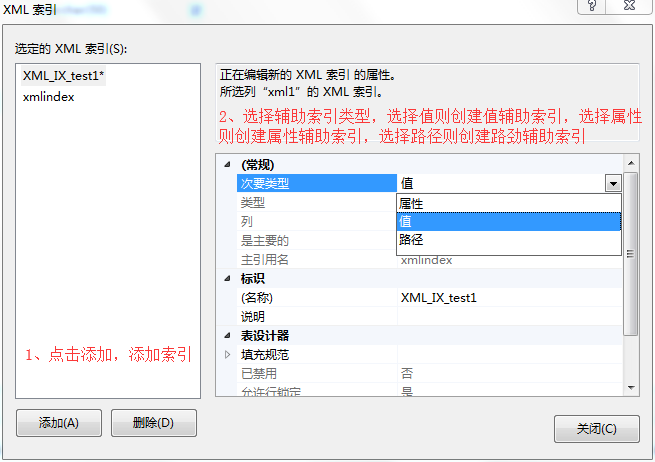
4、在XML索引弹出框-》输入对应的辅助索引名称-》输入对应的辅助索引描述-》表设计部分规则可以选择系统默认也可以自己设置-》点击关闭。
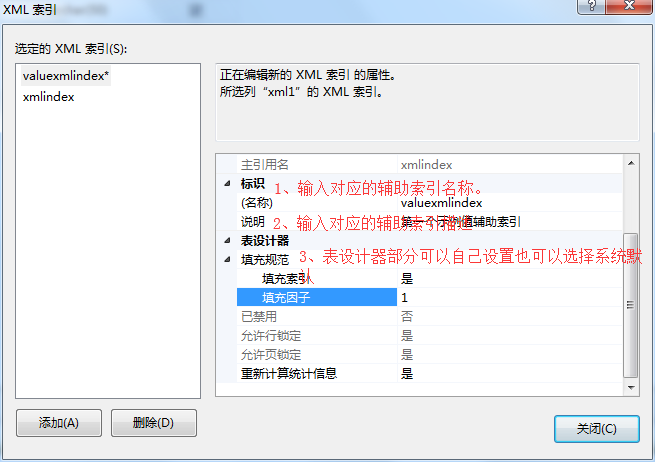
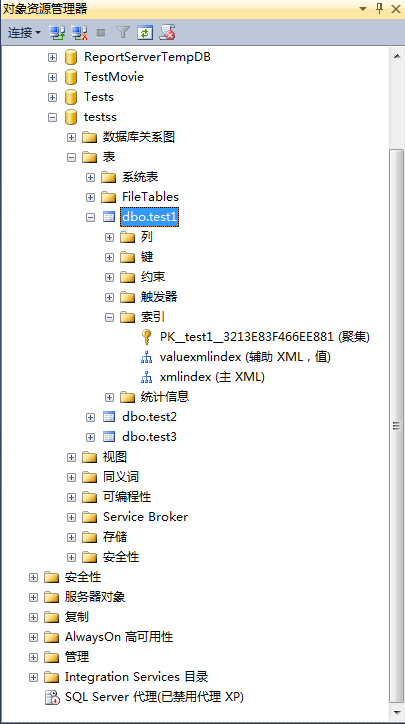
5、点击保存或者使用快捷键ctrl+s-》关闭表设计器-》刷新表-》查看结果。
使用对象资源管理器创建辅助XML索引
1、连接数据库,选择数据库,选择数据表-》展开数据表-》右键点击索引-》选择新建索引-》选择辅助XML索引。
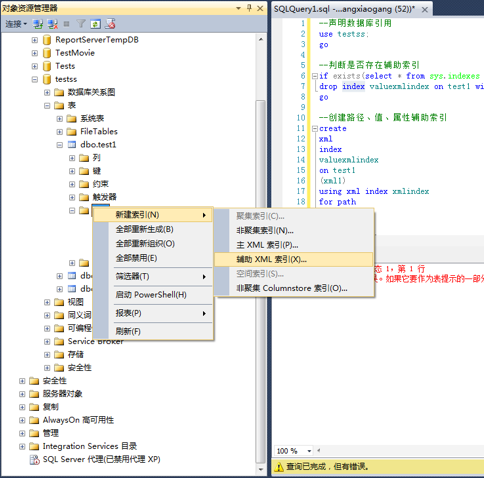
2、在新建索引弹出框-》输入辅助索引名称-》选择主XML索引-》选择辅助XML索引类型。
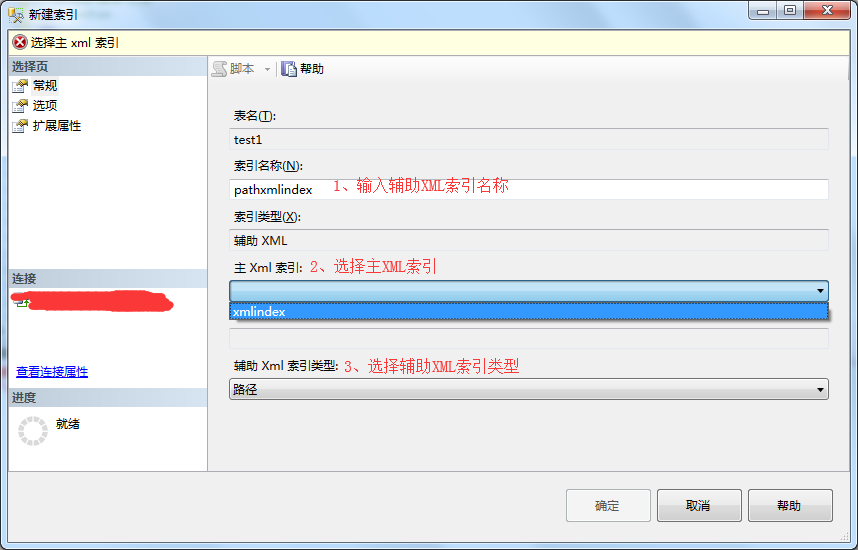
3、在新建索引弹出框-》点击选项修改索引属性-》索引属性可以自己设置也可以选择系统默认。

4、在新建索引弹出框-》点击扩展属性-》输入辅助XML索引描述名称和值-》点击确定。
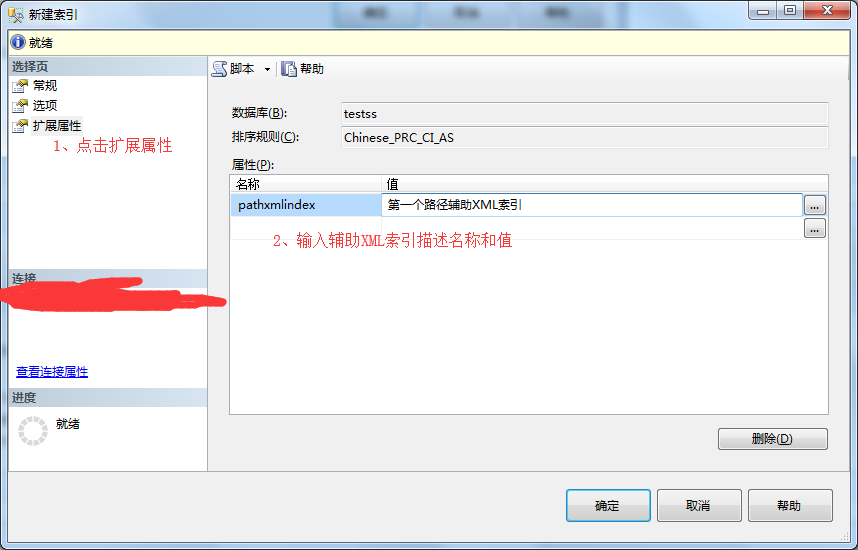
5、不用刷新-》点击展开索引查看创建结果。
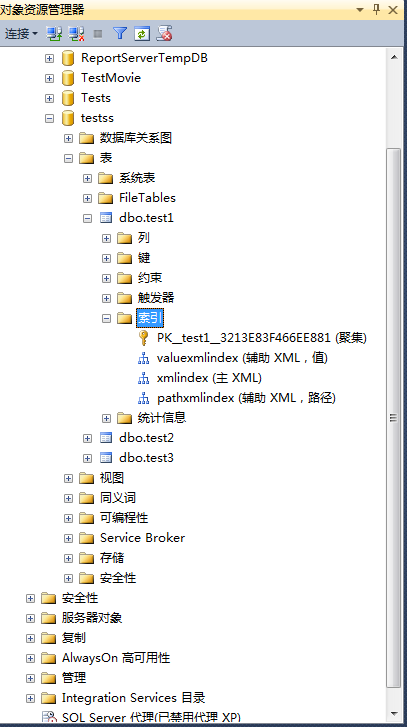
使用T-SQL脚本创建辅助XML索引
语法:
--声明数据库引用
use 数据库名;
go
--判断是否存在辅助索引
if exists(select * from sys.indexes where name=辅助索引名称)
drop index 辅助索引名称 on 表名 with(online=off);
go
--创建路径、值、属性辅助索引
create
xml --声明为XML索引
index --声明创建索引
索引名称--声明创建索引名称
on 表名--声明索引建在哪个表
(列名) --声明索引建在哪个数据列
using xml index 主索引名称 --声明主索引
for { property | path | value } --声明辅助索引类型
with(
--pad_index:指定索引填充
--pad_index=on:FILLFACTOR 指定的可用空间百分比应用于索引的中间级页。
--pad_index=off或未指定 fillfactor:考虑到中间级页上的键集,可以将中间级页几乎填满,但至少要为最大索引行留出足够空间。
pad_index={ on | off },
--fillfactor=n:指定一个百分比,指示在数据库引擎创建或修改索引的过程中,应将每个索引页面的叶级填充到什么程度。 指定的值必须是 1 到 100 之间的整数。 默认值为 0。
fillfactor=n,
--statistics_norecompute:指定是否重新计算统计信息。
--statistics_norecompute=on:过时的统计信息不会自动重新计算。
--statistics_norecompute=off:启用自动统计信息更新。
statistics_norecompute={ on | off },
--sort_in_tempdb:指定是否将排序结果存储在 tempdb 中。
--sort_in_tempdb=on:在tempdb中存储用于生成索引的中间排序结果。如果tempdb与用户数据库不在同一组磁盘上,就可缩短创建索引所需的时间。但是,这会增加索引生成期间所使用的磁盘空间量。
--sort_in_tempdb=off:中间排序结果与索引存储在同一数据库中。
sort_in_tempdb={ on | off },
--drop_existing:表示如果这个索引还在表上就 drop 掉然后在 create 一个新的。 默认为 OFF。
--drop_existing=on:指定要删除并重新生成现有索引,其必须具有相同名称作为参数 index_name。
--drop_existing=off:指定不删除和重新生成现有的索引。 如果指定的索引名称已经存在,SQL Server 将显示一个错误。
drop_existing={ on | off },
--online:指定在索引操作期间基础表和关联的索引是否可用于查询和数据修改操作。 默认为 OFF。 REBUILD 可作为 ONLINE 操作执行。
--online=on:在索引操作期间不持有长期表锁。 在索引操作的主要阶段,源表上只使用意向共享 (IS) 锁。
--这使得能够继续对基础表和索引进行查询或更新。
--操作开始时,在很短的时间内对源对象持有共享 (S) 锁。
--操作结束时,如果创建非聚集索引,将在短期内获取对源的 S(共享)锁;
--当联机创建或删除聚集索引时,以及重新生成聚集或非聚集索引时,将在短期内获取 SCH-M(架构修改)锁。 但联机索引锁是短的元数据锁,特别是 Sch-M 锁必须等待此表上的所有阻塞事务完成。
--在等待期间,Sch-M 锁在访问同一表时阻止在此锁后等待的所有其他事务。 对本地临时表创建索引时,ONLINE 不能设置为 ON。
--online=off:在索引操作期间应用表锁。这样可以防止所有用户在操作期间访问基础表。
--创建、重新生成或删除聚集索引或者重新生成或删除非聚集索引的脱机索引操作将对表获取架构修改 (Sch-M) 锁。
--这样可以防止所有用户在操作期间访问基础表。 创建非聚集索引的脱机索引操作将对表获取共享 (S) 锁。 这样可以防止更新基础表,但允许读操作(如 SELECT 语句)。
online={ on | off },
--aloow_row_locks:指定是否允许行锁。
--allow_row_locks=on:访问索引时允许行锁。数据库引擎确定何时使用行锁。
--allow_row_locks=off:不使用行锁。
allow_row_locks={ on | off },
--allow_page_locks:指定是否允许使用页锁。
--allow_page_locks=on:访问索引时允许页锁。数据库引擎确定何时使用页锁。
-- allow_page_locks=off:不使用页锁。
allow_page_locks={ on | off },
--maxdop=max_degree_of_parallelism:在索引操作期间替代 max degree of parallelism 配置选项。 有关详细信息,请参阅 配置 max degree of parallelism 服务器配置选项。 使用 MAXDOP 可以限制在执行并行计划的过程中使用的处理器数量。 最大数量为 64 个处理器。
--max_degree_of_parallelism 可以是:
--1 - 取消生成并行计划。
-->1 - 将并行索引操作中使用的最大处理器数量限制为指定数量。
--0(默认值)- 根据当前系统工作负荷使用实际数量的处理器或更少数量的处理器。
--有关详细信息,请参阅 配置并行索引操作。
maxdop=max_degree_of_parallelism
)
go
--声明辅助索引描述
execute sys.sp_addextendedproperty N'MS_Description',N'索引描述',N'schema',N'dbo',N'table',N'表名',N'index',N'索引名';
go
示例:
--声明数据库引用
use testss;
go
--判断是否存在辅助索引
if exists(select * from sys.indexes where name='propertyxmlindex')
drop index propertyxmlindex on test1 with(online=off);
go
--创建路径、值、属性辅助索引
create
xml --声明为XML索引
index --声明创建索引
propertyxmlindex --声明创建索引名称
on test1 --声明索引建在哪个表
(xml1) --声明索引建在哪个数据列
using xml index xmlindex --声明主索引
for property --声明辅助索引类型
with(
--pad_index:指定索引填充
--pad_index=on:FILLFACTOR 指定的可用空间百分比应用于索引的中间级页。
--pad_index=off或未指定 fillfactor:考虑到中间级页上的键集,可以将中间级页几乎填满,但至少要为最大索引行留出足够空间。
pad_index=on,
--fillfactor=n:指定一个百分比,指示在数据库引擎创建或修改索引的过程中,应将每个索引页面的叶级填充到什么程度。 指定的值必须是 1 到 100 之间的整数。 默认值为 0。
fillfactor=2,
--statistics_norecompute:指定是否重新计算统计信息。
--statistics_norecompute=on:过时的统计信息不会自动重新计算。
--statistics_norecompute=off:启用自动统计信息更新。
statistics_norecompute=off,
--sort_in_tempdb:指定是否将排序结果存储在 tempdb 中。
--sort_in_tempdb=on:在tempdb中存储用于生成索引的中间排序结果。如果tempdb与用户数据库不在同一组磁盘上,就可缩短创建索引所需的时间。但是,这会增加索引生成期间所使用的磁盘空间量。
--sort_in_tempdb=off:中间排序结果与索引存储在同一数据库中。
sort_in_tempdb=on,
--drop_existing:表示如果这个索引还在表上就 drop 掉然后在 create 一个新的。 默认为 OFF。
--drop_existing=on:指定要删除并重新生成现有索引,其必须具有相同名称作为参数 index_name。
--drop_existing=off:指定不删除和重新生成现有的索引。 如果指定的索引名称已经存在,SQL Server 将显示一个错误。
drop_existing=off,
--online:指定在索引操作期间基础表和关联的索引是否可用于查询和数据修改操作。 默认为 OFF。 REBUILD 可作为 ONLINE 操作执行。
--online=on:在索引操作期间不持有长期表锁。 在索引操作的主要阶段,源表上只使用意向共享 (IS) 锁。
--这使得能够继续对基础表和索引进行查询或更新。
--操作开始时,在很短的时间内对源对象持有共享 (S) 锁。
--操作结束时,如果创建非聚集索引,将在短期内获取对源的 S(共享)锁;
--当联机创建或删除聚集索引时,以及重新生成聚集或非聚集索引时,将在短期内获取 SCH-M(架构修改)锁。 但联机索引锁是短的元数据锁,特别是 Sch-M 锁必须等待此表上的所有阻塞事务完成。
--在等待期间,Sch-M 锁在访问同一表时阻止在此锁后等待的所有其他事务。 对本地临时表创建索引时,ONLINE 不能设置为 ON。
--online=off:在索引操作期间应用表锁。这样可以防止所有用户在操作期间访问基础表。
--创建、重新生成或删除聚集索引或者重新生成或删除非聚集索引的脱机索引操作将对表获取架构修改 (Sch-M) 锁。
--这样可以防止所有用户在操作期间访问基础表。 创建非聚集索引的脱机索引操作将对表获取共享 (S) 锁。 这样可以防止更新基础表,但允许读操作(如 SELECT 语句)。
online=off,
--aloow_row_locks:指定是否允许行锁。
--allow_row_locks=on:访问索引时允许行锁。数据库引擎确定何时使用行锁。
--allow_row_locks=off:不使用行锁。
allow_row_locks=on,
--allow_page_locks:指定是否允许使用页锁。
--allow_page_locks=on:访问索引时允许页锁。数据库引擎确定何时使用页锁。
-- allow_page_locks=off:不使用页锁。
allow_page_locks=on,
--maxdop=max_degree_of_parallelism:在索引操作期间替代 max degree of parallelism 配置选项。 有关详细信息,请参阅 配置 max degree of parallelism 服务器配置选项。 使用 MAXDOP 可以限制在执行并行计划的过程中使用的处理器数量。 最大数量为 64 个处理器。
--max_degree_of_parallelism 可以是:
--1 - 取消生成并行计划。
-->1 - 将并行索引操作中使用的最大处理器数量限制为指定数量。
--0(默认值)- 根据当前系统工作负荷使用实际数量的处理器或更少数量的处理器。
--有关详细信息,请参阅 配置并行索引操作。
maxdop=2
)
go
--声明辅助索引描述
execute sys.sp_addextendedproperty N'MS_Description',N'第一个属性辅助XML索引',N'schema',N'dbo',N'table',N'test1',N'index',N'propertyxmlindex';
go

创建辅助XML索引优缺点
优点:
1、如果工作负荷对 XML 列大量使用路径表达式,则 PATH 辅助 XML 索引可能会提高工作负荷的处理速度。
2、如果工作负荷通过使用路径表达式从单个 XML 实例中检索多个值,则在 PROPERTY 索引中聚集各个 XML 实例中的路径可能会很有用。
3、如果工作负荷涉及查询 XML 实例中的值,但不知道包含那些值的元素名称或属性名称,则您可能希望创建 VALUE 索引。
4、XML 值相对较大,而检索的部分相对较小。生成索引避免了在运行时分析所有数据,并能实现高效的查询处理,从而使索引查找受益。
5、创建辅助XML索引的前提是必须存在主XML索引,辅助XML索引用于增强搜索的性能。
缺点:
1、数据修改过程中的 XML 索引维护开销较大。
SQLServer之创建辅助XML索引的更多相关文章
- SQLServer之创建主XML索引
创建主XML索引注意事项 若要创建主 XML 索引,请使用 CREATE INDEX (Transact-SQL) Transact-SQL DDL 语句. XML 索引不完全支持可用于非 XML 索 ...
- SQLServer之创建唯一聚集索引
创建唯一聚集索引典型实现 唯一索引可通过以下方式实现: PRIMARY KEY 或 UNIQUE 约束 在创建 PRIMARY KEY 约束时,如果不存在该表的聚集索引且未指定唯一非聚集索引,则将自动 ...
- SQLServer之创建非聚集索引
开始之前 典型实现 可以通过下列方法实现非聚集索引: UNIQUE 约束 在创建 UNIQUE 约束时,默认情况下将创建唯一非聚集索引,以便强制 UNIQUE 约束. 如果不存在该表的聚集索引,则可以 ...
- SqlServer中创建非聚集索引和非聚集索引
聚集索引与非聚集索引,其实已经有很多的文章做过详细介绍. 非聚集索引 简单来说,聚集索引是适合字段变动不大(尽可能不出现Update的字段).出现字段重复率小的列,因为聚集索引是对数据物理位置相同的索 ...
- SQLServer之创建索引视图
索引视图创建注意事项 对视图创建的第一个索引必须是唯一聚集索引. 创建唯一聚集索引后,可以创建更多非聚集索引. 为视图创建唯一聚集索引可以提高查询性能,因为视图在数据库中的存储方式与具有聚集索引的表的 ...
- SQLServer之创建唯一非聚集索引
创建唯一非聚集索引典型实现 唯一索引可通过以下方式实现: PRIMARY KEY 或 UNIQUE 约束 在创建 PRIMARY KEY 约束时,如果不存在该表的聚集索引且未指定唯一非聚集索引,则将自 ...
- SQLServer 语句-创建索引
语法:CREATE [索引类型] INDEX 索引名称ON 表名(列名)WITH FILLFACTOR = 填充因子值0~100GO /*实例*/USE 库名GOIF EXISTS (SELECT * ...
- SQLServer 语句-创建索引【转】
语法:CREATE [索引类型] INDEX 索引名称ON 表名(列名)WITH FILLFACTOR = 填充因子值0~100GO /*实例*/USE 库名GOIF EXISTS (SELECT * ...
- SqlServer性能优化 查询和索引优化(十二)
查询优化的过程: 查询优化: 功能:分析语句后最终生成执行计划 分析:获取操作语句参数 索引选择 Join算法选择 创建测试的表: select * into EmployeeOp from Adve ...
随机推荐
- SH2018笔试题之成长值问题
一.题目 详见代码 二.代码 import java.util.Scanner; /** * 3 * 1 1 5 10 * 2 3 4 * 1 4 6 -5 */ public class main4 ...
- Apache生产配置
httpd.conf # # This is the main Apache HTTP server configuration file. It contains the # configurati ...
- C++版- Leetcode 3. Longest Substring Without Repeating Characters解题报告
Leetcode 3. Longest Substring Without Repeating Characters 提交网址: https://leetcode.com/problems/longe ...
- 带着萌新看springboot源码04
继续开头说些废话,我也不知道什么鬼,每次写着写着经常会写到其他地方去了,太容易分神了. 这次说一下springboot对于springmvc的大概整个流程,以请求动态网页为例 . 1.梳理一下spri ...
- 如何用浏览器在线查看.ipynb文件
当我们用jupyter notebook编辑好.ipynb文件后,肯定会想不用运行jupyter notebook也能方便得查看.ipynb的文件,如果直接打开.ipynb的文件,我们 ...
- [解决方案]SystemError: Parent module '' not loaded, cannot perform relative import的解决方案
缺陷:__mian__不能使用相对导入 PEP 328 Relative Imports and __name__ 中说明: Relative imports use a module's __nam ...
- Asp.net Core 项目中如何使用 MongoDB 数据库
内容来源 https://blog.csdn.net/qq_26900081/article/details/83272132 一.添加依赖 1.MongoDB.Driver 2.MongoDB.Bs ...
- WEB项目挂载到IIS session过期
莫名丢失问题: 1.可能是因为系统内部连续的抛出了5次以上的异常 导致进程重启(当前所有在线用户) 2.IIS6 以上默认配置进程,session存在进程内其实是在W3wp.exe中这个进程不稳定,在 ...
- Spring笔记01_下载_概述_监听器
目录 Spring笔记01 1.Spring介绍 1.1 Spring概述 1.2 Spring好处 1.3 Spring结构体系 1.4 在项目中的架构 1.5 程序的耦合和解耦 2. Spring ...
- java开发环境配置——Maven
前篇讲了jdk的安装,这篇讲一下包管理工具Maven,Maven主要是用来统一管理项目引用的jar包,还有用来打包的. Maven官网下载地址:http://maven.apache.org/down ...