python爬虫 --- 简书评论
某些网站的一些数据是通过js加载的 ,所以爬取下来的数据拿不到,
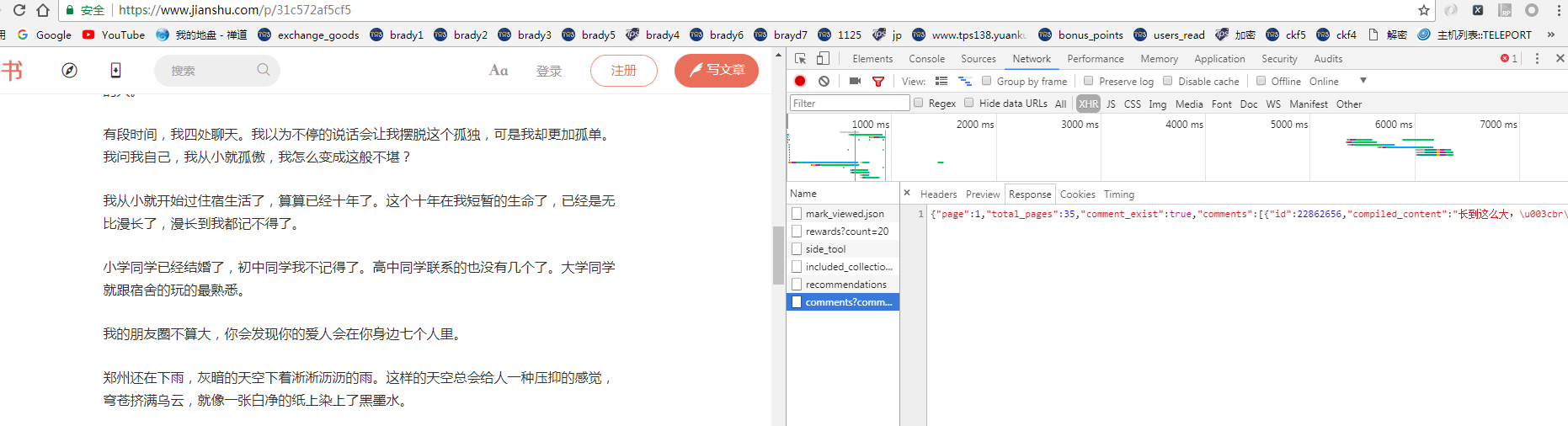
找到评论的地址 .进行请求获取评论数据
#coding=utf-8
import json import requests def requests_view(response):
import webbrowser
requests_url = response.url
base_url = '<head><base href="%s">' %(requests_url)
base_url = base_url.encode('utf-8')
content = response.content.replace(b"<head>",base_url)
tem_html = open('tmp.html','wb')
tem_html.write(content)
tem_html.close()
webbrowser.open_new_tab("tmp.html") headers = {
"User-Agent": 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'}
response = requests.get("https://www.jianshu.com/notes/26504955/comments?comment_id=&author_only=false&since_id=0&max_id=1586510606000&order_by=likes_count&page=1",headers=headers)
comments = json.loads(response.content) if comments['comment_exist'] == True:
for item in comments['comments']:
print(item['user']['nickname'],item['compiled_content'])
python爬虫 --- 简书评论的更多相关文章
- jsoup爬虫简书首页数据做个小Demo
代码地址如下:http://www.demodashi.com/demo/11643.html 昨天LZ去面试,遇到一个大牛,被血虐一番,发现自己基础还是很薄弱,对java一些原理掌握的还是不够稳固, ...
- 【python3】爬取简书评论生成词云
一.起因: 昨天在简书上看到这么一篇文章<中国的父母,大都有毛病>,看完之后个人是比较认同作者的观点. 不过,翻了下评论,发现评论区争议颇大,基本两极化.好奇,想看看整体的评论是个什么样, ...
- python 爬取简书评论
import json import requests from lxml import etree from time import sleep url = "https://www.ji ...
- Python 2.7_发送简书关注的专题作者最新一篇文章及连接到邮件_20161218
最近看简书文章关注了几个专题作者,写的文章都不错,对爬虫和数据分析都写的挺好,因此想到能不能获取最新的文章推送到Ipad网易邮箱大师.邮件发送代码封装成一个函数,从廖雪峰大神那里学的 http:// ...
- Python 2.7_多进程获取简书专题数据(一)
学python几个月了正好练练手,发现问题不断提高,先从专题入手,爬取些数据,一开始对简书网站结构不熟悉,抓取推荐,热门,城市3个导航栏,交流发现推荐和热门是排序不同,url会重复,以及每个专题详情页 ...
- SuperSpider(简书爬虫JAVA版)
* 建站数据SuperSpider(简书)* 本项目目的:* 为练习web开发提供相关的数据:* 主要数据包括:* 简书热门专题模块信息.对应模块下的热门文章.* 文章的详细信息.作者信息.* 评论区 ...
- [Python爬虫] Selenium+Phantomjs动态获取CSDN下载资源信息和评论
前面几篇文章介绍了Selenium.PhantomJS的基础知识及安装过程,这篇文章是一篇应用.通过Selenium调用Phantomjs获取CSDN下载资源的信息,最重要的是动态获取资源的评论,它是 ...
- Python天猫淘宝评论爬虫
说明 由于Github 打包的exe某些文件上传被.gitignore了,所以不提供windows二进制包 https://github.com/hunterhug/taobaocomment 一个抓 ...
- [Python爬虫] Selenium爬取新浪微博客户端用户信息、热点话题及评论 (上)
转载自:http://blog.csdn.net/eastmount/article/details/51231852 一. 文章介绍 源码下载地址:http://download.csdn.net/ ...
随机推荐
- 对Python语法简洁的贴切描述
很多人认为,Python与其他语言相比,具有语法简洁的特点.但这种简洁到底体现在哪些地方,很少有人能说清楚.今天看到一个对这一问题的描述,个人觉得很不错,原文如下: “Python语法主要用来精确表达 ...
- python七类之整型布尔值
整型与布尔值 一.关键字:整型 --->int 布尔值----->bool : True 真 False 假 1.整形和布尔值都是不可变得不可迭代的数据类型 2.整型: 主 ...
- go字符串操作
在Go语言标准库中的strings和strconv两个包可以对字符串做快速处理 string包 func Contains(s, substr string) bool 字符串s中是否包含substr ...
- LeetCode:33. Search in Rotated Sorted Array(Medium)
1. 原题链接 https://leetcode.com/problems/search-in-rotated-sorted-array/description/ 2. 题目要求 给定一个按升序排列的 ...
- L010小结后自考题
. 查询2号分区的inode和block的数量和尺寸 . 在lcr文件夹下创建一个a文件夹,然后进入文件夹中,创建3个3层目录,5个1层目录,5个文件 . 滤出a文件夹下的所有一级目录(4种方法) . ...
- L010 linux命令及基础手把手实战总结
一转眼都快两周没更新了,最近实在太忙了,这两周的时间断断续续的把L010学完了,短短的15节课,确是把前10节的课程全部的运用一遍,从笔记到整理,再到重新理解,最后发布到微博,也确实提升了一些综合性能 ...
- 浅谈如何提高自动化测试的稳定性和可维护性 (pytest&allure)
装饰器与出错重试机制 谈到稳定性,不得不说的就是“出错重试”机制了,在自动化测试中,由于环境一般都是测试环境,经常会有各种各种的抽风情况影响测试结果,这样就为测试的稳定性带来了挑战,毕竟谁也不想自己的 ...
- Jmeter 接口自动化执行报错 无法找到类或者类的方法
写好的自动化测试脚本在PC以及mac book 都执行正确,但是放到linux集成环境时就一直报错,报错类似如下 [jmeter] // Debug: eval: nameSpace = NameSp ...
- Siki_Unity_1-2_Unity5.2入门课程_进入Unity开发的奇幻世界_Roll A Ball
1-2 Unity5.2入门课程 进入Unity开发的奇幻世界 任务1:Roll A Ball项目简介 Unity官网的tutorial入门项目 方向键控制小球在平台上滚动,碰撞方块得分,消掉所有方块 ...
- Scala学习笔记之Actor多线程与线程通信的简单例子
题目:通过子线程读取每个文件,并统计单词数,将单词数返回给主线程相加得出总单词数 package review import scala.actors.{Actor, Future} import s ...