第2章 RDD编程(2.1-2.2)
第2章 RDD编程
2.1 编程模型
在Spark中,RDD被表示为对象,通过对象上的方法调用来对RDD进行转换。经过一系列的transformations定义RDD之后,就可以调用actions触发RDD的计算,action可以是向应用程序返回结果(count, collect等),或者是向存储系统保存数据(saveAsTextFile等)。在Spark中,只有遇到action,才会执行RDD的计算(即延迟计算),这样在运行时可以通过管道的方式传输多个转换。
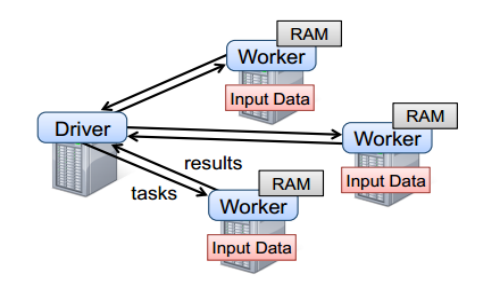
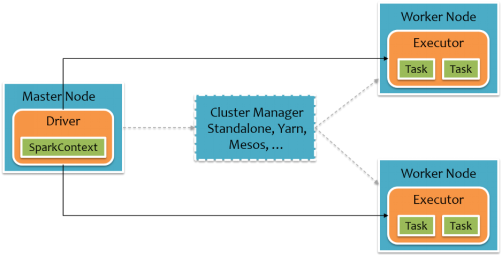
要使用Spark,开发者需要编写一个Driver程序,它被提交到集群以调度运行Worker,如下图所示。Driver中定义了一个或多个RDD,并调用RDD上的action,Worker则执行RDD分区计算任务。
2.2 RDD创建
在Spark中创建RDD的创建方式大概可以分为三种:从集合中创建RDD;从外部存储创建RDD;从其他RDD创建。
由一个已经存在的Scala集合创建,集合并行化。
val rdd1 = sc.parallelize(Array(1,2,3,4,5,6,7,8))
而从集合中创建RDD,Spark主要提供了两种函数:parallelize和makeRDD。我们可以先看看这两个函数的声明:
def parallelize[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T]
def makeRDD[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T]
def makeRDD[T: ClassTag](seq: Seq[(T, Seq[String])]): RDD[T]
我们可以从上面看出makeRDD有两种实现,而且第一个makeRDD函数接收的参数和parallelize完全一致。其实第一种makeRDD函数实现是依赖了parallelize函数的实现,来看看Spark中是怎么实现这个makeRDD函数的:
def makeRDD[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T] = withScope {
parallelize(seq, numSlices)
}
我们可以看出,这个makeRDD函数完全和parallelize函数一致。但是我们得看看第二种makeRDD函数函数实现了,它接收的参数类型是Seq[(T, Seq[String])],Spark文档的说明是:
Distribute a local Scala collection to form an RDD, with one or more location preferences (hostnames of Spark nodes) for each object. Create a new partition for each collection item.
原来,这个函数还为数据提供了位置信息,来看看我们怎么使用:
scala> val guigu1= sc.parallelize(List(1,2,3))
guigu1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[10] at parallelize at <console>:21
scala> val guigu2 = sc.makeRDD(List(1,2,3))
guigu2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[11] at makeRDD at <console>:21
scala> val seq = List((1, List("slave01")),| (2, List("slave02")))
seq: List[(Int, List[String])] = List((1,List(slave01)),
(2,List(slave02)))
scala> val guigu3 = sc.makeRDD(seq)
guigu3: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[12] at makeRDD at <console>:23
scala> guigu3.preferredLocations(guigu3.partitions(1))
res26: Seq[String] = List(slave02)
scala> guigu3.preferredLocations(guigu3.partitions(0))
res27: Seq[String] = List(slave01)
scala> guigu1.preferredLocations(guigu1.partitions(0))
res28: Seq[String] = List()
我们可以看到,makeRDD函数有两种实现,第一种实现其实完全和parallelize一致;而第二种实现可以为数据提供位置信息,而除此之外的实现和parallelize函数也是一致的,如下:
def parallelize[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T] = withScope {
assertNotStopped()
new ParallelCollectionRDD[T](this, seq, numSlices, Map[Int, Seq[String]]())
}
def makeRDD[T: ClassTag](seq: Seq[(T, Seq[String])]): RDD[T] = withScope {
assertNotStopped()
val indexToPrefs = seq.zipWithIndex.map(t => (t._2, t._1._2)).toMap
new ParallelCollectionRDD[T](this, seq.map(_._1), seq.size, indexToPrefs)
}
都是返回ParallelCollectionRDD,而且这个makeRDD的实现不可以自己指定分区的数量,而是固定为seq参数的size大小。
由外部存储系统的数据集创建,包括本地的文件系统,还有所有Hadoop支持的数据集,比如HDFS、Cassandra、HBase等
scala> val atguigu = sc.textFile("hdfs://hadoop102:9000/RELEASE")
atguigu: org.apache.spark.rdd.RDD[String] = hdfs:// hadoop102:9000/RELEASE MapPartitionsRDD[4] at textFile at <console>:24
第2章 RDD编程(2.1-2.2)的更多相关文章
- 第2章 RDD编程(2.3)
第2章 RDD编程(2.3) 2.3 TransFormation 基本RDD Pair类型RDD (伪集合操作 交.并.补.笛卡尔积都支持) 2.3.1 map(func) 返回一个新的RDD,该 ...
- Learning Spark中文版--第三章--RDD编程(2)
Common Transformations and Actions 本章中,我们浏览了Spark中大多数常见的transformation(转换)和action(开工).在包含特定数据类型的RD ...
- Learning Spark中文版--第三章--RDD编程(1)
本章介绍了Spark用于数据处理的核心抽象概念,具有弹性的分布式数据集(RDD).一个RDD仅仅是一个分布式的元素集合.在Spark中,所有工作都表示为创建新的RDDs.转换现有的RDD,或者调 ...
- 《Spark快速大数据分析》—— 第三章 RDD编程
- Spark学习笔记2:RDD编程
通过一个简单的单词计数的例子来开始介绍RDD编程. import org.apache.spark.{SparkConf, SparkContext} object word { def main(a ...
- 2. RDD编程
2.1 编程模型 在Spark中,RDD被表示为对象,通过对象上的方法调用来对RDD进行转换.经过一系列的transformations定义RDD之后,就可以调用actions触发RDD的计算,act ...
- 《深入浅出Node.js》第7章 网络编程
@by Ruth92(转载请注明出处) 第7章 网络编程 Node 只需要几行代码即可构建服务器,无需额外的容器. Node 提供了以下4个模块(适用于服务器端和客户端): net -> TCP ...
- 《深入浅出Node.js》第4章 异步编程
@by Ruth92(转载请注明出处) 第4章 异步编程 Node 能够迅速成功并流行起来的原因: V8 和 异步 I/O 在性能上带来的提升: 前后端 JavaScript 编程风格一致 一.函数式 ...
- Spark菜鸟学习营Day3 RDD编程进阶
Spark菜鸟学习营Day3 RDD编程进阶 RDD代码简化 对于昨天练习的代码,我们可以从几个方面来简化: 使用fluent风格写法,可以减少对于中间变量的定义. 使用lambda表示式来替换对象写 ...
随机推荐
- goroutine间的同步&协作
Go语言中的同步工具 基础概念 竞态条件(race condition) 一份数据被多个线程共享,可能会产生争用和冲突的情况.这种情况被称为竞态条件,竞态条件会破坏共享数据的一致性,影响一些线程中代码 ...
- 好用到飞起的12个jupyter lab插件
1 简介 jupyter lab作为jupyter notebook的升级改造版,除了更加人性化的交互界面以及更多的用户自主定制功能之外,最吸引人的就是其丰富多样的拓展插件,使得每个使用jupyter ...
- fgdsafhak
- Java数据结构和算法(1)之队列
1.队列的基本概念 队列(queue)是一种特殊的线性表,特殊之处在于它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作,和栈一样,队列是一种操作受限制的线性表.进行插 ...
- MacOS下SpringBoot基础学习
学于黑马和传智播客联合做的教学项目 感谢 黑马官网 传智播客官网 微信搜索"艺术行者",关注并回复关键词"springboot"获取视频和教程资料! b站在线视 ...
- Oracle数据库出现[23000][2291] ORA-02291: integrity constraint (SIMTH.SYS_C005306) violated异常
参考链接 这个异常发生在往中间表中插入数据时,这时出现异常是因为关联的某个表没有插入数据,所以给没有插入数据的关联表插入数据,再给中间表插入数据此时异常就会解决.
- [转]Nginx介绍-反向代理、负载均衡
原文:https://www.cnblogs.com/wcwnina/p/8728391.html 作者:失恋的蔷薇 1. Nginx的产生 没有听过Nginx?那么一定听过它的"同行&qu ...
- win系统下git代码批量克隆,批量更新
@REM 根据实际情况设置GIT路径及本地仓库地址 set path=%path%;"D:\Program Files\Git\cmd" set project_path=F:\g ...
- Nginx配置SSL证书,提高网络安全性
首先区别Http与Https HTTP:是互联网上应用最为广泛的一种网络协议,是一个客户端和服务器端请求和应答的标准(TCP),用于从WWW服务器传输超文本到本地浏览器的传输协议,它可以使浏览器更加高 ...
- 笑了,面试官问我知不知道异步编程的Future。
荒腔走板 大家好,我是 why,欢迎来到我连续周更优质原创文章的第 60 篇. 老规矩,先来一个简短的荒腔走板,给冰冷的技术文注入一丝色彩. 上面这图是我五年前,在学校宿舍拍的. 前几天由于有点事情, ...