用python+selenium抓取微博24小时热门话题的前15个并保存到txt中
抓取微博24小时热门话题的前15个,抓取的内容请保存至txt文件中,需要抓取排行、话题和阅读数
#coding=utf-8
from selenium import webdriver
import unittest
from time import sleep
class Weibo(unittest.TestCase):
def setUp(self):
self.dr = webdriver.Chrome()
self.hot_list = self.get_weibo_hot_topic()
self.weibo_topic = self.get_top_rank_file()
def get_weibo_hot_topic(self):
self.dr.get('http://weibo.com/')
sleep(5)
self.login('649_xxxx@qq.com','kemi_xxxx') #微博帐号密码
self.dr.get('http://d.weibo.com/100803?cfs=&Pl_Discover_Pt6Rank__5_filter=hothtlist_type%3D1#_0')
sleep(5)
hot_topic_list = []
i = 0
while i < 15:
#rank_and_topic = self.dr.find_elements_by_css_selector('.title.W_autocut')[i].text #定位排行和话题
rank = self.dr.find_elements_by_css_selector('div.title.W_autocut>span')[i].text #定位排行
topic = self.dr.find_elements_by_css_selector('div.title.W_autocut>a.S_txt1')[i].text #定位话题
number = self.dr.find_elements_by_css_selector('.number')[i].text #定位阅读数
hot_topic_list.append([rank, topic, number])
i += 1
return hot_topic_list
def get_top_rank_file(self):
self.file_title = '微博24小时热门话题'
self.file = open(self.file_title + '.txt', 'wb')
for item in self.hot_list:
separate_line = '~~~~~~~~~~~~~~~~~~~~~~~~\n' #分隔线
self.file.write(separate_line.encode('utf-8'))
self.file.write((item[0]+' '+item[1]+' '+'阅读数:'+item[2]+'\n').encode('utf-8'))
self.file.close()
def login(self, username, password):
self.dr.find_element_by_name('username').clear()
self.dr.find_element_by_name('username').send_keys(username)
self.dr.find_element_by_name('password').send_keys(password)
self.dr.find_element_by_css_selector('.info_list.login_btn').click()
def test_weibo_topic(self):
pass
print('抓取完毕')
def tearDown(self):
self.dr.quit()
if __name__== '__main__':
unittest.main()
网页如下:
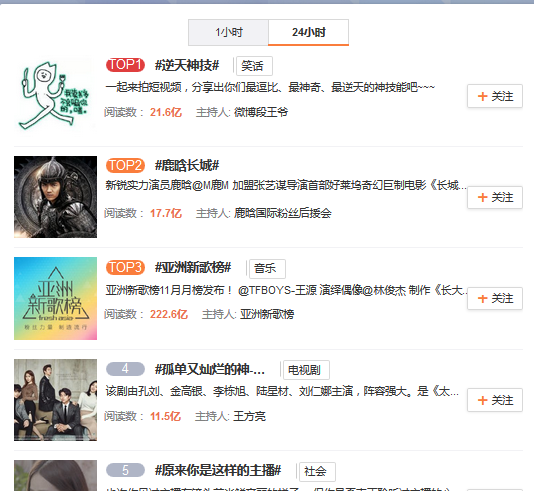
生成txt文件如下:

用python+selenium抓取微博24小时热门话题的前15个并保存到txt中的更多相关文章
- [Python爬虫] 之四:Selenium 抓取微博数据
抓取代码: # coding=utf-8import osimport refrom selenium import webdriverimport selenium.webdriver.suppor ...
- 一篇文章教会你使用Python定时抓取微博评论
[Part1--理论篇] 试想一个问题,如果我们要抓取某个微博大V微博的评论数据,应该怎么实现呢?最简单的做法就是找到微博评论数据接口,然后通过改变参数来获取最新数据并保存.首先从微博api寻找抓取评 ...
- 用python+selenium抓取知乎今日最热和本月最热的前三个问题及每个问题的首个回答并保存至html文件
抓取知乎今日最热和本月最热的前三个问题及每个问题的首个回答,保存至html文件,该html文件的文件名应该是20160228_zhihu_today_hot.html,也就是日期+zhihu_toda ...
- 用python+selenium抓取豆瓣读书中最受关注图书并按评分排序
抓取豆瓣读书中的(http://book.douban.com/)最受关注图书,按照评分排序,并保存至txt文件中,需要抓取书籍的名称,作者,评分,体裁和一句话评 方法一: #coding=utf-8 ...
- 用python+selenium抓取豆瓣电影中的正在热映前12部电影并按评分排序
抓取豆瓣电影(http://movie.douban.com/nowplaying/chengdu/)中的正在热映前12部电影,并按照评分排序,保存至txt文件 #coding=utf-8 from ...
- Python爬虫抓取微博评论
第一步:引入库 import time import base64 import rsa import binascii import requests import re from PIL impo ...
- python 读取一个文件夹下的所jpg文件保存到txt中
最近需要使用统计一个目录下的所有文件,使用python比较方便,就整理了一下代码. import os def gci(filepath): files = os.listdir(filepath) ...
- 第二个爬虫之爬取知乎用户回答和文章并将所有内容保存到txt文件中
自从这两天开始学爬虫,就一直想做个爬虫爬知乎.于是就开始动手了. 知乎用户动态采取的是动态加载的方式,也就是先加载一部分的动态,要一直滑道底才会加载另一部分的动态.要爬取全部的动态,就得先获取全部的u ...
- Python爬虫实战八之利用Selenium抓取淘宝匿名旺旺
更新 其实本文的初衷是为了获取淘宝的非匿名旺旺,在淘宝详情页的最下方有相关评论,含有非匿名旺旺号,快一年了淘宝都没有修复这个. 可就在今天,淘宝把所有的账号设置成了匿名显示,SO,获取非匿名旺旺号已经 ...
随机推荐
- vs安装后当切换到图形设计界面的时候自动弹出“正在准备安装的提升”,然后程序处于假死状态
Vs2008 安装后当切换到图形设计界面的时候自动弹出 ”正在准备安装的提示“,然后程序处于假死状态 在网上找了很多,最终解决问题: 从vs2008安装光盘中找到 /WCU/WebDesignerC ...
- EF6 CodeFirst+Repository+Ninject+MVC4+EasyUI实践(七)
前言 上一篇文章我们完成了系统角色管理的基本功能实现,也对系统层次结构进行了了解.这一篇我们将继续对系统的用户管理模块进行代码编写.代码没有做封装,所以大部分的逻辑代码都是相通的,只是在一些前端的细节 ...
- 博客迁移到GitCafe
博客以前是放在github上,但github在国内的访问速度确实有些慢,所以就想着换个git环境,本来想迁移到oschina中,后来看到以为博友介绍的迁移到gitcafe中,索性我也就照搬迁过来了. ...
- SQL Server数据库性能优化之索引篇【转】
http://www.blogjava.net/allen-zhe/archive/2010/07/23/326966.html 性能优化之索引篇 近期项目需要, 做了一段时间的SQL Server性 ...
- CSS3背景
1.背景的五种基本属性 background-color(背景颜色) background-image(背景图片) background-repeat(背景图片展示方式) background-a ...
- MyEclipse Java Build Path详解
转载自:http://blog.163.com/magicc_love/blog/static/185853662201111161580631/ 1.设置"source folder&qu ...
- 移动混合开发之android文件管理-->flexbox,webFont。
增加操作栏,使用felxbox居中,felx相关参考网址:http://www.ruanyifeng.com/blog/2015/07/flex-grammar.html 使用webFont添加图标, ...
- ubuntu下code::blocks+opengl的使用与配置
操作系统:Ubuntu 15.04 gcc version 4.9.2 opengl安装 sudo apt-get install build-essential libgl1-mesa-dev li ...
- CMD和AMD区别的概括
CMD和AMD区别 AMD CMD 关于依赖的模块 提前执行(不过 RequireJS 从 2.0 开始,也改成可以延迟执行(根据写法不同,处理方式不同)), 延迟执行 关于依赖的位置 依赖前置 ...
- NSString,NSArray,NSNumber等类的继承问题
问题引入,我想给NSString类扩展一些新的方法.在Objective-C中可以有两种方法,一是继承,二是类别.本文先不讨论类别,我们用继承的方法试一下: @interface StringEx : ...