Python爬虫教程-24-数据提取-BeautifulSoup4(二)
Python爬虫教程-24-数据提取-BeautifulSoup4(二)
本篇介绍 bs 如何遍历一个文档对象
遍历文档对象
- contents:tag 的子节点以列表的方式输出
- children:子节点以迭代器形式返回
- descendants:所有子孙节点
- string:用string打印出标签的具体内容,不带有标签,只有内容
- 案例代码27bs3.py文件:https://xpwi.github.io/py/py爬虫/py27bs3.py
# BeautifulSoup 的使用案例
# 遍历文档对象
from urllib import request
from bs4 import BeautifulSoup
url = 'http://www.baidu.com/'
rsp = request.urlopen(url)
content = rsp.read()
soup = BeautifulSoup(content, 'lxml')
# bs 自动解码
content = soup.prettify()
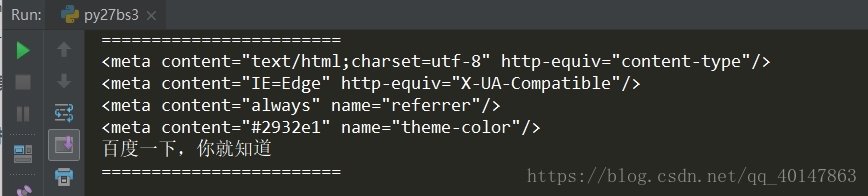
print("=="*12)
# 使用 contents
for node in soup.head.contents:
if node.name == "meta":
print(node)
if node.name == "title":
print(node.string)
print("=="*12)
运行结果
常用string打印出标签的具体内容,不带有标签,只有内容
当然,如果觉得遍历太耗费资源,没有必要遍历的时候,可以使用搜索
搜索文档对象
- find_all(name, attrs, recursive, text, ** kwargs)
- 使用find_all(),返回的列表格式,也就是说如果 find_all(name='meta') ,如果有多个 meta 就以列表形式返回
- name 参数:按照哪个字符搜索,可以传入的内容为
- 1.字符串
- 2.正则表达式,使用正则需要编译:
例如:我们需要打印所有以 me 开头的标签内容
tags = soup.find_all(re.compile('^me')) - 3.也可以是列表
- keyword 参数,可以用来表示属性
- text:对应 tag 的文本值
- 案例代码27bs4.py文件:https://xpwi.github.io/py/py爬虫/py27bs4.py
# BeautifulSoup 的使用案例
# 搜索文档对象
from urllib import request
from bs4 import BeautifulSoup
import re
url = 'http://www.baidu.com/'
rsp = request.urlopen(url)
content = rsp.read()
soup = BeautifulSoup(content, 'lxml')
# bs 自动解码
content = soup.prettify()
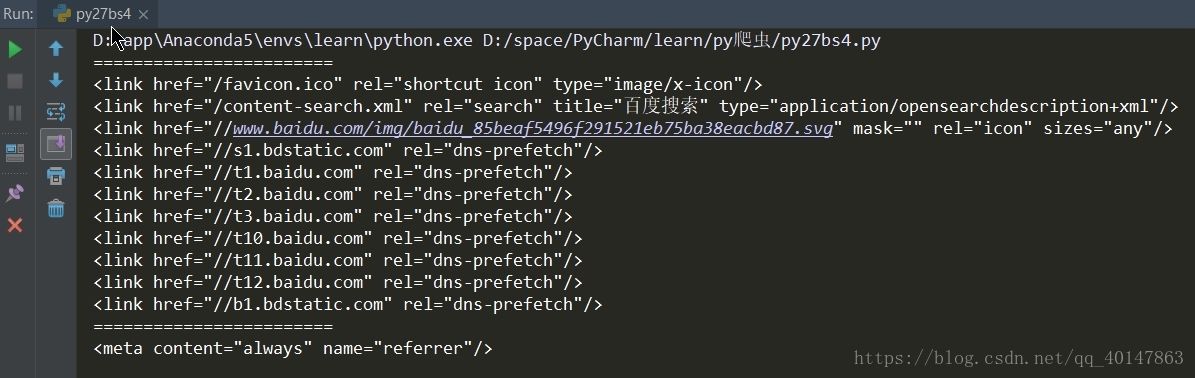
# 使用 find_all
# 使用 name 参数
print("=="*12)
tags = soup.find_all(name='link')
for i in tags:
print(i)
# 使用正则表达式
print("=="*12)
# 同时使用两个条件
tags = soup.find_all(re.compile('^me'), content='always')
# 这里直接打印 tags 会打印一个列表
for i in tags:
print(i)
运行结果:
因为使用两个条件,所以只匹配到一条 meta
下一篇介绍,BeautifulSoup 的 css 选择器
更多文章链接:Python 爬虫随笔
- 本笔记不允许任何个人和组织转载
Python爬虫教程-24-数据提取-BeautifulSoup4(二)的更多相关文章
- Python爬虫教程-23-数据提取-BeautifulSoup4(一)
Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据,查看文档 https://www.crummy.com/software/BeautifulSoup/bs4/doc. ...
- Python爬虫教程-25-数据提取-BeautifulSoup4(三)
Python爬虫教程-25-数据提取-BeautifulSoup4(三) 本篇介绍 BeautifulSoup 中的 css 选择器 css 选择器 使用 soup.select 返回一个列表 通过标 ...
- Python爬虫教程-19-数据提取-正则表达式(re)
本篇主页内容:match的基本使用,search的基本使用,findall,finditer的基本使用,匹配中文,贪婪与非贪婪模式 Python爬虫教程-19-数据提取-正则表达式(re) 正则表达式 ...
- Python爬虫教程-01-爬虫介绍
Spider-01-爬虫介绍 Python 爬虫的知识量不是特别大,但是需要不停和网页打交道,每个网页情况都有所差异,所以对应变能力有些要求 爬虫准备工作 参考资料 精通Python爬虫框架Scrap ...
- Python爬虫教程-00-写在前面
鉴于好多人想学Python爬虫,缺没有简单易学的教程,我将在CSDN和大家分享Python爬虫的学习笔记,不定期更新 基础要求 Python 基础知识 Python 的基础知识,大家可以去菜鸟教程进行 ...
- Python爬虫教程-18-页面解析和数据提取
本篇针对的数据是已经存在在页面上的数据,不包括动态生成的数据,今天是对HTML中提取对我们有用的数据,去除无用的数据 Python爬虫教程-18-页面解析和数据提取 结构化数据:先有的结构,再谈数据 ...
- python爬虫的页面数据解析和提取/xpath/bs4/jsonpath/正则(1)
一.数据类型及解析方式 一般来讲对我们而言,需要抓取的是某个网站或者某个应用的内容,提取有用的价值.内容一般分为两部分,非结构化的数据 和 结构化的数据. 非结构化数据:先有数据,再有结构, 结构化数 ...
- Python爬虫教程-34-分布式爬虫介绍
Python爬虫教程-34-分布式爬虫介绍 分布式爬虫在实际应用中还算是多的,本篇简单介绍一下分布式爬虫 什么是分布式爬虫 分布式爬虫就是多台计算机上都安装爬虫程序,重点是联合采集.单机爬虫就是只在一 ...
- Python爬虫教程-33-scrapy shell 的使用
本篇详细介绍 scrapy shell 的使用,也介绍了使用 xpath 进行精确查找 Python爬虫教程-33-scrapy shell 的使用 scrapy shell 的使用 条件:我们需要先 ...
随机推荐
- GTID 笔记
1.生成事务 root@(none)>use pxc01 Database changed root@pxc01>create table tbx(id int); Query OK, 0 ...
- 启用mysql日志记录执行过的sql
在mysql命令行或者客户端管理工具中执行:SHOW VARIABLES LIKE "general_log%"; 结果: general_log OFF general_log_ ...
- css提取数据2个常用方法
提取标签里的内容 所谓数据就是HTML里标签的内容,如下面红色字体,就是标签内容 <title>我只是个实验 - SCRAPY</title> 提取标签里的数据,标签可以是ti ...
- final学习
类加载过程 1.装载:查找和导入Class文件 2.链接:其中解析步骤是可以选择的 (a)检查:检查载入的class文件数据的正确性 (b)准备:给类的静态变量分配存储空间 (c)解析:将符号引用转成 ...
- thinkPhP + Apache + PHPstorm整合框架
最近在学习使用 ThinkPhP,网上很多都是用一些整合好的服务框架,为了学习,在这里我简单的对Apache.PHP做一个原生的整合,希望对你有帮助. 步骤: ①下载 thinkPHP.PHP.Apa ...
- Java super和this小结
区别 this() / this. super() / super. 功能 调用本类构造.方法.属性 调用父类构造.方法.属性 操作方法 先查找本类是否有制定的调用结构,如果没有则调用父类 直接调用父 ...
- Mac上实现对Python的版本切换
最近朋友邀请我帮忙写个比特币自动化交易程序,要求的平台是Okex,用Python写,之前到是自己学过一点自动化交易,不过是MT5的.看了一下Okex提供的API接口,和MT5不一样,它并没有现成的ID ...
- MySQL修改提示符
MySQL提示符 \D 完整日期 \d 当前数据库 \h 服务器名称 \u 当前用户 1.连接之前修改提示符 mysql -uroot -proot --prompt [MySQL提示符] 2.连接之 ...
- 我的Python升级打怪之路【二】:Python的基本数据类型及操作
基本数据类型 1.数字 int(整型) 在32位机器上,整数的位数是32位,取值范围是-2**31~2--31-1 在64位系统上,整数的位数是64位,取值范围是-2**63~2**63-1 clas ...
- 2019美国大学生数学建模竞赛B题(思路)
建模比赛已经过去三天了,但留校的十多天里,自己的收获与感受依然长存于心.下面的大致流程,很多并没有细化,下面很多情况都是在假设下进行的,比如假设飞机能够来回运送药品,运货无人机就只运货,在最大视距下侦 ...