七、Hadoop3.3.1 HA 高可用集群QJM (基于Zookeeper,NameNode高可用+Yarn高可用)
前文
- 一、CentOS7 hadoop3.3.1安装(单机分布式、伪分布式、分布式
- 二、JAVA API实现HDFS
- 三、MapReduce编程实例
- 四、Zookeeper3.7安装
- 五、Zookeeper的Shell操作
- 六、Java API操作zookeeper节点
Hadoop3.3.1 HA 高可用集群的搭建
(基于Zookeeper,NameNode高可用+Yarn高可用)
QJM 的 NameNode HA
用Quorum Journal Manager或常规共享存储
QJM的NameNode HA
Hadoop HA模式搭建(高可用)
1、集群规划
一共三台虚拟机,分别为master、worker1、worker2;
namenode三台上都有,resourcemanager在worker1,woker2上。
| master | woker1 | worker2 | |
|---|---|---|---|
| NameNode | yes | yes | yes |
| DataNode | no | yes | yes |
| JournalNode | yes | yes | yes |
| NodeManager | no | yes | yes |
| ResourceManager | no | yes | yes |
| Zookeeper | yes | yes | yes |
| ZKFC | yes | yes | yes |
因为没有重新创建虚拟机,是在原本的基础上修改。所以名称还是hadoop1,hadoop2,hadoop3
hadoop1 = master
hadoop2 = worker1
hadoop3 = worker2
2、Zookeeper集群搭建:
3、修改Hadoop集群配置文件
修改 vim core-site.xml
vim core-site.xml
core-site.xml:
<configuration>
<!-- HDFS主入口,mycluster仅是作为集群的逻辑名称,可随意更改但务必与
hdfs-site.xml中dfs.nameservices值保持一致-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!-- 默认的hadoop.tmp.dir指向的是/tmp目录,将导致namenode与datanode>数据全都保存在易失目录中,此处进行修改-->
<property>
<name>hadoop.tmp.dir</name>
<value>/export/servers/data/hadoop/tmp</value>
</property>
<!--用户角色配置,不配置此项会导致web页面报错-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!--zookeeper集群地址,这里可配置单台,如是集群以逗号进行分隔-->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop1:2181,hadoop2:2181,hadoop3:2181</value>
</property>
<!-- hadoop链接zookeeper的超时时长设置 -->
<property>
<name>ha.zookeeper.session-timeout.ms</name>
<value>1000</value>
<description>ms</description>
</property>
</configuration>
上面指定 zookeeper 地址中的Hadoop1,hadoop2,hadoop3换成你自己机器的主机名(要先配置好主机名与 IP 的映射)或者 ip
修改 hadoop-env.sh
vim hadoop-env.sh
hadoop-env.sh
在使用集群管理脚本的时候,由于使用ssh进行远程登录时不会读取/etc/profile文件中的环境变量配置,所以使用ssh的时候java命令不会生效,因此需要在配置文件中显式配置jdk的绝对路径(如果各个节点的jdk路径不一样的话那hadoop-env.sh中应改成本机的JAVA_HOME)。
hadoop 3.x中对角色权限进行了严格限制,相比于hadoop 2.x要额外对角色的所属用户进行规定。
此处仅为搭建HDFS集群,如果涉及到YARN等内容的话应一并修改对应yarn-env.sh等文件中的配置
在脚本末尾添加以下内容:
export JAVA_HOME=/opt/jdk1.8.0_241
export HDFS_NAMENODE_USER="root"
export HDFS_DATANODE_USER="root"
export HDFS_ZKFC_USER="root"
export HDFS_JOURNALNODE_USER="root"
修改 hdfs-site.xml
vim hdfs-site.xml
hdfs-site.xml
<configuration>
<!-- 指定副本数 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 配置namenode和datanode的工作目录-数据存储目录 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/export/servers/data/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/export/servers/data/hadoop/tmp/dfs/data</value>
</property>
<!-- 启用webhdfs -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<!--指定hdfs的nameservice为cluster1,需要和core-site.xml中的保持一致
dfs.ha.namenodes.[nameservice id]为在nameservice中的每一个NameNode设置唯一标示符。
配置一个逗号分隔的NameNode ID列表。这将是被DataNode识别为所有的NameNode。
例如,如果使用"cluster1"作为nameservice ID,并且使用"nn1"和"nn2"作为NameNodes标示符
-->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- cluster下面有3个NameNode,分别是nn1,nn2,nn3-->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2,nn3</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hadoop1:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>hadoop1:9870</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hadoop2:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hadoop2:9870</value>
</property>
<!-- nn3的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn3</name>
<value>hadoop3:9000</value>
</property>
<!-- nn3的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn3</name>
<value>hadoop3:9870</value>
</property>
<!-- 指定NameNode的edits元数据的共享存储位置。也就是JournalNode列表
该url的配置格式:qjournal://host1:port1;host2:port2;host3:port3/journalId
journalId推荐使用nameservice,默认端口号是:8485 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop1:8485;hadoop2:8485;hadoop3:8485/mycluster</value>
</property>
<!-- 指定JournalNode在本地磁H的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/export/servers/data/hadoop/tmp/journaldata</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<property>
<name>ha.failover-controller.cli-check.rpc-timeout.ms</name>
<value>60000</value>
</property>
<!--指定辅助名称节点-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop3:9868</value>
</property>
</configuration>
要创建journaldata文件夹
workers
在hadoop 2.x中这个文件叫slaves,配置所有datanode的主机地址,只需要把所有的datanode主机名填进去就好了
hadoop1
hadoop2
hadoop3
Yarn高可用
vim mapred-site.xml
修改 mapred-site.xml
<configuration>
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 配置 MapReduce JobHistory Server 地址 ,默认端口10020 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop1:10020</value>
</property>
<!-- 配置 MapReduce JobHistory Server web ui 地址, 默认端口19888 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop1:19888</value>
</property>
</configuration>
vim yarn-site.xml
修改 yarn-site.xml
<configuration>
<!-- 开启RM高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop3</value>
</property>
<!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop1:2181,hadoop2:2181,hadoop2:2181</value>
</property>
<!--Reducer获取数据的方式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--日志聚集功能开启-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!--日志保留时间设置1天-->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property>
<!-- 启用自动恢复 -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 制定resourcemanager的状态信息存储在zookeeper集群上 -->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
</configuration>
都修改好了,就分发给其他集群节点
(在hadoop/etc路径下)
scp /export/servers/hadoop-3.3.1/etc/hadoop/* hadoop2:/export/servers/hadoop-3.3.1/etc/hadoop/
scp /export/servers/hadoop-3.3.1/etc/hadoop/* hadoop3:/export/servers/hadoop-3.3.1/etc/hadoop/
启动zookeeper集群
在每台机器上启动:
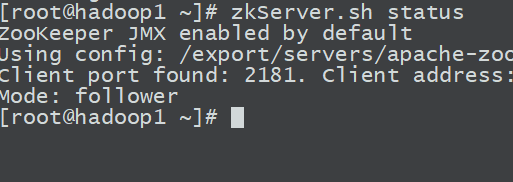
zkServer.sh start
zkServer.sh status
格式化namenode、zkfc
首先,在所有虚拟机上启动journalnode:
hdfs --daemon start journalnode
都启动完毕之后,在master(hadoop1)节点上,格式化namenode
hadoop namenode -format
因为之前搭建过完全分布式,所以格式化一次namenode
但是,集群中的datanode,namenode与/current/VERSION/中的
CuluserID有关所以再次格式化,并启动,其他两个节点同步格式化好的namenode并不冲突
formatZK同理
然后单独启动namenode:
hdfs namenode
然后,在另外两台机器上,同步格式化好的namenode:
hdfs namenode -bootstrapStandby
应该能从master上看到传输信息。
传输完成后,在master节点上,格式化zkfc:
hdfs zkfc -formatZK
启动hdfs
在master节点上,先启动dfs:
start-dfs.sh
然后启动yarn:
start-yarn.sh
启动mapreduce任务历史服务器:
mapred --daemon start historyserver
可以看到各个节点的进程启动情况:
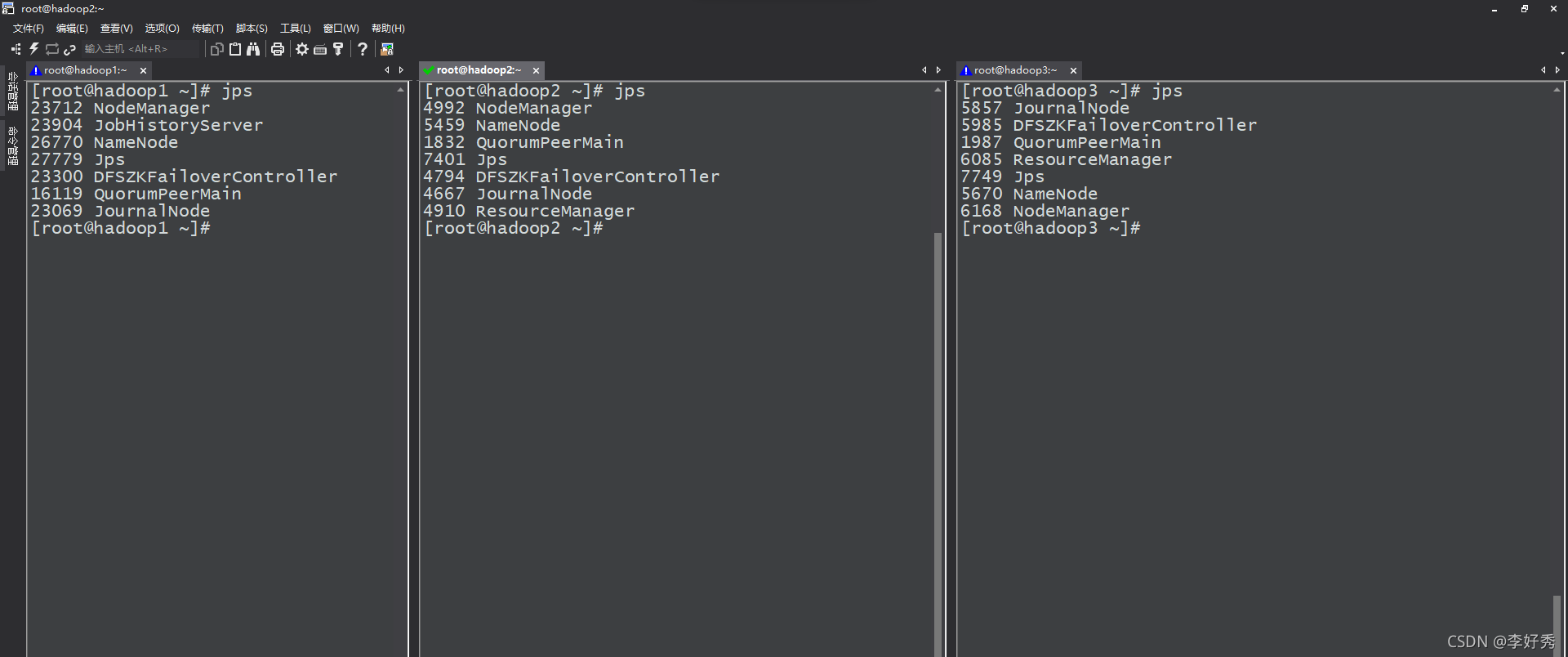
如果datanode未启动
是版本号不一致产生的问题,那么我们就单独解决版本号的问题,将你格式化之后的NameNode的VERSION文件找到,然后将里面的clusterID进行复制,再找到DataNode的VERSION文件,将里面的clusterID进行替换,保存之后重启
尝试HA模式
首先看看各个namenode主机状态:
hdfs haadmin -getServiceState nn1
hdfs haadmin -getServiceState nn2
hdfs haadmin -getServiceState nn3
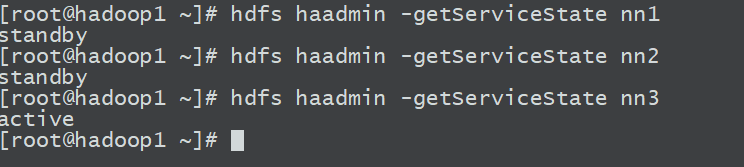
可以看到,有两个standby,一个active。
在active的master节点上,kill掉namenode进程:
此时再次查看节点
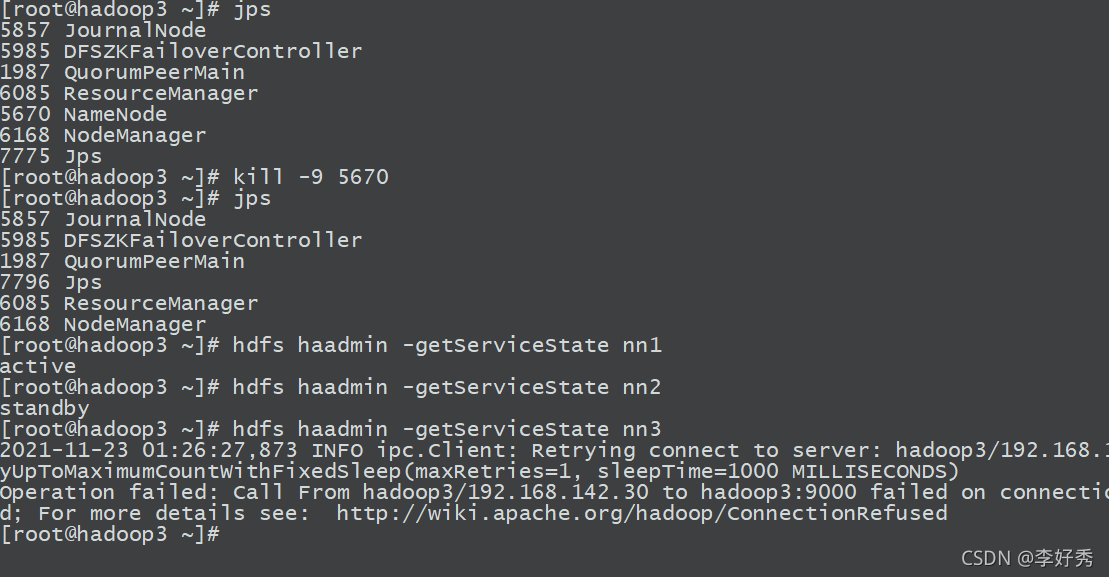
可以看到,nn1已经切换为active,Hadoop 高可用集群基本搭建完成。
七、Hadoop3.3.1 HA 高可用集群QJM (基于Zookeeper,NameNode高可用+Yarn高可用)的更多相关文章
- SolrCloud集群搭建(基于zookeeper)
1. 环境准备 1.1 三台Linux机器,x64系统 1.2 jdk1.8 1.3 Solr5.5 2. 安装zookeeper集群 2.1 分别在三台机器上创建目录 mkdir /usr/hdp/ ...
- Ignite集群管理——基于Zookeeper的节点发现
Ignite支持基于组播,静态IP,Zookeeper,JDBC等方式发现节点,本文主要介绍基于Zookeeper的节点发现. 环境准备,两台笔记本电脑A,B.A笔记本上使用VMware虚拟机安装了U ...
- Corosync+Pacemaker+DRBD+MySQL 实现高可用(HA)的MySQL集群
大纲一.前言二.环境准备三.Corosync 安装与配置四.Pacemaker 安装与配置五.DRBD 安装与配置六.MySQL 安装与配置七.crmsh 资源管理 推荐阅读: Linux 高可用(H ...
- Hadoop入门学习笔记-第三天(Yarn高可用集群配置及计算案例)
什么是mapreduce 首先让我们来重温一下 hadoop 的四大组件:HDFS:分布式存储系统MapReduce:分布式计算系统YARN: hadoop 的资源调度系统Common: 以上三大组件 ...
- SpringCloud(四):服务注册中心Eureka Eureka高可用集群搭建 Eureka自我保护机制
第四章:服务注册中心 Eureka 4-1. Eureka 注册中心高可用集群概述在微服务架构的这种分布式系统中,我们要充分考虑各个微服务组件的高可用性 问题,不能有单点故障,由于注册中心 eurek ...
- Hadoop HA高可用集群搭建(Hadoop+Zookeeper+HBase)
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 一.服务器环境 主机名 IP 用户名 密码 安装目录 master188 192.168.29.188 hadoop hadoop /home/ha ...
- Hadoop 3.1.2(HA)+Zookeeper3.4.13+Hbase1.4.9(HA)+Hive2.3.4+Spark2.4.0(HA)高可用集群搭建
目录 目录 1.前言 1.1.什么是 Hadoop? 1.1.1.什么是 YARN? 1.2.什么是 Zookeeper? 1.3.什么是 Hbase? 1.4.什么是 Hive 1.5.什么是 Sp ...
- linux高可用集群(HA)原理详解(转载)
一.什么是高可用集群 高可用集群就是当某一个节点或服务器发生故障时,另一个 节点能够自动且立即向外提供服务,即将有故障节点上的资源转移到另一个节点上去,这样另一个节点有了资源既可以向外提供服务.高可用 ...
- 高可用集群(HA)配置
高可用集群(HA) 1. 准备工作 HA的心跳监测可以通过串口连接监测也可以通过网线监测,前者需要服务器有一个串口,后者需要有一个空闲网卡.HA架构中需要有一个共享的存储设备首先需要在两台机器上安装m ...
随机推荐
- 【Ubuntu】VirtualBox 您没有查看“sf_VirtualDisk”的内容所需的权限
但是现在发现无法去访问,没有权限: 即使是: crifan@crifan-Ubuntu:~$ sudo chown -R crifan /media/sf_win7_to_ubuntu/ cr ...
- 运行WampServer提示计算机中丢失 msvcr110.dll
在第一次运行WampServer的时候,出现"无法启动此程序,因为计算机中丢失 MSVCR110.dll.尝试重新安装该程序以解决此问题. 在浏览器的地址栏里输入 http://ww ...
- PAT (Basic Level) Practice (中文)1061 判断题 (15分)
1061 判断题 (15分) 判断题的评判很简单,本题就要求你写个简单的程序帮助老师判题并统计学生们判断题的得分. 输入格式: 输入在第一行给出两个不超过 100 的正整数 N 和 M,分别是学生人数 ...
- 如何在印刷品中使用遵循SIL Open Font License协议的字体
如何在印刷品中使用遵循SIL Open Font License协议的字体 昨天在知乎看到了一个问题,( 如何在设计中声明字体开源许可证? - 知乎 (zhihu.com),恰好最近在研究一些开源协议 ...
- javascript-jquery的ajax
用一个例子来说明: html部分 <form action="name1"> <input class="class1" type=&quo ...
- 【UE4 设计模式】策略模式 Strategy Pattern
概述 描述 策略模式定义了一系列的算法,并将每一个算法封装起来,而且使它们还可以相互替换.策略模式让算法的变化不会影响到使用算法的客户. 套路 Context(环境类) 负责使用算法策略,其中维持了一 ...
- 【c++ Prime 学习笔记】第11章 关联容器
关联容器的元素按照关键字来保存和访问,而顺序容器的元素是按照在容器中的位置来保存和访问 关联容器支持高效的关键字查找和访问 2种关联容器: map中的元素是关键字-值对(key-value对),关键字 ...
- 【技术博客】Flutter—使用网络请求的页面搭建流程、State生命周期、一些组件的应用
Flutter-使用网络请求的页面搭建流程.State生命周期.一些组件的应用 使用网络请求的页面搭建流程 在开发APP时,我们常常会遇到如下场景:进入一个页面后,要先进行网络调用,然后使用调用返 ...
- BUAA-软件工程-个人总结与心得
提问回顾以及个人总结 项目 内容 这个作业属于哪个课程 2020春季计算机学院软件工程(罗杰 任健) 这个作业的要求在哪里 提问回顾与个人总结 我在这个课程的目标是 学习软件开发的过程,团队之间的写作 ...
- .NET Core TLS 协议指定被我钻了空子~~~
前言 此前,测试小伙伴通过工具扫描,平台TLS SSL协议支持TLS v1.1,这不安全,TLS SSL协议至少是v1.2以上才行,想到我们早已将其协议仅支持v1.3,那应该非我们平台问题.我依然自信 ...