Algorithm(4th) 1.5 union-find算法
问题描述
问题输入是一对整数对,每个整数都代表一个对象,一对整数”p,q“表示 ”p与q相连“(具有自反性,传递性,对称性,被归到一个等价类里),要求编写程序来筛除在输入时就已经在一个等价类里的整数对。这个算法可以在计算机网络连结方面发挥作用:每个整数相当于计算机,整数对相当于网络间的连结,我们的程序可以判断为了使p,q两个计算机连结,需不需要添加一个新的线路。
具体思想
1.根节点判断
我们可以通过一个“概念上”的森林来实现我们的程序。我们把union-find算法打包成一个类,在其中设置一个名为id的数组用来存放每个节点的下一个连结对象,这样可以通过接受一个数组的秩来不断访问它所连结的下一个对象,直至到一个秩和所存储对象节点号相同的节点(根节点)。而比较两个节点的根节点就可以判断他们是否连在同一个根节点上,进而判断出两个节点是否已经连结。

2.加权连结
如果判断两个节点没有连结到一个根节点,我们就对他们的根节点进行连结。这时就会产生一个问题:p去连q还是q去连p。这里我们采用加权的算法:引入一个数组sz(size)来记录每个节点作为根节点时树中的节点数,把它作为节点的权值。每次进行根节点连结时,我们总是把权值小的根节点连结到权值大的根节点上。这样的好处是可以极大地降低树的高度的增加速度(最大程度降速的方式是把树高度作为权值的加权连结,但经过路径压缩后,这种方式变得没有必要),从而降低查找根节点时的时间量级。在最坏的情况下,要连结的树的大小总是相等的,且都是2的幂,则把所有的N个节点合成一个树,这个树的高度是底数为2的N的对数。
致使查找要检索的高度也达到O(logN)。
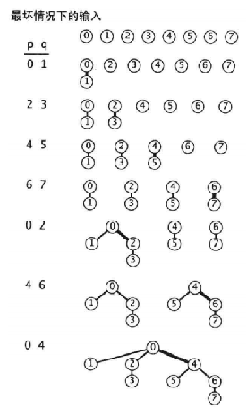
PS:本图取自Algorithm(4th)中译版P146(原版P229)
实现代码
#include<iostream>
#include<vector>
#include<random>
using namespace std;
//WeightedQuickUnion(加权快速连结)
class WQU {
vector<int> id;
vector<int> sz;
int count = 0;
int numberOfSite = 0;
public:
int find(int p);
void Union(int p, int q);
int get_count() { return count; }
bool connected(int p, int q);
int Count(int n);
int newSite();
};
bool WQU::connected(int p, int q) {
if (p >= numberOfSite || q >= numberOfSite) {
throw runtime_error("Site does not exist");
}
return find(p) == find(q);
}
//压缩路径find,递归,只修改查找时经历节点的连结
int WQU::find(int p) {
if (p >= numberOfSite) {
throw runtime_error("Site does not exist");
}
if (p == id[p]) { return p; }
return id[p] = find(id[p]);
}
void WQU::Union(int p, int q) {
if (p >= numberOfSite || q >= numberOfSite) {
throw runtime_error("Site does not exist");
}
int rp = find(p);
int rq = find(q);
if (rp == rq) { return; }
if (sz[rp] < sz[rq]) {
id[rp] = rq;
sz[rq] += sz[rp];
}
else {
id[rq] = rp;
sz[rp] += sz[rq];
}
--count;
}
//测试随机生成数据最终连在一棵树上所需的连结条数
int WQU::Count(int n) {
while (n > numberOfSite) { newSite(); }
while (get_count() != 1) {
int p = rand() % n;
int q = rand() % n;
cout << p << ' ' << q << endl;
if (!connected(p, q)) {
Union(p, q);
}
}
int cnt = 0;
for (size_t i = 0; i < id.size(); ++i) {
if (i != id[i]) {
++cnt;
}
}
return cnt;
}
//创建一个参与连结的新节点,返回它的值
int WQU::newSite() {
id.push_back(numberOfSite);
sz.push_back(1);
++count;
return numberOfSite++;
}
int main() {
int n;
cin >> n;
WQU temp;
cout << temp.Count(n);
return 0;
}
find采用递归压缩路径。在不改变根节点的情况下,令被查找过的节点指向其根节点,从而降低被查找过的节点的深度,进而降低再次查找时的时间复杂度。
Algorithm(4th) 1.5 union-find算法的更多相关文章
- algorithm@ Sieve of Eratosthenes (素数筛选算法) & Related Problem (Return two prime numbers )
Sieve of Eratosthenes (素数筛选算法) Given a number n, print all primes smaller than or equal to n. It is ...
- 普林斯顿大学算法课 Algorithm Part I Week 3 排序算法复杂度 Sorting Complexity
计算复杂度(Computational complexity):用于研究解决特定问题X的算法效率的框架 计算模型(Model of computation):可允许的操作(Allowable oper ...
- Manacher's algorithm: 最长回文子串算法
Manacher 算法是时间.空间复杂度都为 O(n) 的解决 Longest palindromic substring(最长回文子串)的算法.回文串是中心对称的串,比如 'abcba'.'abcc ...
- Weka:call for the EM algorithm to achieve clustering.(EM算法)
EM算法: 在Eclipse中写出读取文件的代码然后调用EM算法计算输出结果: package EMAlg; import java.io.*; import weka.core.*; import ...
- Algorithm: quick sort implemented in python 算法导论 快速排序
import random def partition(A, lo, hi): pivot_index = random.randint(lo, hi) pivot = A[pivot_index] ...
- 维特比算法(Viterbi Algorithm)
寻找最可能的隐藏状态序列(Finding most probable sequence of hidden states) 对于一个特殊的隐马尔科夫模型(HMM)及一个相应的观察序列,我们常常希望 ...
- c/c++ 通用的(泛型)算法 generic algorithm 总览
通用的(泛型)算法 generic algorithm 总览 特性: 1,标准库的顺序容器定义了很少的操作,比如添加,删除等. 2,问题:其实还有很多操作,比如排序,查找特定的元素,替换或删除一个特定 ...
- Latex 算法Algorithm
在计算机科学当中,论文当中经常需要排版算法.相信大家在读论文中也看见了很多排版精美的算法.本文就通过示例来简要介绍一下 algorithms 束的用法.该束主要提供了两个宏包,包含两种进行算法排版的环 ...
- 算法与数据结构基础 - 合并查找(Union Find)
Union Find算法基础 Union Find算法用于处理集合的合并和查询问题,其定义了两个用于并查集的操作: Find: 确定元素属于哪一个子集,或判断两个元素是否属于同一子集 Union: 将 ...
随机推荐
- Java流程控制:顺序结构
一.流程控制 Java中的流程控制语句可以这样分类:顺序结构.选择结构.循环结构.这三种结构就足够解决所有的问题了! 二.顺序结构 描述: Java流程控制的基本结构就是顺序结构,除非特别指明,否则J ...
- CentOS7 安装 MySQL Cluster 7.6.7
引用自:http://lemonlone.com/posts/mysql-ndb-cluster-install/ 仅做备份和配置文件更改 1.先在VMware中安装 CentOS-7-x86_64- ...
- Java 常见对象 03
常见对象·StringBuffer类 StringBuffer类概述 * A:StringBuffer类概述 * 通过 JDk 提供的API,查看StringBuffer类的说明 * 线程安全的可变字 ...
- MVC模式从Controller返回内容协商格式(Json或者Xml)
WebAPI默认的返回格式Json,但是MVC是View,如果在MVC的控制器中,想要返回Json格式该怎么操作呢 在MVC的控制器中返回json数据只需要然会JsonResult而不是ActionR ...
- 设计模式之抽象工厂模式(Abstract Factory Pattern)
一.抽象工厂模式的由来 抽象工厂模式,最开始是为了解决操作系统按钮和窗体风格,而产生的一种设计模式.例如:在windows系统中,我们要用windows设定的按钮和窗体,当我们切换Linux系统时,要 ...
- 源码解析之 Mybatis 对 Integer 参数做了什么手脚?
title: 源码解析之 Mybatis 对 Integer 参数做了什么手脚? date: 2021-03-11 updated: 2021-03-11 categories: Mybatis 源码 ...
- 数数字(JAVA语言)
package 第三章习题; /* * 把前n(n<=10000)个整数顺次写在一起: * 89101112... * 数一数0-9各出现多少次 * (输出10个整数,分别是09出现的次 ...
- Unknown host 'd29vzk4ow07wi7.cloudfront.net'. You may need to adjust the proxy settings in Gradle.
修改项目下build.gradle文件 在jcenter()前添加mavenCentral() 1 // Top-level build file where you can add configur ...
- Detach blobs with a contact point
https://answers.opencv.org/question/87583/detach-blobs-with-a-contact-point/ 一.问题描述 带有接触点的斑点时遇到问题,需要 ...
- SpringBoot-13 Dubbo实战
SpringBoot-13 Dubbo实战 前提: 已经准备好Dubbo-admin和Zookeeper 前置准备 1.创建项目 显示创建一个Empty Project,创建两个Module---&g ...