k8s数据管理(八)--技术流ken
volume
我们经常会说:容器和 Pod 是短暂的。
其含义是它们的生命周期可能很短,会被频繁地销毁和创建。容器销毁时,保存在容器内部文件系统中的数据都会被清除。
为了持久化保存容器的数据,可以使用 Kubernetes Volume。
Volume 的生命周期独立于容器,Pod 中的容器可能被销毁和重建,但 Volume 会被保留。
本质上,Kubernetes Volume 是一个目录,这一点与 Docker Volume 类似。当 Volume 被 mount 到 Pod,Pod 中的所有容器都可以访问这个 Volume。Kubernetes Volume 也支持多种 backend 类型,包括 emptyDir、hostPath、GCE Persistent Disk、AWS Elastic Block Store、NFS、Ceph 等,完整列表可参考 https://kubernetes.io/docs/concepts/storage/volumes/#types-of-volumes
Volume 提供了对各种 backend 的抽象,容器在使用 Volume 读写数据的时候不需要关心数据到底是存放在本地节点的文件系统中呢还是云硬盘上。对它来说,所有类型的 Volume 都只是一个目录。
emptyDir
emptyDir 是最基础的 Volume 类型。一个 emptyDir Volume 是 Host 上的一个空目录。
emptyDir Volume 对于容器来说是持久的,对于 Pod 则不是。当 Pod 从节点删除时,Volume 的内容也会被删除。但如果只是容器被销毁而 Pod 还在,则 Volume 不受影响。
也就是说:emptyDir Volume 的生命周期与 Pod 一致。
Pod 中的所有容器都可以共享 Volume,它们可以指定各自的 mount 路径。
下面通过例子来实践 emptyDir
第一步:配置文件如下:
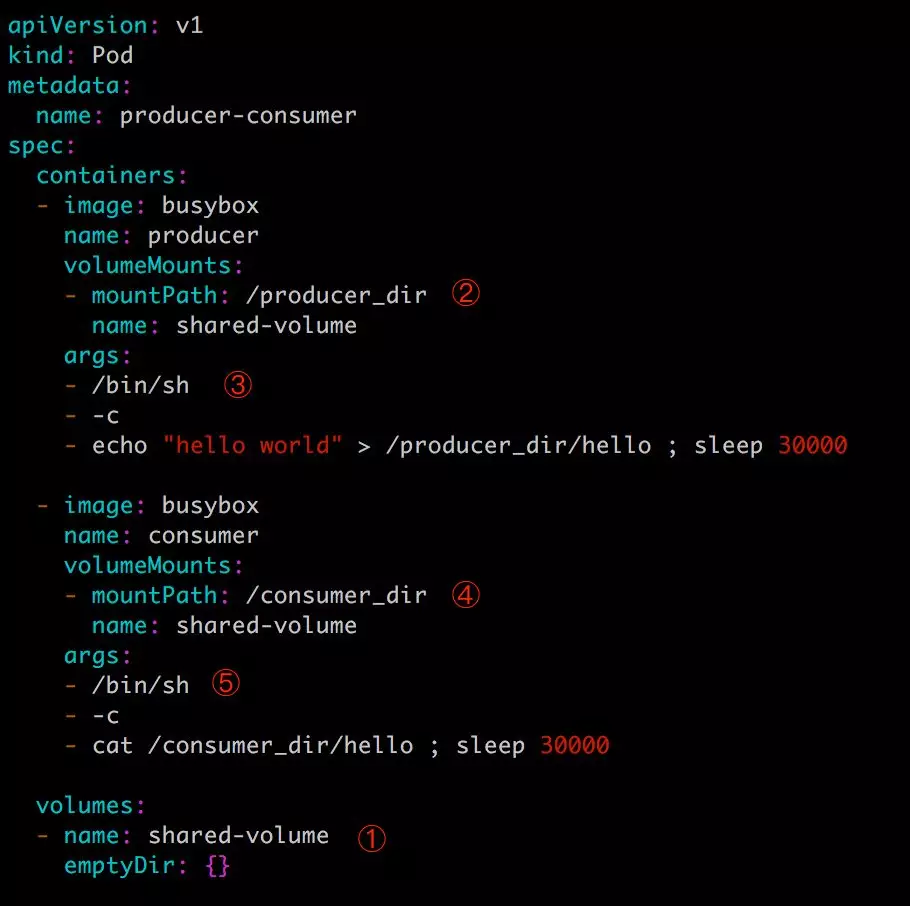
这里我们模拟了一个 producer-consumer 场景。Pod 有两个容器 producer和 consumer,它们共享一个 Volume。producer 负责往 Volume 中写数据,consumer 则是从 Volume 读取数据。
① 文件最底部 volumes 定义了一个 emptyDir 类型的 Volume shared-volume。
② producer 容器将 shared-volume mount 到 /producer_dir 目录。
③ producer 通过 echo 将数据写到文件 hello 里。
④ consumer 容器将 shared-volume mount 到 /consumer_dir 目录。
⑤ consumer 通过 cat 从文件 hello 读数据。
第二步:执行如下命令创建 Pod:
[root@ken ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
producer-consumer / Running 2m1s
[root@ken ~]# kubectl logs producer-consumer consumer
hello world
kubectl logs 显示容器 consumer 成功读到了 producer 写入的数据,验证了两个容器共享 emptyDir Volume。
因为 emptyDir 是 Docker Host 文件系统里的目录,其效果相当于执行了 docker run -v /producer_dir 和 docker run -v /consumer_dir。
第三步:通过 docker inspect 查看容器的详细配置信息,我们发现两个容器都 mount 了同一个目录:


这里 /var/lib/kubelet/pods/4dcc0366-245f-11e9-9172-000c292d5bb8/volumes/kubernetes.io~empty-dir/shared-volume 就是 emptyDir 在 Host 上的真正路径。
emptyDir 是 Host 上创建的临时目录,其优点是能够方便地为 Pod 中的容器提供共享存储,不需要额外的配置。但它不具备持久性,如果 Pod 不存在了,emptyDir 也就没有了。根据这个特性,emptyDir 特别适合 Pod 中的容器需要临时共享存储空间的场景,比如前面的生产者消费者用例。
hostpath
hostPath Volume 的作用是将 Docker Host 文件系统中已经存在的目录 mount 给 Pod 的容器。大部分应用都不会使用 hostPath Volume,因为这实际上增加了 Pod 与节点的耦合,限制了 Pod 的使用。不过那些需要访问 Kubernetes 或 Docker 内部数据(配置文件和二进制库)的应用则需要使用 hostPath。
比如 kube-apiserver 和 kube-controller-manager 就是这样的应用,通过
kubectl edit --namespace=kube-system pod kube-apiserver-k8s-master
查看 kube-apiserver Pod 的配置,下面是 Volume 的相关部分:
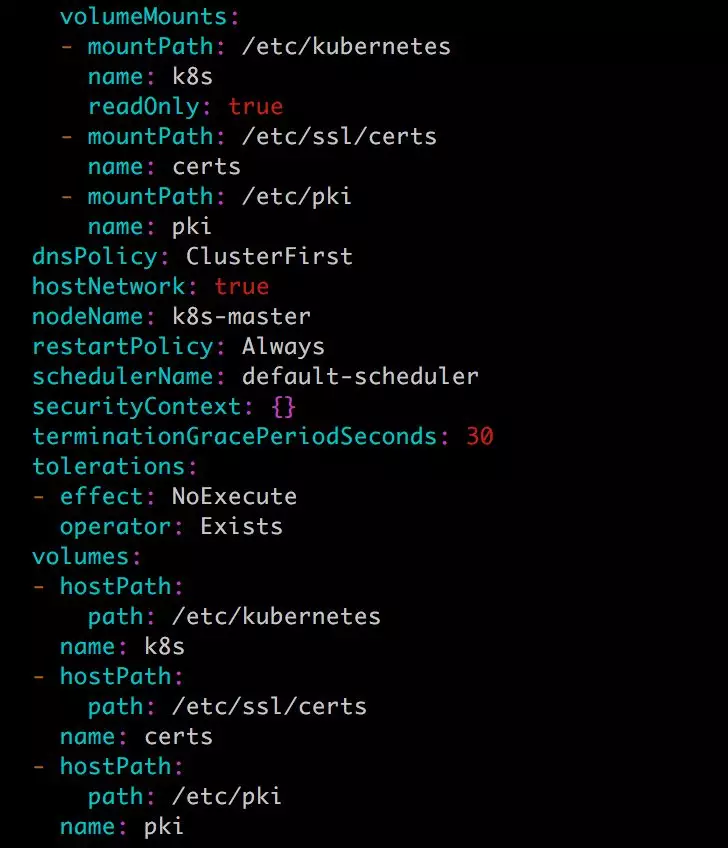
这里定义了三个 hostPath volume k8s、certs 和 pki,分别对应 Host 目录 /etc/kubernetes、/etc/ssl/certs 和 /etc/pki。
如果 Pod 被销毁了,hostPath 对应的目录也还会被保留,从这点看,hostPath 的持久性比 emptyDir 强。不过一旦 Host 崩溃,hostPath 也就没法访问了。
PV & PVC
PersistentVolume (PV) 是外部存储系统中的一块存储空间,由管理员创建和维护。与 Volume 一样,PV 具有持久性,生命周期独立于 Pod。
PersistentVolumeClaim (PVC) 是对 PV 的申请 (Claim)。PVC 通常由普通用户创建和维护。需要为 Pod 分配存储资源时,用户可以创建一个 PVC,指明存储资源的容量大小和访问模式(比如只读)等信息,Kubernetes 会查找并提供满足条件的 PV。
有了 PersistentVolumeClaim,用户只需要告诉 Kubernetes 需要什么样的存储资源,而不必关心真正的空间从哪里分配,如何访问等底层细节信息。这些 Storage Provider 的底层信息交给管理员来处理,只有管理员才应该关心创建 PersistentVolume 的细节信息。
Kubernetes 支持多种类型的 PersistentVolume,比如 AWS EBS、Ceph、NFS 等,完整列表请参考 https://kubernetes.io/docs/concepts/storage/persistent-volumes/#types-of-persistent-volumes
NFS PV
第一步:需在 k8s-master 节点上搭建了一个 NFS 服务器,目录为 /nfsdata:
要更改目录属主,否则没有写入权限: chown -R nfsnobody.nfsnobody /nfsdata
[root@ken ~]# showmount -e
Export list for ken:
/nfsdata *
第二步:创建一个 PV mypv1,配置文件 nfs-pv1.yml 如下:
[root@ken ~]# cat nfs-pv1.yml
apiVersion: v1
kind: PersistentVolume
metadata:
name: mypv1
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Recycle
storageClassName: nfs
nfs:
path: /nfsdata/pv1 #需要创建pv1目录,否则pod起不来
server: 172.20.10.2
① capacity 指定 PV 的容量为 1G。
② accessModes 指定访问模式为 ReadWriteOnce,支持的访问模式有:
ReadWriteOnce – PV 能以 read-write 模式 mount 到单个节点。
ReadOnlyMany – PV 能以 read-only 模式 mount 到多个节点。
ReadWriteMany – PV 能以 read-write 模式 mount 到多个节点。
③ persistentVolumeReclaimPolicy 指定当 PV 的回收策略为 Recycle,支持的策略有:
Retain – 需要管理员手工回收。
Recycle – 清除 PV 中的数据,效果相当于执行 rm -rf /thevolume/*。
Delete – 删除 Storage Provider 上的对应存储资源,例如 AWS EBS、GCE PD、Azure Disk、OpenStack Cinder Volume 等。
④ storageClassName 指定 PV 的 class 为 nfs。相当于为 PV 设置了一个分类,PVC 可以指定 class 申请相应 class 的 PV。
⑤ 指定 PV 在 NFS 服务器上对应的目录。
第三步:创建 mypv1:
[root@ken ~]# kubectl apply -f nfs-pv1.yml
persistentvolume/mypv1 created
第四步:查看pv
[root@ken ~]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
mypv1 1Gi RWO Recycle Available nfs 48s
STATUS 为 Available,表示 mypv1 就绪,可以被 PVC 申请。
第五步:接下来创建 PVC mypvc1,配置文件 nfs-pvc1.yml 如下:
注意:
1. storageClassName需要与上面定义的pv保持一致!
2. 各个节点都需要下载nfs-utils
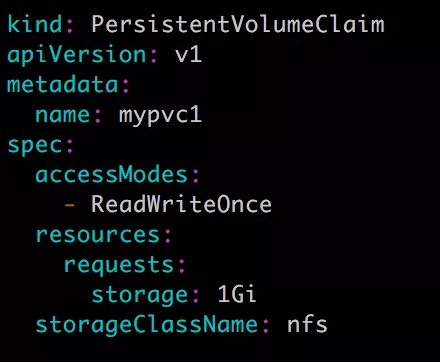
PVC 就很简单了,只需要指定 PV 的容量,访问模式和 class。
[root@ken ~]# kubectl apply -f nfs-pvc1.yml
persistentvolumeclaim/mypvc1 created
第六步:查看pvc
[root@ken ~]# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
mypvc1 Bound mypv1 1Gi RWO nfs 112s
[root@ken ~]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
mypv1 1Gi RWO Recycle Bound default/mypvc1 nfs 6m5s
从 kubectl get pvc 和 kubectl get pv 的输出可以看到 mypvc1 已经 Bound 到 mypv1,申请成功。
第七步:接下来就可以在 Pod 中使用存储了,Pod 配置文件 pod1.yml 如下:

与使用普通 Volume 的格式类似,在 volumes 中通过 persistentVolumeClaim 指定使用 mypvc1 申请的 Volume。
第八步:创建 mypod1:
[root@ken ~]# kubectl apply -f pod1.yml
pod/mypod1 created
[root@ken ~]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
mypod1 1/1 Running 0 51s 10.244.1.59 host1 <none> <none>
第九步:验证 PV 是否可用:
[root@ken ~]# kubectl exec mypod1 touch /mydata/hello [root@ken ~]# ls /nfsdata/pv1/
hello
可见,在 Pod 中创建的文件 /mydata/hello 确实已经保存到了 NFS 服务器目录 /nfsdata/pv1 中。
回收PV
当 PV 不再需要时,可通过删除 PVC 回收。
当 PVC mypvc1 被删除后,Kubernetes 启动了一个新 Pod recycler-for-mypv1,这个 Pod 的作用就是清除 PV mypv1 的数据。此时 mypv1 的状态为 Released,表示已经解除了与 mypvc1 的 Bound,正在清除数据,不过此时还不可用。
当数据清除完毕,mypv1 的状态重新变为 Available,此时则可以被新的 PVC 申请。
因为 PV 的回收策略设置为 Recycle,所以数据会被清除,但这可能不是我们想要的结果。如果我们希望保留数据,可以将策略设置为 Retain。
第一步:将策略设置为 Retain。
[root@ken ~]# cat nfs-pv1.yml
apiVersion: v1
kind: PersistentVolume
metadata:
name: mypv1
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
storageClassName: nfs
nfs:
path: /nfsdata/pv1
server: 172.20.10.2
第二步:通过 kubectl apply 更新 PV:
root@ken ~]# kubectl apply -f nfs-pv1.yml
persistentvolume/mypv1 configured
[root@ken ~]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
mypv1 1Gi RWO Retain Available nfs 65m
回收策略已经变为 Retain
另外使用retain虽然删除pod后的数据得到了保留,但其 PV 状态会一直处于 Released,不能被其他 PVC 申请。为了重新使用存储资源,可以删除并重新创建 PV。删除操作只是删除了 PV 对象,存储空间中的数据并不会被删除。
k8s数据管理(八)--技术流ken的更多相关文章
- k8s集群监控(十一)--技术流ken
Weave Scope 在我之前的docker监控中<Docker容器监控(十)--技术流ken>就已经提到了weave scope. Weave Scope 是 Docker 和 K ...
- MySQL系列详解八:MySQL多线程复制演示-技术流ken
前言 Mysql 采用多线程进行复制是从 Mysql 5.6 开始支持的内容,但是 5.6 版本下有缺陷,虽然支持多线程,但是每个数据库只能一个线程,也就是说如果我们只有一个数据库,则主从复制时也只有 ...
- Jenkins+Git+Gitlab+Ansible实现持续集成自动化部署动态网站(二)--技术流ken
项目前言 在上一篇博客<Jenkins+Git+Gitlab+Ansible实现持续化集成一键部署静态网站(一)--技术流ken>中已经详细讲解了如何使用这四个工具来持续集成自动化部署一个 ...
- 网站集群架构(LVS负载均衡、Nginx代理缓存、Nginx动静分离、Rsync+Inotify全网备份、Zabbix自动注册全网监控)--技术流ken
前言 最近做了一个不大不小的项目,现就删繁就简单独拿出来web集群这一块写一篇博客.数据库集群请参考<MySQL集群架构篇:MHA+MySQL-PROXY+LVS实现MySQL集群架构高可用/高 ...
- zabbix实现百台服务器的自动化监控--技术流ken
前言 最近有小伙伴通过Q联系到我说:公司现在有百多台服务器,想要部署zabbix进行监控,怎么实现自动化全网监控? 本篇博客将讲解一个我工作时做的一个实际项目,现在写出来供大家以后参考使用. 实现自动 ...
- Docker数据卷Volume实现文件共享、数据迁移备份(三)--技术流ken
前言 前面已经写了两篇关于docker的博文了,在工作中有关docker的基本操作已经基本讲解完了.相信现在大家已经能够熟练配置docker以及使用docker来创建镜像以及容器了.本篇博客将会讲解如 ...
- Docker端口映射及创建镜像演示(二)--技术流ken
前言 在上一篇博客<Docker介绍及常用操作演示--技术流ken>中,已经详细介绍了docker相关内容以及有关镜像和容器的使用命令演示. 现在我们已经可以自己下载镜像,以及创建容器了. ...
- Jenkins+Git+Gitlab+Ansible实现持续集成自动化部署静态网站(一)--技术流ken
前言 在之前已经写了关于Git,Gitlab以及Ansible的两篇博客<Git+Gitlab+Ansible剧本实现一键部署Nginx--技术流ken>,<Git+Gitlab+A ...
- Jenkins凭证及任务演示-pipeline(二)--技术流ken
Jenkins前言 在上一篇博客<Jenkins持续集成介绍及插件安装版本更新演示(一)--技术流ken>中已经详细介绍了jenkins的插件安装以版本更新等,本篇博客将再深入探究jenk ...
- Git+Gitlab+Ansible的roles实现一键部署Nginx静态网站(一)--技术流ken
前言 截止目前已经写了<Ansible基础认识及安装使用详解(一)--技术流ken>,<Ansible常用模块介绍及使用(二)--技术流ken><Ansible剧本介绍及 ...
随机推荐
- BZOJ_1179_[Apio2009]Atm_tarjan+spfa
BZOJ_1179_[Apio2009]Atm_tarjan+spfa 题意:http://www.lydsy.com/JudgeOnline/problem.php?id=1179 分析: 显然有环 ...
- BZOJ3252: 攻略 可并堆
网上有很多人说用dfs序+线段树做...其实stl的堆可以...可并堆可以...很多奇奇怪怪的东西都能做... 可并堆比较好想...也比较好写... 分析: 首先,这是一个网络流做不了的题...数据太 ...
- Appium 【已解决】提示报错:Attempt to re-install io.appium.android.ime without first uninstalling.
详细报错:Failed to install D:\AutoTest\appium\Appium\node_modules\appium\build\unicode_ime_apk\UnicodeIM ...
- ASP.Net Core Razor+AdminLTE 小试牛刀
AdminLTE 一个基于 bootstrap 的轻量级后台模板,这个前端界面个人感觉很清爽,对于一个大后端的我来说,可以减少较多的时间去承担前端的工作但又必须去独立去完成一个后台系统开发的任务,并且 ...
- Java注解(一):介绍,作用,思想及优点
“注解优先于命令模式”-出自<Effective Java> Java 注解,从名字上看是注释,解释.但功能却不仅仅是注释那么简单.注解(Annotation) 为我们在代码中添加信息提供 ...
- mybatis 增加热加载xml
由于在本地开发环境上每次修改mybatis xml文件都需要手动重启服务,调试的很麻烦,所以需要热加载xml文件来避免浪费时间,于是网上搜一下资料,看了下有一大堆,但试了下真正能跑起来没有(大都代码没 ...
- 使用elementUI的时候,使用Upload 上传的时候,使用 list-type 属性来设置文件列表的样式,before-upload方法失效
最近在做项目的时候,使用elementUI的时候,使用Upload 上传的时候,before-upload方法失效. 情况下:使用 list-type 属性来设置文件列表的样式. 最终的优化之后:(演 ...
- 初探机器学习之使用百度EasyDL定制化模型
一.Why 定制化模型 一般来说,各大云服务厂商只会提供一些最常见通用的AI服务,针对具体场景的AI应用则需要在云服务厂商提供的服务之上进行定制.例如,通常的图像识别只能做到分析照片的主题内容,而我的 ...
- ES 11 - 配置Elasticsearch的映射 (mapping)
目录 1 映射的相关概念 1.1 什么是映射 1.2 映射的组成 1.3 元字段 1.4 字段的类型 2 如何配置mapping 2.1 创建mapping 2.2 更新mapping 2.3 查看m ...
- MySSL HTTPS 评级 B 升 A+
背景 MySSL 提供了免费的网站 HTTPS 安全评级服务,然后我用我的网站 https://hellogithub.com,测试了一下.发现安全评级为 B,最高为 A+.下面是记录我的网站从 B ...