c#抽取pdf文档标题(3)
上一篇介绍了整体流程以及利用库读取pdf内容形成字符集合。这篇着重介绍下,过滤规则,毕竟我们是使用规则过滤,最后得到标题的。
首先看归一化处理,什么是归一化呢?就是使结果始终处于0-1之间(包括0,1)。
private static double GetMark(BlockInfo block, double maxHeight, double maxWidth, double maxYSize, double maxXSize, double maxSpace)
{
double result = ; if (maxYSize > )
result += 0.4 * ((double)block.CharAveYSize / maxYSize); if (maxXSize > )
result += 0.3 * ((double)block.CharAveXSize / maxXSize); if (maxSpace > ) result += (block.CharAveSpace / maxSpace) * 0.1; if (maxHeight > ) result += (block.CharAveHeight / maxHeight) * 0.1; if (maxWidth > )
result += (block.CharAveWidth / maxWidth) * 0.1;
if (block.RepresentativeChar.IsBold) result += 0.1;
return result;
}
这段代码,就是给块打分的一个方法。它包含了投票思想以及归一处理问题的思想。对于一个块,我们从不同的角度,也就是不同方面的特征值给分,每个特征所占的权重是不同的。YSize权重:0.4,XSize权重:0.3,它们的分值是这样计算的:
权重*(块的平均特征值 / 文档中最大特征值),拿YSize来说,假如块的CharAveYSize=40,maxYSize=60,那么结果:0.4*(40/60)= 0.267。
在这里,我想说的是,特征一定要选正确,还有特征的权重也要相对正确,否则会影响到结果的匹配率。记得之前是以Space特征为主选取的,那时候还没有采用评分系统,经测试,提取标题的准确率在30%左右,后来,看了那个同事以前的代码,发现人家的代码写的如此简单,据说准确率在60%,“大道至简”,我就又重新找到核心属性,于是经过摸索,YSize这个属性相当重要,于是准确度到了70%左右。到最后,采用了评分机制,准确度到了85%左右,再经过努力,不断完善代码,准确度提升到了92%左右。有截图为证:
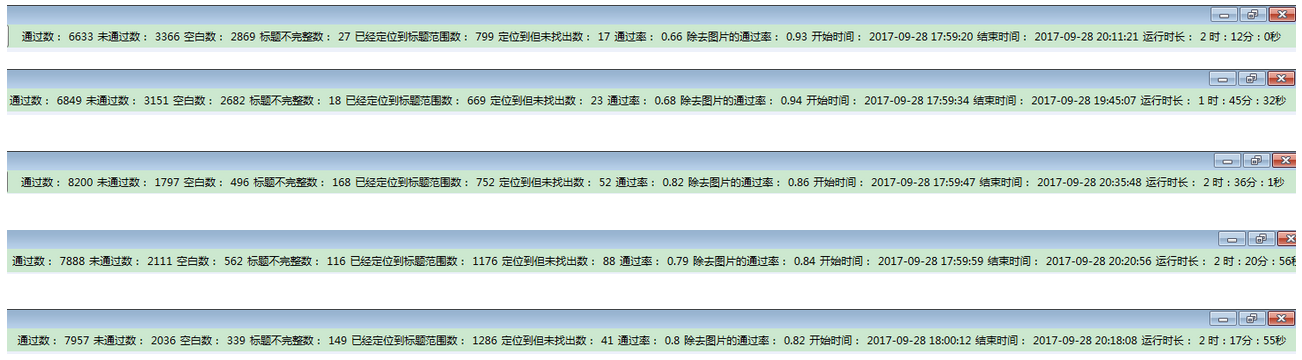
针对完全图片类型的pdf文档,我们现阶段不予处理。那么除了规则外,还有没有其它途径,来筛选标题呢?答案是肯定的,机器学习是当下一个热门领域,好了,我们下一篇就讨论这方面的话题。
c#抽取pdf文档标题(3)的更多相关文章
- c#抽取pdf文档标题——前言
由于工作的需要,研究c#抽取pdf文档标题有3个月了.这项工作是一项"伟大而艰巨"的任务.应该是我目前研究工作中最长的一次.我觉得在长时间忙碌后,应该找些时间,把自己的心路历程归纳 ...
- c#抽取pdf文档标题(1)
首先看看我的项目结构: 从上面的结果图中,我们可以看出,主要用了两个库:itextsharp.dll 和 pdfbox-1.8.9.dll,dll文件夹存放引用的库,handles文件夹存放抽取的处理 ...
- c#抽取pdf文档标题(2)
public class IETitle { public static List<WordInfo> WordsInfo = new List<WordInfo>(); pr ...
- c#抽取pdf文档标题(4)——机器学习以及决策树
我的一位同事告诉我,pdf抽取标题,用机器学习可以完美解决问题,抽取的准确率比较高.于是,我看了一些资料,就动起手来,实践了下. 我主要是根据以往历史块的特征生成一个决策树,然后利用这棵决策树,去判断 ...
- Python处理Excel和PDF文档
一.使用Python操作Excel Python来操作Excel文档以及如何利用Python语言的函数和表达式操纵Excel文档中的数据. 虽然微软公司本身提供了一些函数,我们可以使用这些函数操作Ex ...
- C#给PDF文档添加文本和图片页眉
页眉常用于显示文档的附加信息,我们可以在页眉中插入文本或者图形,例如,页码.日期.公司徽标.文档标题.文件名或作者名等等.那么我们如何以编程的方式添加页眉呢?今天,这篇文章向大家分享如何使用了免费组件 ...
- 将w3cplus网站中的文章页面提取并导出为pdf文档
最近在看一些关于CSS3方面的知识,主要是平时看到网页中有很多用CSS3实现的很炫的效果,所以就打算系统的学习一下.在网上找到很多的文章,但都没有一个好的整理性,比较凌乱.昨天看到w3cplus网站中 ...
- PDF2SWF转换只有一页的PDF文档,在FlexPaper不显示解决方法
问题:PDF2SWF转换只有一页的PDF文档,在FlexPaper不显示! FlexPaper 与 PDF2SWF 结合是解决在线阅读PDF格式文件的问题的,多页的PDF文件转换可以正常显示,只有一页 ...
- 【PDF】java使用Itext生成pdf文档--详解
[API接口] 一.Itext简介 API地址:javadoc/index.html:如 D:/MyJAR/原JAR包/PDF/itext-5.5.3/itextpdf-5.5.3-javadoc/ ...
随机推荐
- Python自动化--语言基础8--接口请求及封装
基于http协议,最常用的是GET和POST两种方法. 接口文档需要包含哪些信息: 接口名称接口功能接口地址支持格式 json/xml请求方式请求示例请求参数(是否必填.数据类型.传递参数格式)返回参 ...
- Java SocketChannel 读取ByteBuffer字节的处理模型
在JAVA中的流分为字节流或字符流,一般来说采用字符流处理起来更加方便.字节流处理起来相对麻烦,SocketChannel中将数据读取到ByteBuffer中,如何取出完整的一行数据(使用CRLF分隔 ...
- springmvc 对 jsonp 的支持
在与前端开发人员合作过程中,经常遇到跨域名访问的问题,通常我们是通过jsonp调用方式来解决.jsop百科:http://baike.baidu.com/link?url=JKlwoETqx2uuKe ...
- Jenkins系列——使用checkstyle进行代码规范检查
1.目标 通过jenkins使用checkstyle对代码进行规范检查并生成html报告. 构建采用shell. 2.环境 checkstyle5.7(如果是Linux版本选用tar.gz格式) ap ...
- UVA - 10285 Longest Run on a Snowboard (线性DP)
思路:d[x][y]表示以(x, y)作为起点能得到的最长递减序列,转移方程d[x][y] = max(d[px][py] + 1),此处(px, py)是它的相邻位置并且该位置的值小于(x, y)处 ...
- SIFT解析(二)特征点位置确定
最近微博上有人发起投票那篇论文是自己最受益匪浅的论文,不少人说是lowe的这篇介绍SIFT的论文.确实,在图像特征识别领域,SIFT的出现是具有重大意义的,SIFT特征以其稳定的存在,较高的区分度推进 ...
- Linux sed 和 awk的用法
sed用法: 原文链接:http://www.cnblogs.com/dong008259/archive/2011/12/07/2279897.html sed是一个很好的文件处理工具,本身是一个管 ...
- H3C虚拟化之IRF
SA system-view irf domain 10 irf member 1 ren 1 y int ten 1/0/50 shu qu irf-port 1/1 port group int ...
- 决策树学习笔记(Decision Tree)
什么是决策树? 决策树是一种基本的分类与回归方法.其主要有点事模型具有可得性,分类速度快.学习时,利用训练数据,根据损失函数最小化原则建立决策树模型:预测时,对新数据,利用决策树模型进行分类. 决策树 ...
- 【Unity3D】Unity3D开发《我的世界》之六、创建地形(视频 + 源码)
转载请注明出处:http://www.cnblogs.com/shamoyuu/p/unity_minecraft_06.html 一.引入LibNoise 虽然Unity3D里也有一个Mathf.P ...