spark集群
https://blog.csdn.net/boling_cavalry/article/details/86747258
https://www.cnblogs.com/xuliangxing/p/7234014.html
第二个链接较为详细,但版本较旧

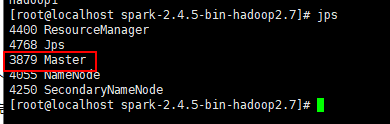
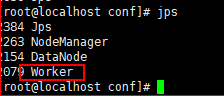
注意spark 7077端口URL,如果hostname没配置正确,spark-submit会报错
jps看了两个slaves是有worker进程的。
spark安装完毕,启动hadoop集群:./sbin/./start-all.sh
jps可查看
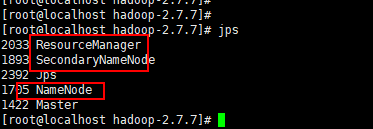
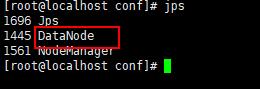
spark提交任务的三种的方法
https://www.cnblogs.com/itboys/p/9998666.html

虚拟机分配内存不足,解决方案参考:https://blog.csdn.net/u012848709/article/details/85425249


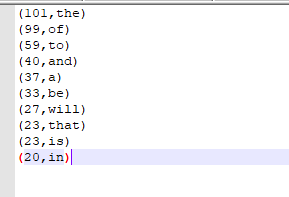
最后终于跑完了,把输出结果get下来
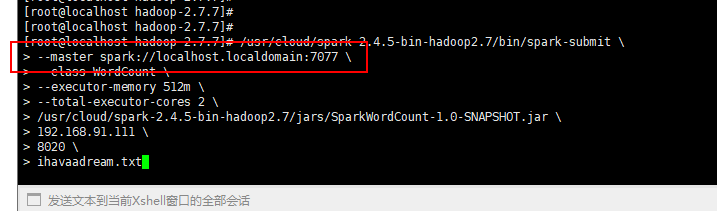
在master输入以下命令,最后三项为入参,9000为hadoop端口:
/usr/cloud/spark-2.4.5-bin-hadoop2.7/bin/spark-submit \
--master spark://192.168.91.111:7077 \
--class WordCount \
--executor-memory 512m \
--total-executor-cores 2 \
/usr/cloud/spark-2.4.5-bin-hadoop2.7/jars/SparkWordCount-1.0-SNAPSHOT.jar \
192.168.91.111 \
9000 \
ihavaadream.txt
=====================WordCount代码如下:======================
import org.apache.commons.lang3.StringUtils;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import scala.Tuple2; import java.text.SimpleDateFormat;
import java.util.Arrays;
import java.util.Date;
import java.util.List; public class WordCount { private static final Logger logger = LoggerFactory.getLogger(WordCount.class); public static void main(String[] args) {
if(null==args
|| args.length<3
|| StringUtils.isEmpty(args[0])
|| StringUtils.isEmpty(args[1])
|| StringUtils.isEmpty(args[2])) {
logger.error("invalid params!");
} String hdfsHost = args[0];
String hdfsPort = args[1];
String textFileName = args[2]; SparkConf sparkConf = new SparkConf().setAppName("Spark WordCount Application (java)"); JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf); String hdfsBasePath = "hdfs://" + hdfsHost + ":" + hdfsPort;
//文本文件的hdfs路径
String inputPath = hdfsBasePath + "/input/" + textFileName; //输出结果文件的hdfs路径
String outputPath = hdfsBasePath + "/output/"
+ new SimpleDateFormat("yyyyMMddHHmmss").format(new Date()); logger.info("input path : {}", inputPath);
logger.info("output path : {}", outputPath); logger.info("import text");
//导入文件
JavaRDD<String> textFile = javaSparkContext.textFile(inputPath); logger.info("do map operation");
JavaPairRDD<String, Integer> counts = textFile
//每一行都分割成单词,返回后组成一个大集合
.flatMap(s -> Arrays.asList(s.split(" ")).iterator())
//key是单词,value是1
.mapToPair(word -> new Tuple2<>(word, 1))
//基于key进行reduce,逻辑是将value累加
.reduceByKey((a, b) -> a + b); logger.info("do convert");
//先将key和value倒过来,再按照key排序
JavaPairRDD<Integer, String> sorts = counts
//key和value颠倒,生成新的map
.mapToPair(tuple2 -> new Tuple2<>(tuple2._2(), tuple2._1()))
//按照key倒排序
.sortByKey(false); // logger.info("take top 10");
//取前10个
List<Tuple2<Integer, String>> top10 = sorts.collect();
// List<Tuple2<Integer, String>> top10 = sorts.take(10); StringBuilder sbud = new StringBuilder("top 10 word :\n"); //打印出来
for(Tuple2<Integer, String> tuple2 : top10){
sbud.append(tuple2._2())
.append("\t")
.append(tuple2._1())
.append("\n");
} logger.info(sbud.toString()); logger.info("merge and save as file");
//分区合并成一个,再导出为一个txt保存在hdfs
javaSparkContext.parallelize(top10).coalesce(1).saveAsTextFile(outputPath); logger.info("close context");
//关闭context
javaSparkContext.close();
}
}
done!
spark集群的更多相关文章
- (四)Spark集群搭建-Java&Python版Spark
Spark集群搭建 视频教程 1.优酷 2.YouTube 安装scala环境 下载地址http://www.scala-lang.org/download/ 上传scala-2.10.5.tgz到m ...
- [bigdata] spark集群安装及测试
在spark安装之前,应该已经安装了hadoop原生版或者cdh,因为spark基本要基于hdfs来进行计算. 1. 下载 spark: http://mirrors.cnnic.cn/apache ...
- Spark集群部署
Spark是通用的基于内存计算的大数据框架,可以和hadoop生态系统很好的兼容,以下来部署Spark集群 集群环境:3节点 Master:bigdata1 Slaves:bigdata2,bigda ...
- Spark集群 + Akka + Kafka + Scala 开发(3) : 开发一个Akka + Spark的应用
前言 在Spark集群 + Akka + Kafka + Scala 开发(1) : 配置开发环境中,我们已经部署好了一个Spark的开发环境. 在Spark集群 + Akka + Kafka + S ...
- Spark集群 + Akka + Kafka + Scala 开发(2) : 开发一个Spark应用
前言 在Spark集群 + Akka + Kafka + Scala 开发(1) : 配置开发环境,我们已经部署好了一个Spark的开发环境. 本文的目标是写一个Spark应用,并可以在集群中测试. ...
- Spark集群 + Akka + Kafka + Scala 开发(1) : 配置开发环境
目标 配置一个spark standalone集群 + akka + kafka + scala的开发环境. 创建一个基于spark的scala工程,并在spark standalone的集群环境中运 ...
- Hadoop+Spark:集群环境搭建
环境准备: 在虚拟机下,大家三台Linux ubuntu 14.04 server x64 系统(下载地址:http://releases.ubuntu.com/14.04.2/ubuntu-14.0 ...
- Spark 个人实战系列(1)--Spark 集群安装
前言: CDH4不带yarn和spark, 因此需要自己搭建spark集群. 这边简单描述spark集群的安装过程, 并讲述spark的standalone模式, 以及对相关的脚本进行简单的分析. s ...
- Spark集群 + Akka + Kafka + Scala 开发(4) : 开发一个Kafka + Spark的应用
前言 在Spark集群 + Akka + Kafka + Scala 开发(1) : 配置开发环境中,我们已经部署好了一个Spark的开发环境. 在Spark集群 + Akka + Kafka + S ...
- 实验室中搭建Spark集群和PyCUDA开发环境
1.安装CUDA 1.1安装前工作 1.1.1选取实验器材 实验中的每台计算机均装有双系统.选择其中一台计算机作为master节点,配置有GeForce GTX 650显卡,拥有384个CUDA核心. ...
随机推荐
- Web自动化测试项目搭建(一) 需求与设计
一.项目需求 测试/生产环境更新后,自动化回归测试 项目易于维护和运行 支持多种测试策略 支持可视化测试报告 运行结果,支持多种方式通知相关人员 可定时/触发的方式运行自动化测试用例 二.设计 2.1 ...
- OpenStack之虚拟机热迁移
这里的环境是centos7版本,openstack K版 1.在各个计算节点设置权限 chmod /var/lib/nova/instances 2.修改各个节点的nova.conf(/etc/nov ...
- AWS的边缘计算平台GreenGrass和IoT
AWS的边缘计算平台GreenGrass和IoT 为什么需要有边缘计算? 如今公有云和私有云平台提供的服务已经连接上了绝大多数的桌面设备和移动设备.但是更多的设备比如,车辆,工程机械,医疗设备,无人机 ...
- Selenium实现微博自动化运营:关注、点赞、评论
目录 Selenium 是什么? 一.核心代码 二.步骤分解 1.打开浏览器 2.访问微博登录页 3.输入账号密码 4.点击登录 5.通过人机验证 6.打开我们的中公题库君首页 7.加一下关注 8.定 ...
- java与c++,python
Java与C++的异同点总结 C++/C/JAVA/Python之间的区别? C++语言与Java语言的区别有哪些? java与C++的区别
- 【Detection】物体识别-制作PASCAL VOC数据集
PASCAL VOC数据集 PASCAL VOC为图像识别和分类提供了一整套标准化的优秀的数据集,从2005年到2012年每年都会举行一场图像识别challenge 默认为20类物体 1 数据集结构 ...
- 一口气说出Redis 5种数据结构及对应使用场景,面试要加分的
整理了一些Java方面的架构.面试资料(微服务.集群.分布式.中间件等),有需要的小伙伴可以关注公众号[程序员内点事],无套路自行领取 更多优选 一口气说出 9种 分布式ID生成方式,面试官有点懵了 ...
- 全网最详细的Linux命令系列-Screen远程会话命令
screen 管理你的远程会话 你是不是经常需要 SSH 或者 telent 远程登录到 Linux 服务器?你是不是经常为一些长时间运行的任务而头疼,比如系统备份.ftp 传输等等.通常情况下我们都 ...
- space transport protocols
VSAT系统对TCP的改进 https://www.vsat-systems.com/broadband-satellite-internet/index.html TCP/IP over satel ...
- malloc返回地址的对齐问题
http://man7.org/linux/man-pages/man3/malloc.3.html RETURN VALUE top The malloc() and calloc( ...