Spark进阶之路-Spark HA配置
Spark进阶之路-Spark HA配置
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
集群部署完了,但是有一个很大的问题,那就是Master节点存在单点故障,要解决此问题,就要借助zookeeper,并且启动至少两个Master节点来实现高可靠,配置方式比较简单。本篇博客的搭建环境是基于Standalone模式进行的(https://www.cnblogs.com/yinzhengjie/p/9458161.html)
1>.编辑spark-env.sh文件,去掉之前的master主机,并指定zookeeper集群的主机
[yinzhengjie@s101 ~]$ grep -v ^# /soft/spark/conf/spark-env.sh | grep -v ^$
export JAVA_HOME=/soft/jdk
SPARK_MASTER_PORT=
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=4000 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs://s105:8020/yinzhengjie/logs"
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=s102:2181,s103:2181,s103:2181 -Dspark.deploy.zookeeper.dir=/spark" #指定zookeeper的集群地址以及spark在spark存放的路径。
[yinzhengjie@s101 ~]$
2>.分发配置
[yinzhengjie@s101 ~]$ more `which xrsync.sh`
#!/bin/bash
#@author :yinzhengjie
#blog:http://www.cnblogs.com/yinzhengjie
#EMAIL:y1053419035@qq.com #判断用户是否传参
if [ $# -lt ];then
echo "请输入参数";
exit
fi #获取文件路径
file=$@ #获取子路径
filename=`basename $file` #获取父路径
dirpath=`dirname $file` #获取完整路径
cd $dirpath
fullpath=`pwd -P` #同步文件到DataNode
for (( i=;i<=;i++ ))
do
#使终端变绿色
tput setaf
echo =========== s$i %file ===========
#使终端变回原来的颜色,即白灰色
tput setaf
#远程执行命令
rsync -lr $filename `whoami`@s$i:$fullpath
#判断命令是否执行成功
if [ $? == ];then
echo "命令执行成功"
fi
done
[yinzhengjie@s101 ~]$
同步文件的脚本,需要配置无秘钥登录才能使用哟([yinzhengjie@s101 ~]$ more `which xrsync.sh`)
[yinzhengjie@s101 ~]$ xrsync.sh /soft/spark
=========== s102 %file ===========
命令执行成功
=========== s103 %file ===========
命令执行成功
=========== s104 %file ===========
命令执行成功
=========== s105 %file ===========
命令执行成功
[yinzhengjie@s101 ~]$ xrsync.sh /soft/spark-2.1.-bin-hadoop2./
=========== s102 %file ===========
命令执行成功
=========== s103 %file ===========
命令执行成功
=========== s104 %file ===========
命令执行成功
=========== s105 %file ===========
命令执行成功
[yinzhengjie@s101 ~]$
3>.s101启动master集群
[yinzhengjie@s101 ~]$ /soft/spark/sbin/start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /soft/spark/logs/spark-yinzhengjie-org.apache.spark.deploy.master.Master--s101.out
s103: starting org.apache.spark.deploy.worker.Worker, logging to /soft/spark/logs/spark-yinzhengjie-org.apache.spark.deploy.worker.Worker--s103.out
s104: starting org.apache.spark.deploy.worker.Worker, logging to /soft/spark/logs/spark-yinzhengjie-org.apache.spark.deploy.worker.Worker--s104.out
s102: starting org.apache.spark.deploy.worker.Worker, logging to /soft/spark/logs/spark-yinzhengjie-org.apache.spark.deploy.worker.Worker--s102.out
[yinzhengjie@s101 ~]$
[yinzhengjie@s101 ~]$ xcall.sh jps
============= s101 jps ============
DFSZKFailoverController
Jps
Master
NameNode
HistoryServer
命令执行成功
============= s102 jps ============
QuorumPeerMain
DataNode
Jps
JournalNode
Worker
命令执行成功
============= s103 jps ============
JournalNode
Worker
QuorumPeerMain
Jps
DataNode
命令执行成功
============= s104 jps ============
Worker
QuorumPeerMain
Jps
DataNode
JournalNode
命令执行成功
============= s105 jps ============
DFSZKFailoverController
NameNode
Jps
命令执行成功
[yinzhengjie@s101 ~]$
4>.s105手动启动另外一个master
[yinzhengjie@s105 ~]$ /soft/spark/sbin/start-master.sh
starting org.apache.spark.deploy.master.Master, logging to /soft/spark/logs/spark-yinzhengjie-org.apache.spark.deploy.master.Master--s105.out
[yinzhengjie@s105 ~]$ jps
Master
Jps
DFSZKFailoverController
NameNode
[yinzhengjie@s105 ~]$
5>.连接spark集群
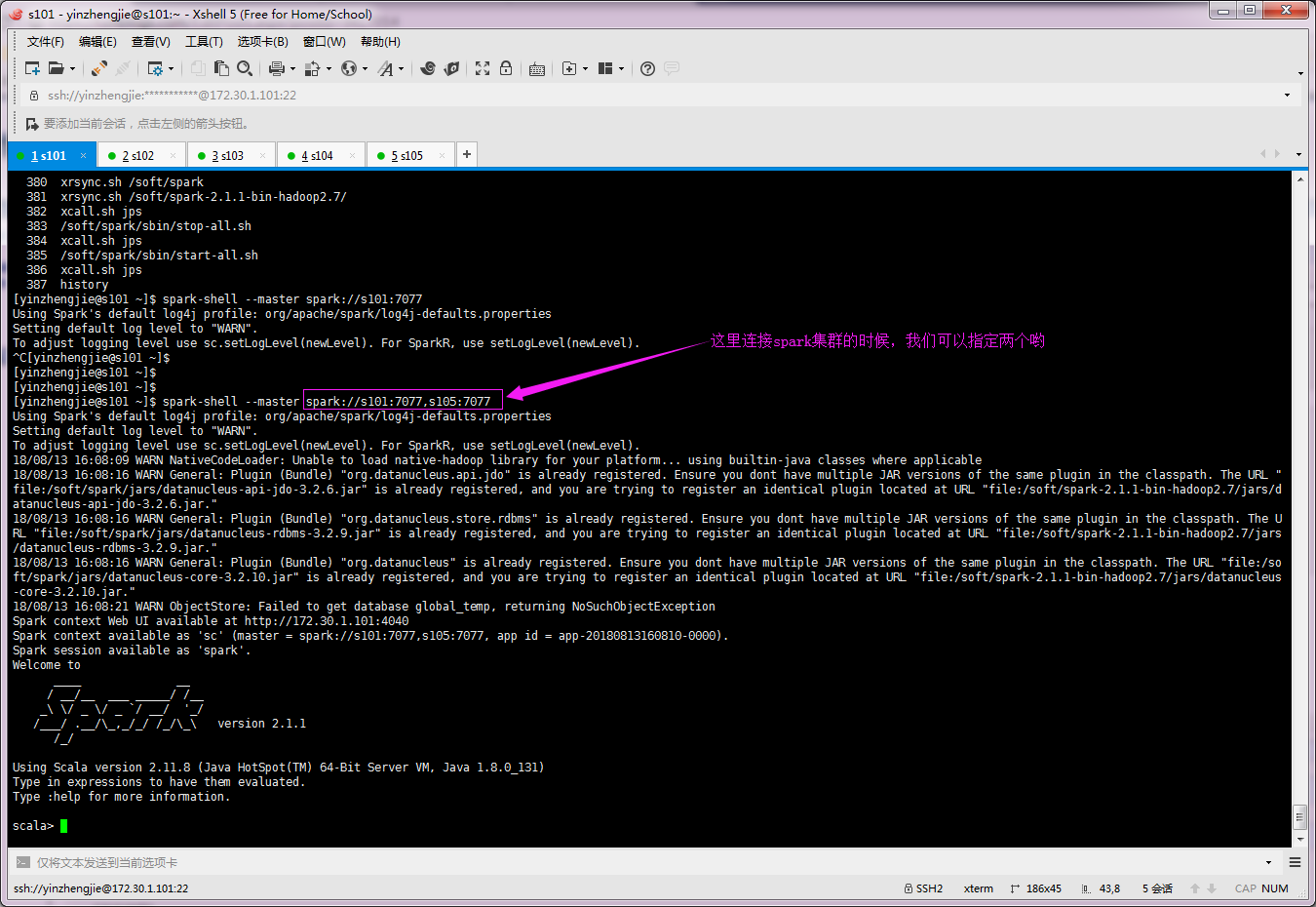
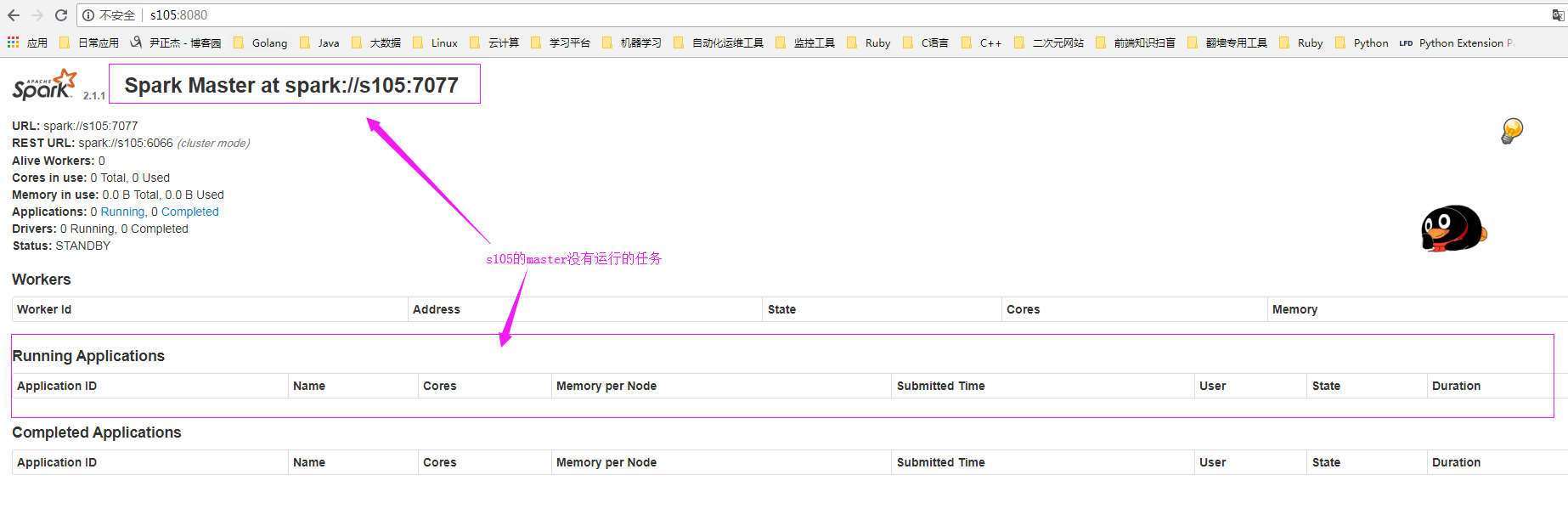
6>.查看master节点的webUI信息
s105的master信息如下:(此时s105啥也没有,worker没有正确到,正在运行的任务也没有争取到)
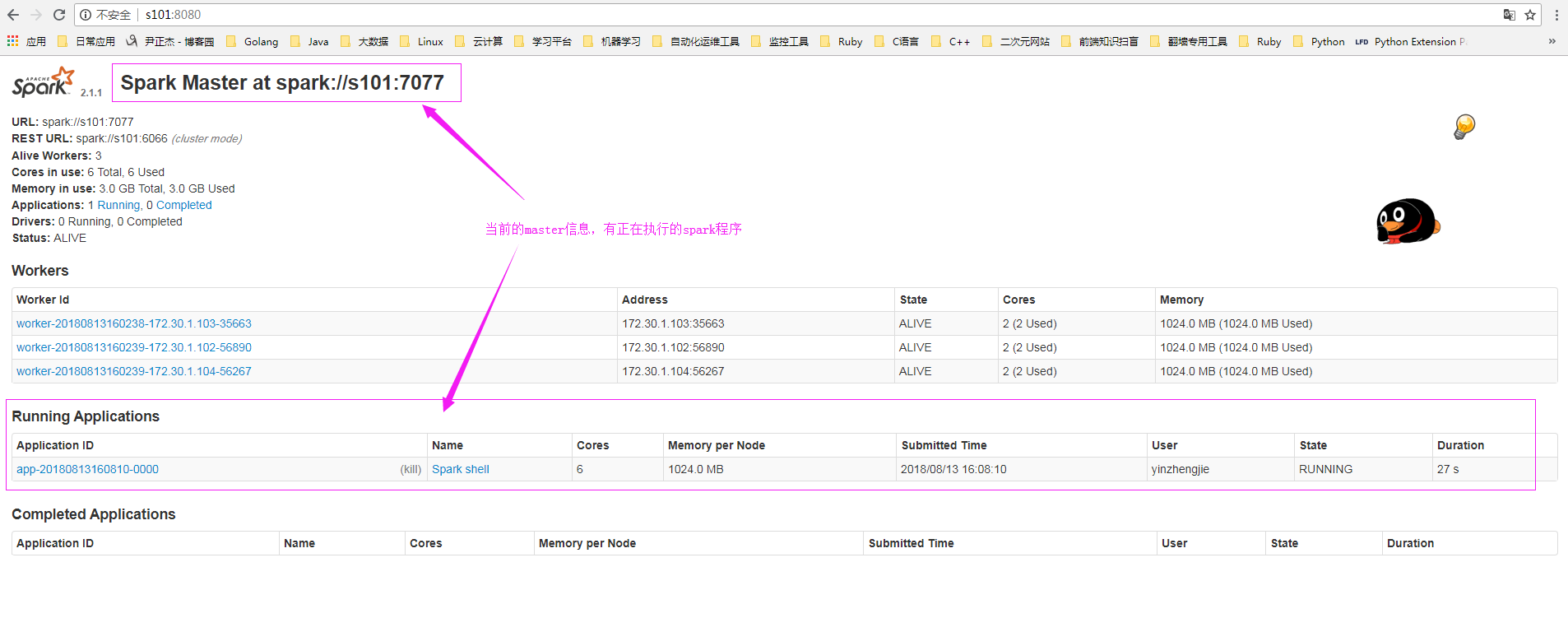
s101的master信息如下:(你会发现目前的正在工作的master是s101)
7>.手动杀死s101的master进程
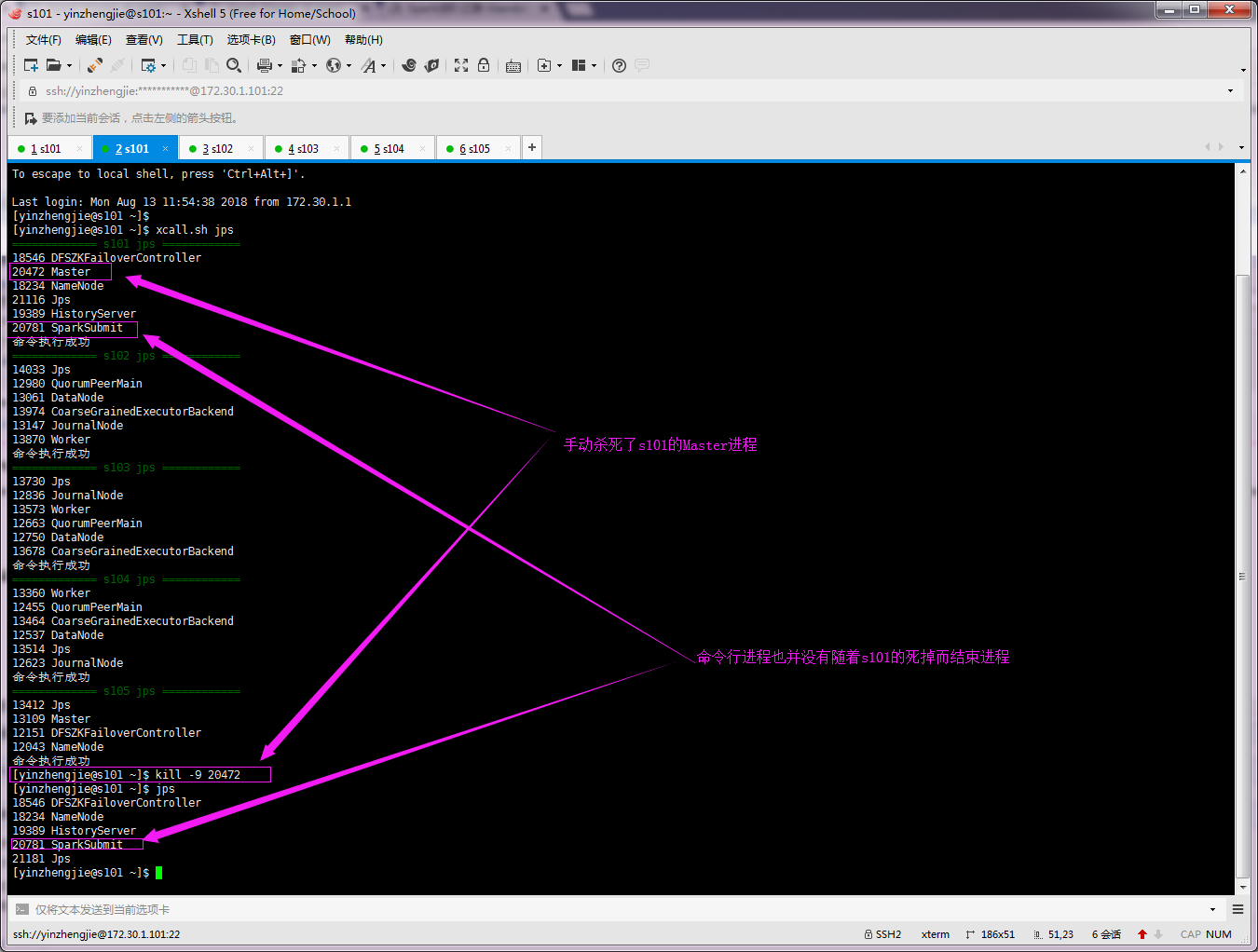
8>.查看spark-shell命令行是否可以正常工作
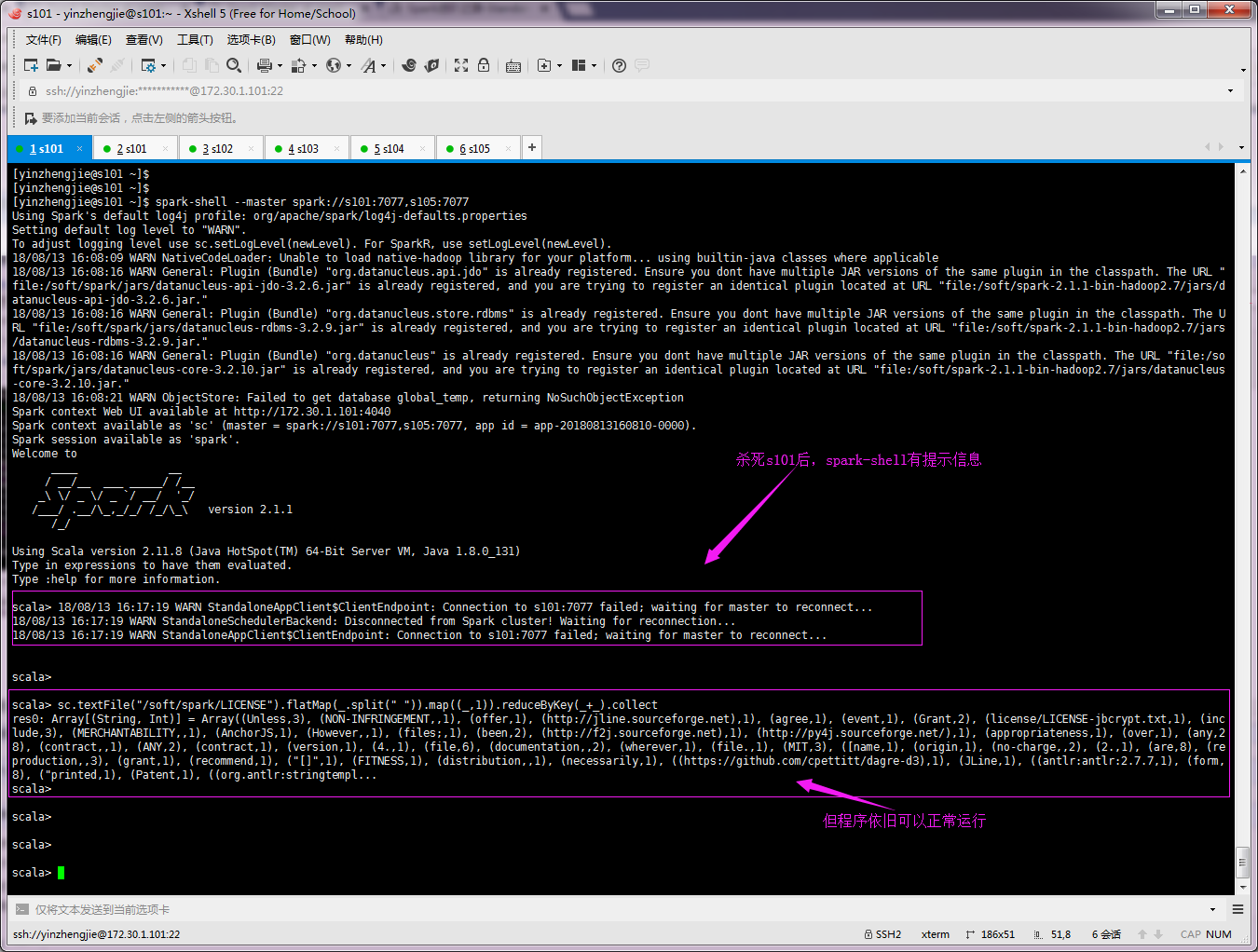
9>.检查集群中是否还有正常的master存活(很显然,此时一定是s105接管了任务)
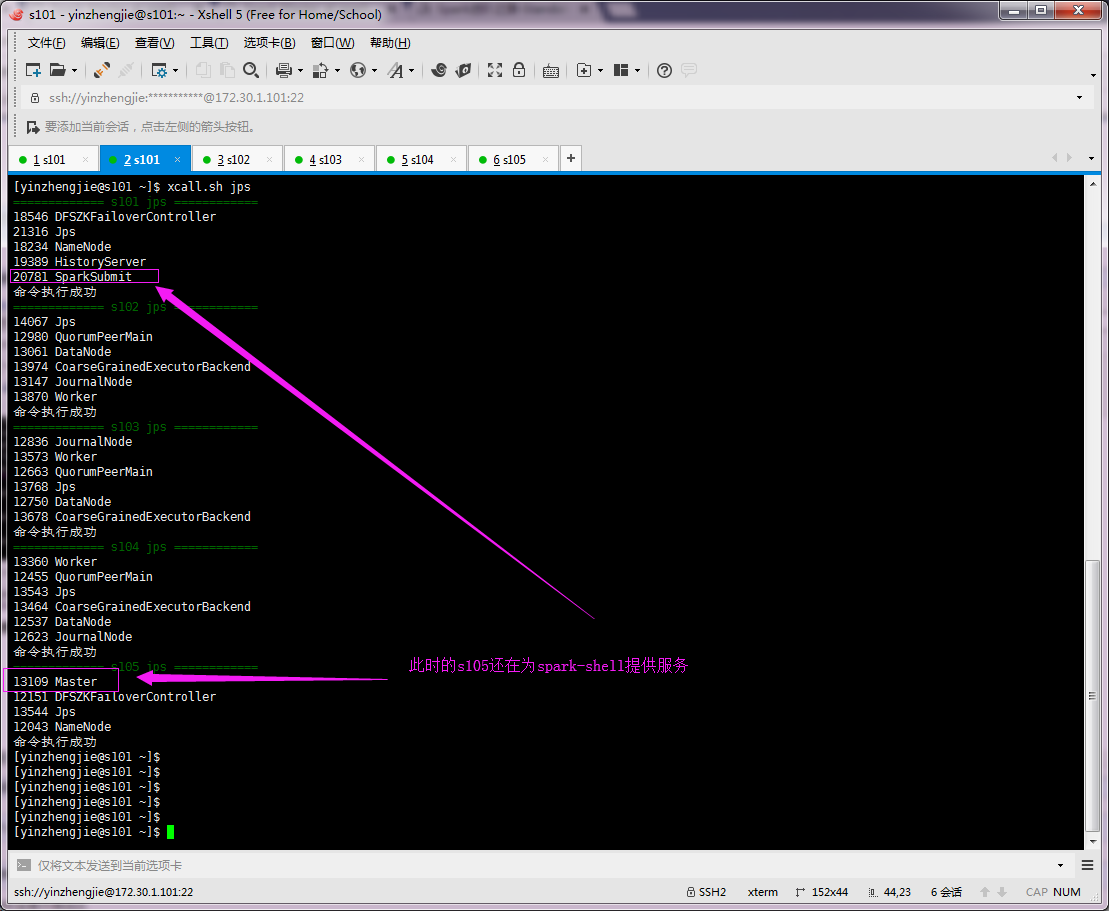
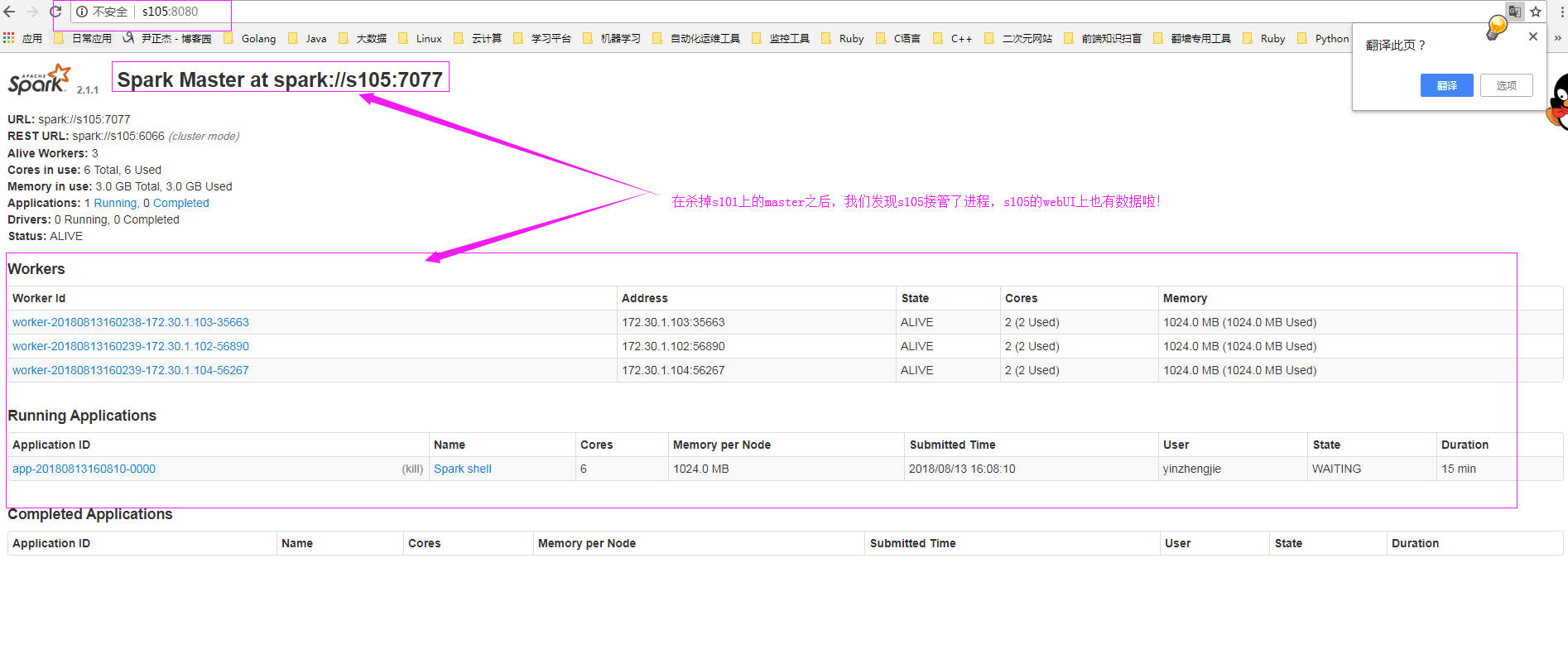
10>.再次查看s105的webUI界面
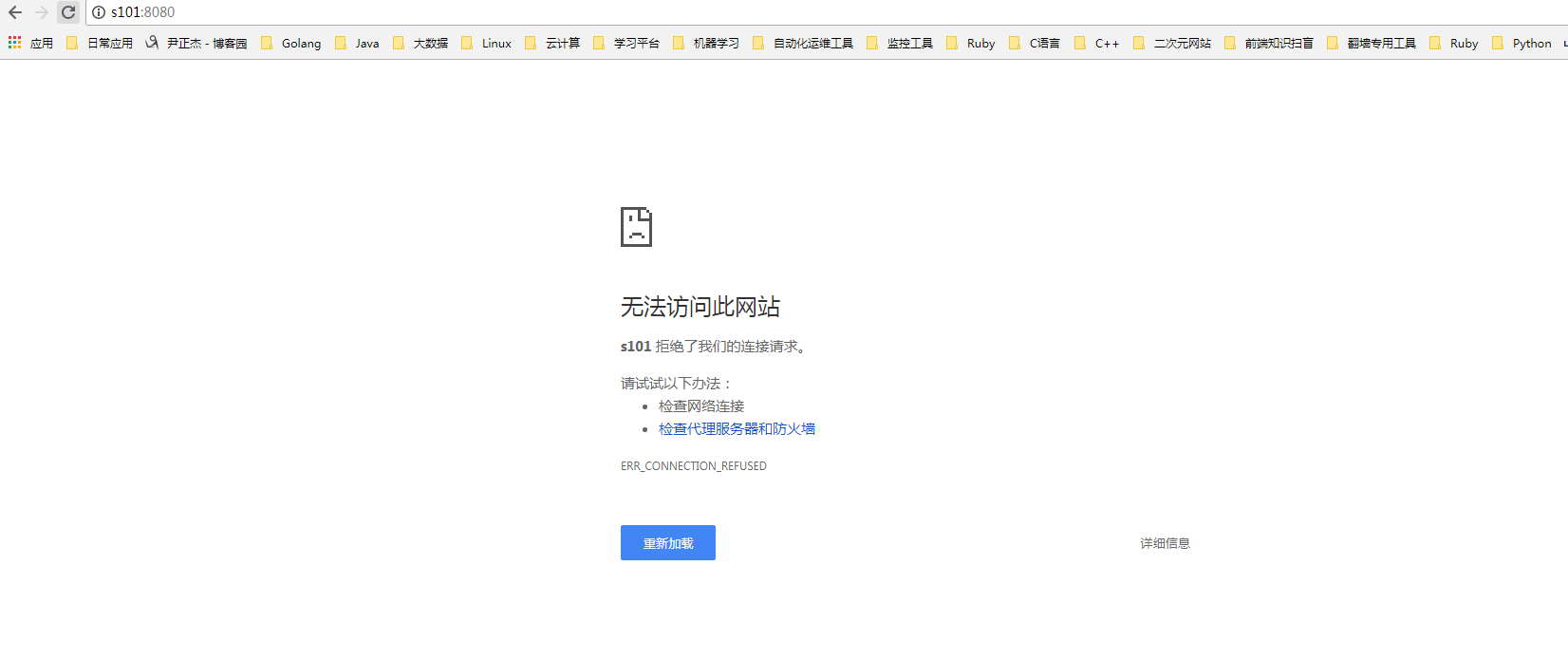
由于s101的master进程已经被我们手动杀死了,因此我们无法通过webUI的形式访问它了:
Spark进阶之路-Spark HA配置的更多相关文章
- Spark进阶之路-Spark提交Jar包执行
Spark进阶之路-Spark提交Jar包执行 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 在实际开发中,使用spark-submit提交jar包是很常见的方式,因为用spark ...
- Spark进阶之路-日志服务器的配置
Spark进阶之路-日志服务器的配置 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 如果你还在纠结如果配置Spark独立模式(Standalone)集群,可以参考我之前分享的笔记: ...
- Spark进阶之路-Standalone模式搭建
Spark进阶之路-Standalone模式搭建 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Spark的集群的准备环境 1>.master节点信息(s101) 2&g ...
- Scala进阶之路-Spark本地模式搭建
Scala进阶之路-Spark本地模式搭建 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Spark简介 1>.Spark的产生背景 传统式的Hadoop缺点主要有以下两 ...
- Scala进阶之路-Spark底层通信小案例
Scala进阶之路-Spark底层通信小案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Spark Master和worker通信过程简介 1>.Worker会向ma ...
- Scala进阶之路-Spark独立模式(Standalone)集群部署
Scala进阶之路-Spark独立模式(Standalone)集群部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 我们知道Hadoop解决了大数据的存储和计算,存储使用HDFS ...
- Spark集群高可用HA配置
本文中的Spark集群包含三个节点,分别是Master,Worker1,Worker2. 1.在Master机器上安装Zookeeper,本文安装在/usr/etc目录下 2.在Master机器配置Z ...
- 树莓派进阶之路 (012) - 树莓派配置文档 config.txt 说明
原文连接:http://elinux.org/RPi_config.txt 由于树莓派并没有传统意义上的BIOS, 所以现在各种系统配置参数通常被存在”config.txt”这个文本文件中. 树莓派的 ...
- Spark:Master High Availability(HA)高可用配置的2种实现
Spark Standalone集群是Master-Slaves架构的集群模式,和大部分的Master-Slaves结构集群一样,存在着Master单点故障的问题.如何解决这个单点故障的问题,Spar ...
随机推荐
- 软件工程项目之摄影App(总结)
软件工程项目之摄影App 心得体会: dyh:这次的项目很难做,本来想在里面添加动画效果的,但是找了很多例子都没看明白,能力还是不足够把,还有一个就是数据库在安卓课程里面刚刚涉及到,所以也还没能做出数 ...
- 关于HashMap和Hashtable的区别
Hashtable的应用非常广泛,HashMap是新框架中用来代替Hashtable的类,也就是说建议使用HashMap,不要使用Hashtable.可能你觉得Hashtable很好用,为什么不用呢? ...
- C#-ToString格式化
Int.ToString(format): 格式字符串采用以下形式:Axx,其中 A 为格式说明符,指定格式化类型,xx 为精度说明符,控制格式化输出的有效位数或小数位数,具体如下: 格式说明符 说明 ...
- 【转】单片机HEX文件完全解读
转:http://www.eefocus.com/craftor/blog/10-07/193051_8ce59.html Craftor原创,首发于与非网,转载请保留此处. HEX文件,是Intel ...
- 伪静态与重定向--RewriteBase
RewriteBase用于设置目录级重写的基准URL,即所有的重定向都是基于这个URL.内部重定向可能看不出效果,但是在外部重定向(使用R flag后),如果不手动指定 / 为根目录,那么就会去整个磁 ...
- Aspose for Maven 使用
https://blog.aspose.com/2014/08/12/aspose-for-maven-aspose-cloud-maven-repository/ https://marketpla ...
- Java之JSON处理(JSONObject、JSONArray)
依赖包:json-20180130.jar MAVEN地址: <dependency> <groupId>org.json</groupId> <artifa ...
- indicator function指示函数
指示函数 在集合论中,指示函数是定义在某集合X上的函数,表示其中有哪些元素属于某一子集A. 中文名 指示函数 外文名 indicator function 相关学科 数学.组合数学 其他称呼 特征 ...
- 51Nod - 1107 斜率小于0的连线数量
二维平面上N个点之间共有C(n,2)条连线.求这C(n,2)条线中斜率小于0的线的数量. 二维平面上的一个点,根据对应的X Y坐标可以表示为(X,Y).例如:(2,3) (3,4) (1,5) (4, ...
- 自学Python3.2-函数分类(内置函数)
自学Python之路-Python基础+模块+面向对象自学Python之路-Python网络编程自学Python之路-Python并发编程+数据库+前端自学Python之路-django 自学Pyth ...