spark集群
https://blog.csdn.net/boling_cavalry/article/details/86747258
https://www.cnblogs.com/xuliangxing/p/7234014.html
第二个链接较为详细,但版本较旧

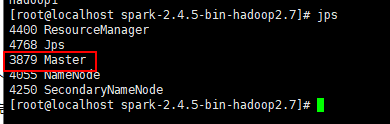
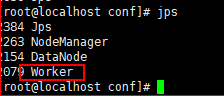
注意spark 7077端口URL,如果hostname没配置正确,spark-submit会报错
jps看了两个slaves是有worker进程的。
spark安装完毕,启动hadoop集群:./sbin/./start-all.sh
jps可查看
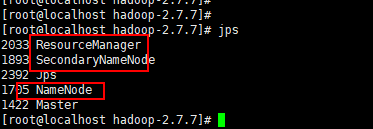
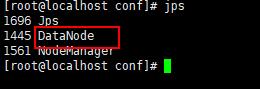
spark提交任务的三种的方法
https://www.cnblogs.com/itboys/p/9998666.html
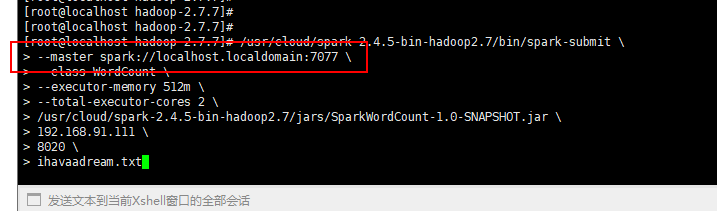

虚拟机分配内存不足,解决方案参考:https://blog.csdn.net/u012848709/article/details/85425249


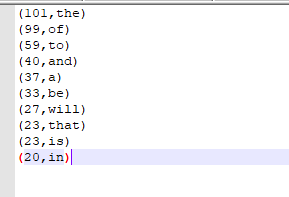
最后终于跑完了,把输出结果get下来
在master输入以下命令,最后三项为入参,9000为hadoop端口:
/usr/cloud/spark-2.4.5-bin-hadoop2.7/bin/spark-submit \
--master spark://192.168.91.111:7077 \
--class WordCount \
--executor-memory 512m \
--total-executor-cores 2 \
/usr/cloud/spark-2.4.5-bin-hadoop2.7/jars/SparkWordCount-1.0-SNAPSHOT.jar \
192.168.91.111 \
9000 \
ihavaadream.txt
=====================WordCount代码如下:======================
import org.apache.commons.lang3.StringUtils;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import scala.Tuple2; import java.text.SimpleDateFormat;
import java.util.Arrays;
import java.util.Date;
import java.util.List; public class WordCount { private static final Logger logger = LoggerFactory.getLogger(WordCount.class); public static void main(String[] args) {
if(null==args
|| args.length<3
|| StringUtils.isEmpty(args[0])
|| StringUtils.isEmpty(args[1])
|| StringUtils.isEmpty(args[2])) {
logger.error("invalid params!");
} String hdfsHost = args[0];
String hdfsPort = args[1];
String textFileName = args[2]; SparkConf sparkConf = new SparkConf().setAppName("Spark WordCount Application (java)"); JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf); String hdfsBasePath = "hdfs://" + hdfsHost + ":" + hdfsPort;
//文本文件的hdfs路径
String inputPath = hdfsBasePath + "/input/" + textFileName; //输出结果文件的hdfs路径
String outputPath = hdfsBasePath + "/output/"
+ new SimpleDateFormat("yyyyMMddHHmmss").format(new Date()); logger.info("input path : {}", inputPath);
logger.info("output path : {}", outputPath); logger.info("import text");
//导入文件
JavaRDD<String> textFile = javaSparkContext.textFile(inputPath); logger.info("do map operation");
JavaPairRDD<String, Integer> counts = textFile
//每一行都分割成单词,返回后组成一个大集合
.flatMap(s -> Arrays.asList(s.split(" ")).iterator())
//key是单词,value是1
.mapToPair(word -> new Tuple2<>(word, 1))
//基于key进行reduce,逻辑是将value累加
.reduceByKey((a, b) -> a + b); logger.info("do convert");
//先将key和value倒过来,再按照key排序
JavaPairRDD<Integer, String> sorts = counts
//key和value颠倒,生成新的map
.mapToPair(tuple2 -> new Tuple2<>(tuple2._2(), tuple2._1()))
//按照key倒排序
.sortByKey(false); // logger.info("take top 10");
//取前10个
List<Tuple2<Integer, String>> top10 = sorts.collect();
// List<Tuple2<Integer, String>> top10 = sorts.take(10); StringBuilder sbud = new StringBuilder("top 10 word :\n"); //打印出来
for(Tuple2<Integer, String> tuple2 : top10){
sbud.append(tuple2._2())
.append("\t")
.append(tuple2._1())
.append("\n");
} logger.info(sbud.toString()); logger.info("merge and save as file");
//分区合并成一个,再导出为一个txt保存在hdfs
javaSparkContext.parallelize(top10).coalesce(1).saveAsTextFile(outputPath); logger.info("close context");
//关闭context
javaSparkContext.close();
}
}
done!
spark集群的更多相关文章
- (四)Spark集群搭建-Java&Python版Spark
Spark集群搭建 视频教程 1.优酷 2.YouTube 安装scala环境 下载地址http://www.scala-lang.org/download/ 上传scala-2.10.5.tgz到m ...
- [bigdata] spark集群安装及测试
在spark安装之前,应该已经安装了hadoop原生版或者cdh,因为spark基本要基于hdfs来进行计算. 1. 下载 spark: http://mirrors.cnnic.cn/apache ...
- Spark集群部署
Spark是通用的基于内存计算的大数据框架,可以和hadoop生态系统很好的兼容,以下来部署Spark集群 集群环境:3节点 Master:bigdata1 Slaves:bigdata2,bigda ...
- Spark集群 + Akka + Kafka + Scala 开发(3) : 开发一个Akka + Spark的应用
前言 在Spark集群 + Akka + Kafka + Scala 开发(1) : 配置开发环境中,我们已经部署好了一个Spark的开发环境. 在Spark集群 + Akka + Kafka + S ...
- Spark集群 + Akka + Kafka + Scala 开发(2) : 开发一个Spark应用
前言 在Spark集群 + Akka + Kafka + Scala 开发(1) : 配置开发环境,我们已经部署好了一个Spark的开发环境. 本文的目标是写一个Spark应用,并可以在集群中测试. ...
- Spark集群 + Akka + Kafka + Scala 开发(1) : 配置开发环境
目标 配置一个spark standalone集群 + akka + kafka + scala的开发环境. 创建一个基于spark的scala工程,并在spark standalone的集群环境中运 ...
- Hadoop+Spark:集群环境搭建
环境准备: 在虚拟机下,大家三台Linux ubuntu 14.04 server x64 系统(下载地址:http://releases.ubuntu.com/14.04.2/ubuntu-14.0 ...
- Spark 个人实战系列(1)--Spark 集群安装
前言: CDH4不带yarn和spark, 因此需要自己搭建spark集群. 这边简单描述spark集群的安装过程, 并讲述spark的standalone模式, 以及对相关的脚本进行简单的分析. s ...
- Spark集群 + Akka + Kafka + Scala 开发(4) : 开发一个Kafka + Spark的应用
前言 在Spark集群 + Akka + Kafka + Scala 开发(1) : 配置开发环境中,我们已经部署好了一个Spark的开发环境. 在Spark集群 + Akka + Kafka + S ...
- 实验室中搭建Spark集群和PyCUDA开发环境
1.安装CUDA 1.1安装前工作 1.1.1选取实验器材 实验中的每台计算机均装有双系统.选择其中一台计算机作为master节点,配置有GeForce GTX 650显卡,拥有384个CUDA核心. ...
随机推荐
- pythonenv的安装及迁移
一.安装 运行 pip install virtualenv 即可安装virtualenv,想用 最新开发版 就运行 二. virtualenv基本使用 $ python virtualenv.py ...
- H5新增特性
1.pattern:写正则,但是需要和form表单连着用 2.WebSocket "网络套接字", 是 HTML5 开始提供的一种在单个 TCP 连接上进行全双工通讯的协议.在 W ...
- Ubuntu安装openjdk8
sudo apt-get update sudo apt-get install openjdk-8-jdk 通过 which java 找到java安装路径 添加环境变量 sudo vim ~/.b ...
- Leetcode 题目整理
1. Two Sum Given an array of integers, return indices of the two numbers such that they add up to a ...
- JVM基础快速入门篇
Java是一门可以跨平台的语言,但是Java本身是不可以实现跨平台的,需要JVM实现跨平台.javac编译好后的class文件,在Windows.Linux.Mac等系统上,只要该系统安装对应的Jav ...
- hive安装启动错误总结
错误一: Exception in thread "main" java.lang.NoClassDefFoundError: jline/console/completer/Ar ...
- Python黑客编程知识点整理
Python转义字符 转义字符 意义 ASCII码值(十进制) \a 响铃(BEL) 007 \b 退格(BS) ,将当前位置移到前一列 008 \f 换页(FF),将当前位置移到下页开头 012 \ ...
- Goland2019.3.2永久破解
2019.11.28 jetbrains公司发布了Go的最强编辑器GoLand 2019.3.本次更新软件消耗更少的CPU和更快的性能,增强了对Go Modules的支持,添加了一组新的快速修复程序, ...
- win10系统安装VMware虚拟机软件以及linux系统
一.安装VMware 1.在VMware官网下载VMware Workstation Pro 15.5.1 下载地址:https://my.vmware.com/cn/web/vmware/detai ...
- css浮动(float)详解
一.什么是浮动? 浮动,顾名思义,就是漂浮的意思.指的是一个元素脱离文档流,悬浮在父元素之上的现象. 二.如何产生浮动? 给元素本身添加float属性 float值: left 元素向左浮动. rig ...