Python爬虫教程-02-使用urlopen
Spider-02-使用urlopen
做一个最简单的python爬虫,使用爬虫爬取:智联招聘某招聘信息的DOM
urllib
- 包含模块
- urllib.request:打开和读取urls
- urllib.error:包含urllib.request产生的常见错误,使用try捕捉
- urllib.parse:包含解析url的方法
- urllib.robotparse:解析robots.txt文件
robots:机器人协议,放在网站的开头,供给爬虫读取,当爬虫读到robots之后,就知道那些是允许爬取的数据,哪些是禁止爬取的数据
(爬虫道德问题:1.不许过频繁爬取 2.不许爬取禁止内容) - 案例v1 (使用PyCharm开发工具,配置python解释器,创建python文件)
- 我把代码放在github了,可以直接下载,地址:
- py01v1.py文件:https://xpwi.github.io/py/py爬虫/py01v1.py
- request.py文档文件:https://xpwi.github.io/py/py爬虫/request.py
# py01v1.py
from urllib import request
# 使用urllib.request请求一个网页的内容,并把内容打印出来
if __name__ == '__main__':
# 定义需要爬的页面
url = "https://jobs.zhaopin.com/CC375882789J00033399409.htm"
# 打开相应url并把页面作为返回
rsp = request.urlopen(url)
# 按住Ctrl键不送,同时点击urlopen,可以查看文档,有函数的具体参数和使用方法
# 把返回结果读取出来
html = rsp.read()
print(html)
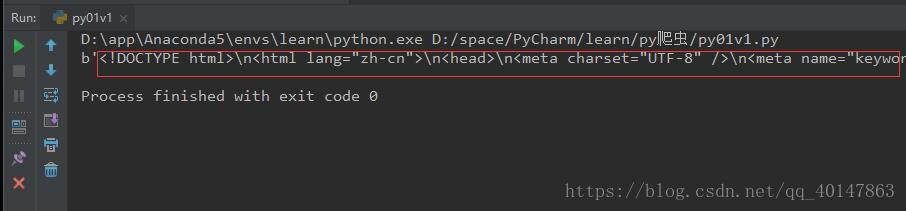
上面简单几行代码就可以爬取页面的HTML代码了
右键运行,截图如下
但是,我们爬取到的代码是不能自行显示中文的,需要解码处理
py02v1.py文件:https://xpwi.github.io/py/py爬虫/py02v1.py
# py02v1.py
from urllib import request
if __name__ == '__main__':
url = "https://jobs.zhaopin.com/CC375882789J00033399409.htm"
rsp = request.urlopen(url)
# 按住Ctrl键不送,同时点击urlopen,可以查看文档,有函数的具体参数和使用方法
html = rsp.read()
# 解码
html = html.decode()
print(html)
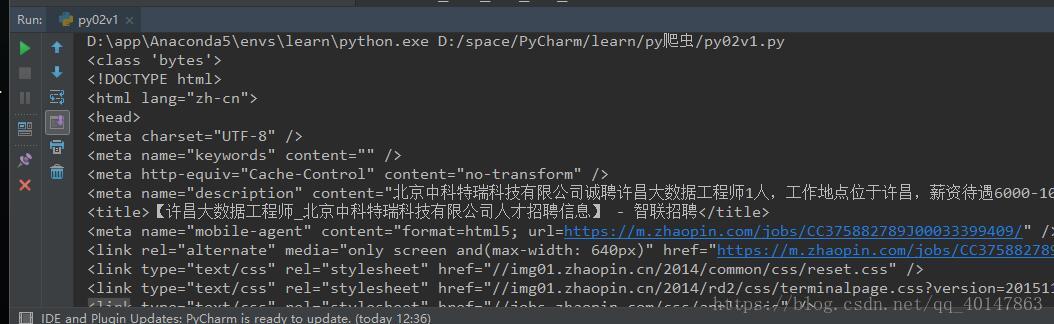
解码后效果:
恭喜你,最简单的爬虫就已经学会啦!
如果运行失败,可能是
1.【爬取的连接失效】,更换最新的地址就可以了
2.【Python环境问题】,这里不做仔细介绍,请自行【百度】解决,也可联系博主
QQ:1370911284
微信:18322295195
更多文章链接:Python 爬虫随笔
- 本笔记学习于图灵学院python全栈课程
- 本笔记不允许任何个人和组织转载
Python爬虫教程-02-使用urlopen的更多相关文章
- Python爬虫教程-01-爬虫介绍
Spider-01-爬虫介绍 Python 爬虫的知识量不是特别大,但是需要不停和网页打交道,每个网页情况都有所差异,所以对应变能力有些要求 爬虫准备工作 参考资料 精通Python爬虫框架Scrap ...
- Python爬虫教程-00-写在前面
鉴于好多人想学Python爬虫,缺没有简单易学的教程,我将在CSDN和大家分享Python爬虫的学习笔记,不定期更新 基础要求 Python 基础知识 Python 的基础知识,大家可以去菜鸟教程进行 ...
- Python爬虫教程-11-proxy代理IP,隐藏地址(猫眼电影)
Python爬虫教程-11-proxy代理IP,隐藏地址(猫眼电影) ProxyHandler处理(代理服务器),使用代理IP,是爬虫的常用手段,通常使用UserAgent 伪装浏览器爬取仍然可能被网 ...
- Python爬虫教程-10-UserAgent和常见浏览器UA值
Python爬虫教程-10-UserAgent和常见浏览器UA值 有时候使用爬虫会被网站封了IP,所以需要去模拟浏览器,隐藏用户身份, UserAgent 包含浏览器信息,用户身份,设备系统信息 Us ...
- Python爬虫教程-09-error 模块
Python爬虫教程-09-error模块 今天的主角是error,爬取的时候,很容易出现错,所以我们要在代码里做一些,常见错误的处,关于urllib.error URLError URLError ...
- Python爬虫教程-08-post介绍(百度翻译)(下)
Python爬虫教程-08-post介绍(下) 为了更多的设置请求信息,单纯的通过urlopen已经不太能满足需求,此时需要使用request.Request类 构造Request 实例 req = ...
- Python爬虫教程-07-post介绍(百度翻译)(上)
Python爬虫教程-07-post介绍(百度翻译)(上) 访问网络两种方法 get: 利用参数给服务器传递信息 参数为dict,使用parse编码 post :(今天给大家介绍的post) 一般向服 ...
- Python爬虫教程-25-数据提取-BeautifulSoup4(三)
Python爬虫教程-25-数据提取-BeautifulSoup4(三) 本篇介绍 BeautifulSoup 中的 css 选择器 css 选择器 使用 soup.select 返回一个列表 通过标 ...
- Python爬虫教程-24-数据提取-BeautifulSoup4(二)
Python爬虫教程-24-数据提取-BeautifulSoup4(二) 本篇介绍 bs 如何遍历一个文档对象 遍历文档对象 contents:tag 的子节点以列表的方式输出 children:子节 ...
随机推荐
- pycharm+gitee
Git操作 前言: 由于各种原因,很多时候我们写代码的电脑并不会随身携带,所以有的时候突发灵感想继续写代码就变得难以实现.相信大部分同学对此都有了解,那就通过代码托管平台来管理.原本想用GitHub来 ...
- P3440 [POI2006]SZK-Schools
传送门 应该是很显然的费用流模型吧... $S$ 向所有学校连边,流量为 $1$,费用为 $0$(表示每个学校要选一个编号) 学校向范围内的数字连边,流量为 $1$,费用为 $c|m-m'|$(表示学 ...
- mysql数据库使用脚本实现分库备份过程
一条命令解决分库分表备份: [root@db01 data]# mysql -uroot -p123456 -e "show databases;"|egrep -v " ...
- How to deal with the problem '<' in OpenERP's view file
In this case,if you write some stirng in your fields which contains '<' , OpenERP will give a err ...
- MVC,MVP,MVVM的区别
MVC模型关注的是Model的不变,所以,在MVC模型里,Model不依赖于View,但是 View是依赖于Model的.不仅如此,因为有一些业务逻辑在View里实现了,导致要更改View也是比较困难 ...
- 数据库~Mysql派生表注意的几点~关于百万数据的慢查询问题
基础概念 派生表是从SELECT语句返回的虚拟表.派生表类似于临时表,但是在SELECT语句中使用派生表比临时表简单得多,因为它不需要创建临时表的步骤. 术语:*派生表*和子查询通常可互换使用.当SE ...
- 利用OC对象的消息重定向forwardingTargetForSelector方法构建高扩展性的滤镜功能
在OC中,当像一个对象发送消息,而对象找到消息后,从它的类方法列表,父类方法列表,一直找到根类方法列表都没有找到与这个选择子对应的函数指针.那么这个对象就会触发消息转发机制. OC对象的继承链和isa ...
- git hub 建立公钥
1. 执行 $ eval "$(ssh-agent -s)" 2. 增加 ssh $ ssh-add ~/.ssh/id_rsa 3. 复制 生成的key (执行下面命令后就相当 ...
- this说明
这个This就表示当前实例的对象,用this可访问属性,this.Fist:
- Button 控件
Button 控件是由system.Windows.Forms.button类提供,该控件最常用使用就是编写处理按钮的Click事件及MouseEnter事件代码 常用属性 Text按钮的说明 Ima ...