第3章 Hadoop 2.x分布式集群搭建
3.1 配置各节点SSH无密钥登录
【操作目的】
Hadoop的进程间通信使用SSH(Secure Shell)方式。SSH是一种通信加密协议,使用非对称加密方式,可以避免网络窃听。为了使Hadoop各节点之间能够无密码相互访问,需要配置各节点的SSH无秘钥登录。
【登录原理】
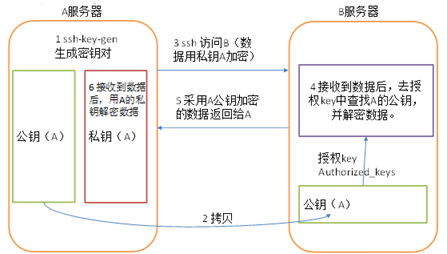
SSH无密钥登录的原理如下图:
【操作步骤】
方法一:
1.将各节点的秘钥加入到同一个授权文件中
无秘钥登录的原理是,登录节点的秘钥信息是否存在于被登录节点的授权文件中,如果存在,则允许登录。为了所有节点之间 能够相互登录,首先我们需要将各个节点的秘钥加入到同一个授权文件中,步骤如下:
(1)在centos01节点中,生成秘钥文件,并将秘钥信息加入到授权文件中。所需命令如下:
cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
ssh-keygen -t rsa # 生成秘钥文件,会有提示,都按回车就可以
cat ./id_rsa.pub >> ./authorized_keys # 将秘钥内容加入到授权文件中
(2)在centos02节点中,生成秘钥文件,并将秘钥文件远程拷贝到centos01节点的相同目录,且重命名为id_rsa.pub.centos02。相关命令如下:
cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
ssh-keygen -t rsa # 生成秘钥文件,会有提示,都按回车就可以
scp ~/.ssh/id_rsa.pub hadoop@centos01:~/.ssh/id_rsa.pub.centos02 #远程拷贝
(3)在centos03节点中,执行与centos02相同的操作(生成秘钥文件,并将秘钥文件远程拷贝到centos01节点的相同目录,且重命名为id_rsa.pub.centos03)。相关命令如下:
cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
ssh-keygen -t rsa # 生成秘钥文件,会有提示,都按回车就可以
scp ~/.ssh/id_rsa.pub hadoop@centos01:~/.ssh/id_rsa.pub.centos03 #远程拷贝
(4)回到centos01节点,将centos02和centos03节点的秘钥文件信息都加入到授权文件中。相关命令如下:
cat ./id_rsa.pub.centos02 >> ./authorized_keys #将centos02的秘钥加入到授权文件中
cat ./id_rsa.pub.centos03 >> ./authorized_keys #将centos03的秘钥加入到授权文件中
2.拷贝授权文件到各个节点
将centos01节点中的授权文件远程拷贝到其它节点,命令如下:
scp ~/.ssh/authorized_keys hadoop@centos02:~/.ssh/
scp ~/.ssh/authorized_keys hadoop@centos03:~/.ssh/
3.测试无秘钥登录
接下来可以测试从centos01无秘钥登录到centos02,命令如下:
ssh centos02
如果登录失败,可能的原因是授权文件authorized_keys权限过高,分别在每个节点上执行如下命令,更改文件权限:
chmod 700 ~/.ssh #只有拥有者有读写权限。
chmod 600 ~/.ssh/authorized_keys #只有拥有者有读、写、执行权限。
到此,各节点的SSH无秘钥登录就配置完成了。
方法二:
ssh-copy-id命令可以把本地主机的公钥复制并追加到远程主机的authorized_keys文件中,ssh-copy-id命令也会给远程主机的用户主目录(home)和~/.ssh, 和~/.ssh/authorized_keys设置合适的权限。
(1)分别在三个节点中执行以下命令,生成秘钥文件:
cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
ssh-keygen -t rsa # 生成秘钥文件,会有提示,都按回车就可以
(2)分别在三个节点中执行以下命令,将公钥信息拷贝并追加到对方节点的授权文件authorized_keys中:
ssh-copy-id centos01
ssh-copy-id centos02
ssh-copy-id centos03
最后测试SSH无秘钥登录。
3.2 搭建Hadoop集群
【操作目的】
本例的搭建思路是,在节点centos01中安装Hadoop并修改配置文件,然后将配置好的Hadoop安装文件远程拷贝到集群中其它节点。各节点的角色分配如下表:
| 节点 | 角色 |
|---|---|
| centos01 | NameNode SecondaryNameNode DataNode ResourceManager NodeManager |
| centos02 | DataNode NodeManager |
| centos03 | DataNode NodeManager |
【操作步骤】
Hadoop集群搭建的操作步骤如下:
1.上传Hadoop并解压
在centos01节点中,将Hadoop安装文件hadoop-2.7.1.tar.gz上传到/opt/softwares/目录,进入该目录,解压hadoop到/opt/modules/,命令如下:
[hadoop@centos01 ~]$ cd /opt/softwares/
[hadoop@centos01 softwares]$ tar -zxf hadoop-2.7.1.tar.gz -C /opt/modules/
2.配置Hadoop环境变量
Hadoop所有的配置文件都存在于安装目录下的/etc/hadoop中,修改如下配置文件:
hadoop-env.sh
mapred-env.sh
yarn-env.sh
三个文件分别加入JAVA_HOME环境变量,如下:
export JAVA_HOME=/opt/modules/jdk1.8.0_101
3.配置HDFS
(1)修改配置文件core-site.xml,加入以下内容:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://centos01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/modules/hadoop-2.7.1/tmp</value>
</property>
</configuration>
参数解析:
fs.defaultFS:HDFS的默认访问路径。
hadoop.tmp.dir:Hadoop临时文件的存放目录,可自定义。
(2)修改配置文件hdfs-site.xml,加入以下内容:
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property><!--不检查用户权限-->
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/modules/hadoop-2.7.1/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/modules/hadoop-2.7.1/tmp/dfs/data</value>
</property>
</configuration>
参数解析:
dfs.replication:文件在HDFS系统中的副本数。
dfs.namenode.name.dir:HDFS名称节点数据在本地文件系统的存放位置。
dfs.datanode.data.dir:HDFS数据节点数据在本地文件系统的存放位置。
(3)修改slaves文件,配置DataNode节点。slaves文件原本无任何内容,需要将所有DataNode节点的主机名都添加进去,每个主机名占一整行。本例中,DataNode为三个节点,因此slaves文件的内容如下:
centos01
centos02
centos03
4.配置YARN
(1)重命名mapred-site.xml.template文件为mapred-site.xml,修改mapred-site.xml文件,添加以下内容,指定使用yarn来运行mapreduce任务。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
(2)修改yarn-site.xml文件,添加以下内容:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
参数解析:
yarn.nodemanager.aux-services :NodeManager上运行的附属服务。需配置成mapreduce_shuffle才可运行MapReduce程序。
5.拷贝Hadoop安装文件到其它主机
在centos01节点上,将配置好的整个Hadoop安装目录,拷贝到其它节点(centos02与centos03)。命令如下:
[hadoop@centos01 modules]$ scp -r hadoop-2.7.1/ hadoop@centos02:/opt/modules/
[hadoop@centos01 modules]$ scp -r hadoop-2.7.1/ hadoop@centos03:/opt/modules/
6.启动Hadoop
启动Hadoop之前,需要先格式化NameNode。格式化NameNode可以初始化HDFS文件系统的一些目录和文件,在centos01节点上执行以下命令,进行格式化操作:
hadoop namenode -format
格式化成功后,在centos01节点上执行以下命令,启动Hadoop集群:
start-all.sh
也可以执行start-dfs.sh和start-yarn.sh分别启动HDFS和YARN集群。
7.查看各节点启动进程
集群启动成功后,分别在各个节点上执行jps命令,查看启动的Java进程。可以看到,各节点的Java进程如下:
centos01节点的进程:
[hadoop@centos01 hadoop-2.7.1]$ jps
13524 SecondaryNameNode
13813 NodeManager
13351 DataNode
13208 NameNode
13688 ResourceManager
14091 Jps
centos02节点的进程:
[hadoop@centos02 ~]$ jps
7585 NodeManager
7477 DataNode
7789 Jps
centos03节点的进程:
[hadoop@centos03 ~]$ jps
8308 Jps
8104 NodeManager
7996 DataNode
8.测试HDFS
在centos01节点的HDFS根目录创建文件夹input,并将Hadoop安装目录下的文件README.txt上传到新建的input文件夹中。命令如下:
hdfs dfs -mkdir /input
hdfs dfs -put /opt/modules/hadoop-2.7.1/README.txt /input
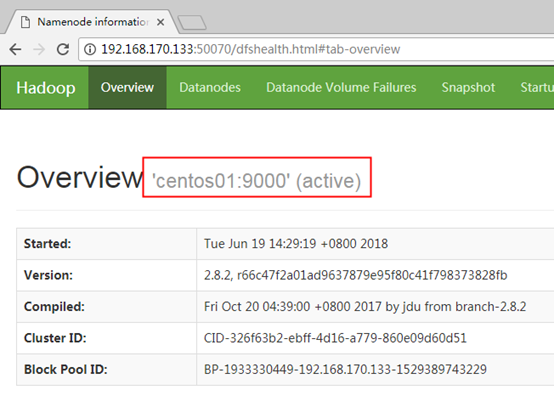
访问网址:http://192.168.170.133:50070 可以查看HDFS的NameNode信息,界面如下:
9.测试MapReduce
在centos01节点中执行以下命令,运行Hadoop自带的MapReduce单词计数程序,统计/input文件夹中的所有文件的单词数量:
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar /input /output
统计完成后,执行以下命令,查看MapReduce执行结果:
hdfs dfs -cat /output/*
如果以上测试没有问题,则Hadoop集群搭建成功。
原创文章,转载请注明出处!!
第3章 Hadoop 2.x分布式集群搭建的更多相关文章
- Hadoop单机/伪分布式集群搭建(新手向)
此文已由作者朱笑笑授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. 本文主要参照官网的安装步骤实现了Hadoop伪分布式集群的搭建,希望能够为初识Hadoop的小伙伴带来借鉴意 ...
- 大数据之Hadoop完全分布式集群搭建
1.准备阶段 1.1.新建三台虚拟机 Hadoop完全分市式集群是典型的主从架构(master-slave),一般需要使用多台服务器来组建.我们准备3台服务器(关闭防火墙.静态IP.主机名称).如果没 ...
- Hadoop上路-01_Hadoop2.3.0的分布式集群搭建
一.配置虚拟机软件 下载地址:https://www.virtualbox.org/wiki/downloads 1.虚拟机软件设定 1)进入全集设定 2)常规设定 2.Linux安装配置 1)名称类 ...
- hadoop伪分布式集群搭建与安装(ubuntu系统)
1:Vmware虚拟软件里面安装好Ubuntu操作系统之后使用ifconfig命令查看一下ip; 2:使用Xsheel软件远程链接自己的虚拟机,方便操作.输入自己ubuntu操作系统的账号密码之后就链 ...
- Hadoop分布式集群搭建
layout: "post" title: "Hadoop分布式集群搭建" date: "2017-08-17 10:23" catalog ...
- 阿里云ECS服务器部署HADOOP集群(二):HBase完全分布式集群搭建(使用外置ZooKeeper)
本篇将在阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建的基础上搭建,多添加了一个 datanode 节点 . 1 节点环境介绍: 1.1 环境介绍: 服务器:三台阿里 ...
- 阿里云ECS服务器部署HADOOP集群(三):ZooKeeper 完全分布式集群搭建
本篇将在阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建的基础上搭建,多添加了一个 datanode 节点 . 1 节点环境介绍: 1.1 环境介绍: 服务器:三台阿里 ...
- Hadoop完全分布式集群搭建
Hadoop的运行模式 Hadoop一般有三种运行模式,分别是: 单机模式(Standalone Mode),默认情况下,Hadoop即处于该模式,使用本地文件系统,而不是分布式文件系统.,用于开发和 ...
- hbase分布式集群搭建
hbase和hadoop一样也分为单机版.伪分布式版和完全分布式集群版本,这篇文件介绍如何搭建完全分布式集群环境搭建. hbase依赖于hadoop环境,搭建habase之前首先需要搭建好hadoop ...
随机推荐
- linux(centos、ubuntu)网卡配置文件不生效
今天遇到个问题,服务器上ifcfg配置了eth0文件,但是通过ifcfg命令检查发现网卡IP配置并未生效. 然后通过如下配置修正: ubuntu: # vim /etc/default/grub在”G ...
- 【jQuery】jQuery中的事件捕获与事件冒泡
在介绍之前,先说一下JavaScript中的事件流概念.事件流描述的是从页面中接受事件的顺序. 一.事件冒泡( Event Bubbling) IE 的事件流叫做事件冒泡,即 ...
- 打通 Spark 系统运行内幕机制循环流程
本课主题 打通 Spark 系统运行内幕机制循环流程 引言 通过 DAGScheduelr 面向整个 Job,然后划分成不同的 Stage,Stage 是从后往前划分的,执行的时候是從前往后执行的,每 ...
- arcgis server 9.3 查看地图服务时出现"No Content"错误
问题描述: 使用ArcGIS Server Manager的Add new service功能发布一个服务.然后启动服务 用浏览器访问该服务的地址http://localhost/ArcGIS/ser ...
- 蓝牙BLE数据包格式汇总
以蓝牙4.0为例说明: BLE包格式有:广播包.扫描包.初始化连接包.链路层控制包(LL层数据包).逻辑链路控制和自适应协议数据包(即L2CAP数据包)等: 其中广播包又分为:定向广播包和非定向广播包 ...
- git branch 相关操作总结 新建分支 删除分支 切换分支 查看分支
查看分支 (1) 查看本地分支 git branch 列出本地已经存在的分支,并且在当前分支的前面加*号标记,例如:localhost:website admin$ git branch* bran ...
- 20、Springboot 与数据访问(JDBC/自动配置)
简介: 对于数据访问层,无论是SQL还是NOSQL,Spring Boot默认采用整合 Spring Data的方式进行统一处理,添加大量自动配置,屏蔽了很多设置.引入 各种xxxTemplate,x ...
- 3springboot:springboot配置文件(配置文件占位符、Profile、配置文件的加载位置)
1.配置文件占位符 RaandomValuePropertySourcr:配置文件可以使用随机数 ${random.value} ${random.int} ${random.long ...
- 几句代码简单实现IoC容器
前言 最近在调试EasyNetQ代码的时候发现里面有一段代码,就是IoC容器的简单实现,跟着他的代码敲了一遍,发现了奇妙之处.当然也是因为我才疏学浅导致孤陋寡闻了.他的思路就是通过动态调用构造函数生成 ...
- Enum介绍
public enum Color { RED, YELLOW, BLUE; } 说明: 使用的是enum关键字而不是class 多个枚举变量之间用 逗号 隔开 枚举变量名大写,多个单词之间用 _ 隔 ...