Attention & Transformer
Attention & Transformer
seq2seq; attention; self-attention; transformer;
1 注意力机制在NLP上的发展
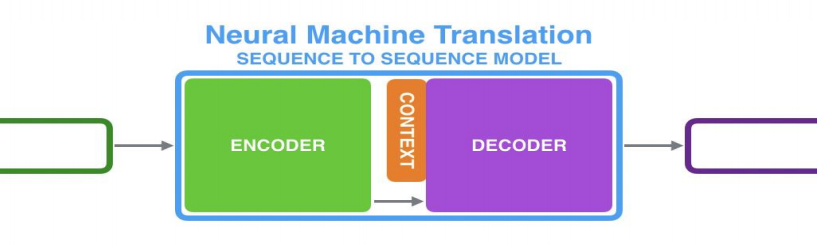
Seq2Seq,Encoder,Decoder
引入Attention,Decoder上对输入的各个词施加不同的注意力 https://wx1.sbimg.cn/2020/09/15/9FZGo.png
Self-attention,Transformer,完全基于自注意力机制

Bert,双向Transformer,mask
XLNet,自回归语言模型,自动编码语言模型,摒弃遮盖
{kind=link}
2 注意力机制
以机器翻译为例;Seq2Seq架构;
2.1 RNN + RNN
Encoder处理输入序列,得到上下文CONTEXT(一个向量,代表源文信息);Decoder处理CONTEXT逐项生成输出序列。
RNN在每个时间步接收两个输入
- 隐状态:上一个时间步传递来的;Decoder的初始隐状态为编码阶段的最后一个隐状态
- 词向量输入:Encoder为输入序列的对应位置的词向量;Decoder为上一个时间步的输出(第一个时间步的输入为Start)
上下文向量定长,模型难处理长句
2.2 RNN+RNN+Attention
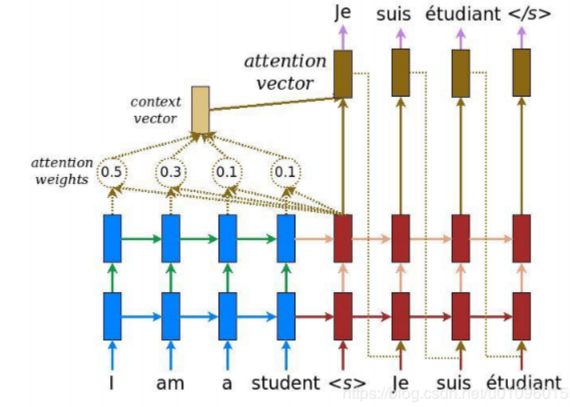
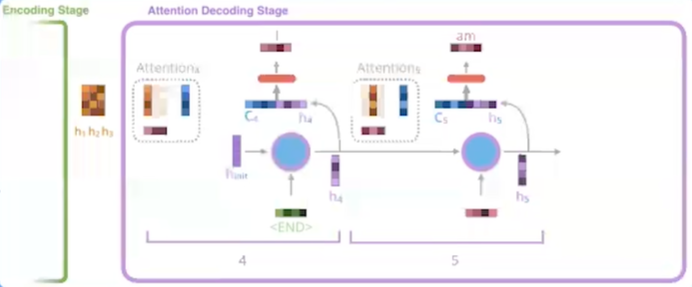
Encoder 向 Decoder 传递更多的数据,不止传递编码阶段的最后一个隐藏状态,而是传递所有隐藏状态。
Decoder增加额外步骤,根据隐状态之间的相关性对不同的隐藏状态打分
为每个编码器隐状态打分;softmax加权;求和

打分后的Encoder隐状态加权后与当前Decoder隐状态结合,作为当前时间步的隐状态输入
Decode 过程中不同的步骤回关注于不同 Encoder 的隐状态
3 Transformer
Attention Is All You Need; self-attention;
3.1 概述
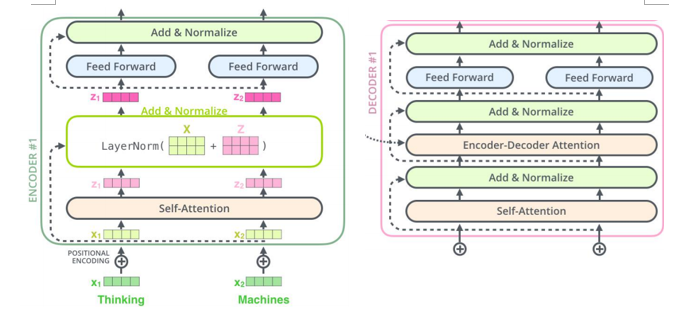
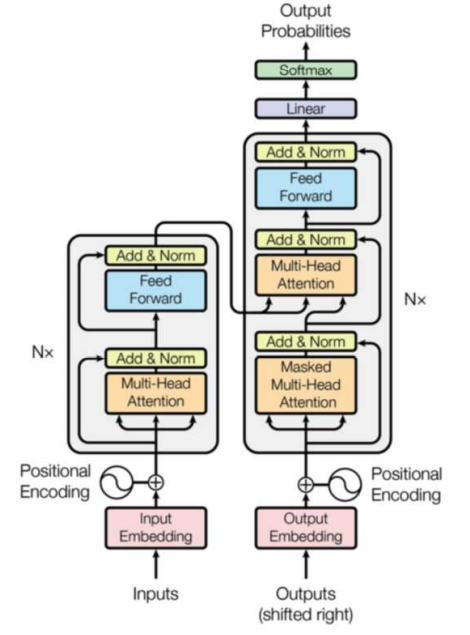
- 仍然由encoder和Decoder组成,完全基于自注意力机制,不使用RNN。
- 编码器和解码器都是一组编码/解码组件组成,原论文使用了6个
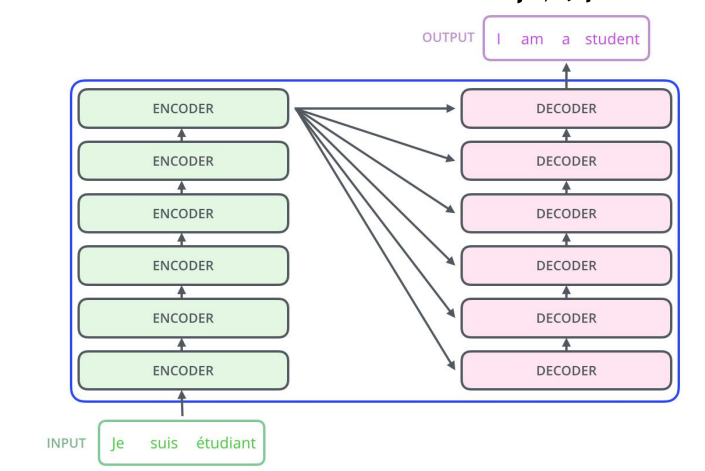
3.2 Encoder 解码器
- 编码器由两个子层:自注意力层(见3.3节)、全连接神经网络
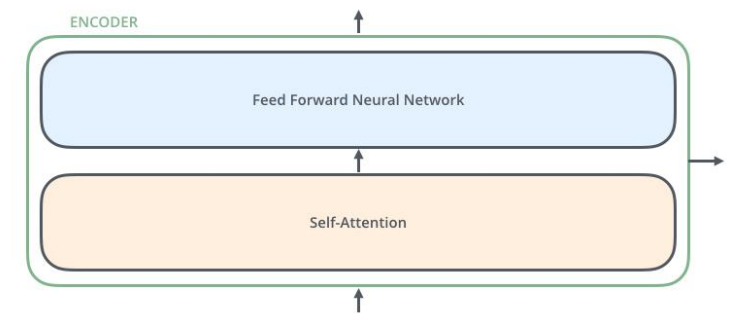
- 每个编码器组件结构相同,但不共享权重。
3.3 自注意力机制
自注意力机制全景图
词嵌入 word embedding
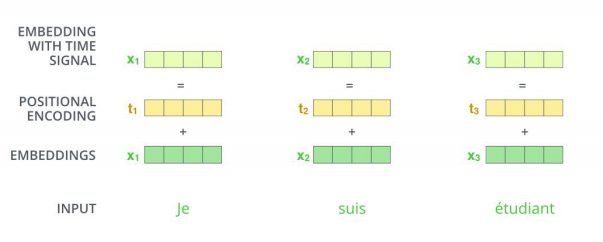
- 发生在最底部的编码器;输入数据[batch_size, word_embedding_size, seq_len];完成嵌入后作为输入经过编码器;每个位置的词并行经过编码器,速度比RNN快。
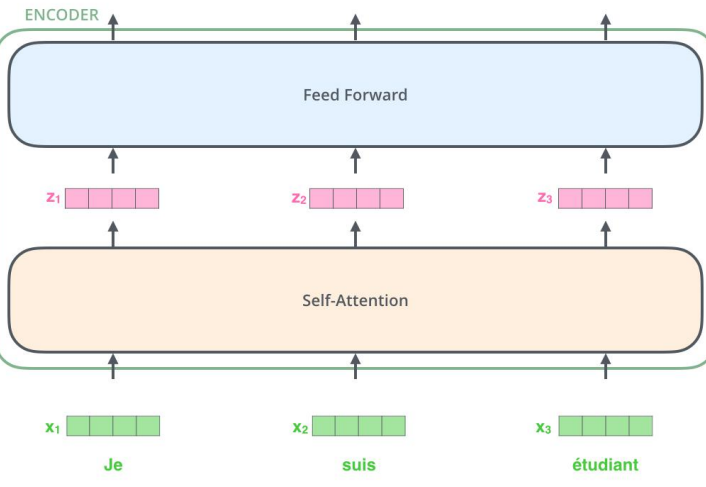
并行运算未考虑到顺序关系,通过位置编码(positional encoding)使词嵌入包含位置信息。
位置编码方式:sin、cos
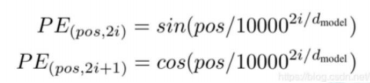
自注意力计算
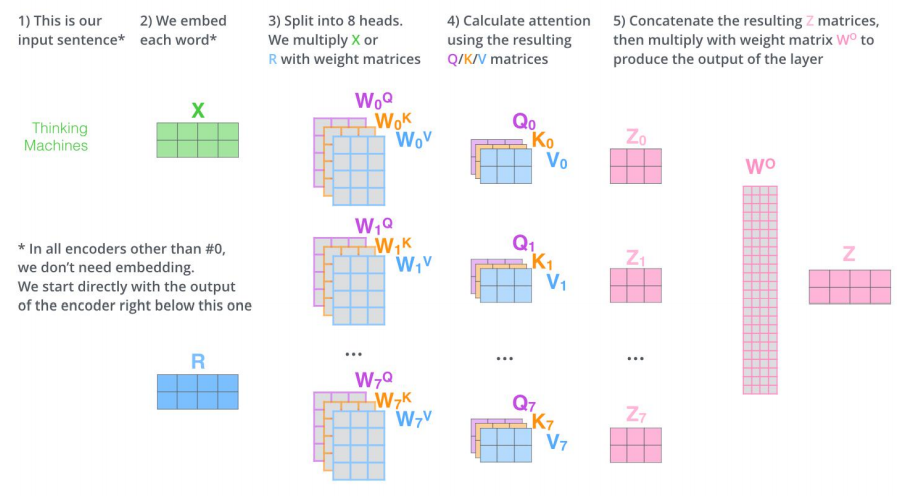
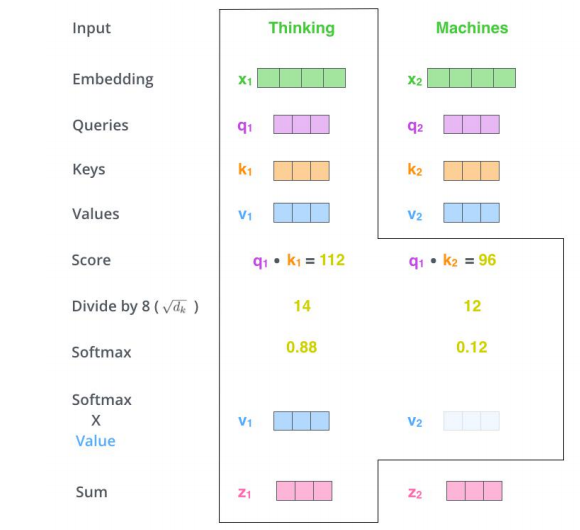
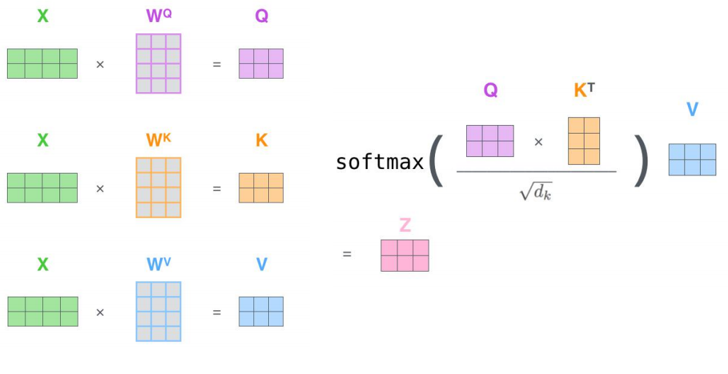
三个参数W(\(W^Q\), \(W^K\),\(W^V\))与输入的向量相乘得到:查询向量q,键向量k,值向量v;新向量维度小于嵌入向量的维数
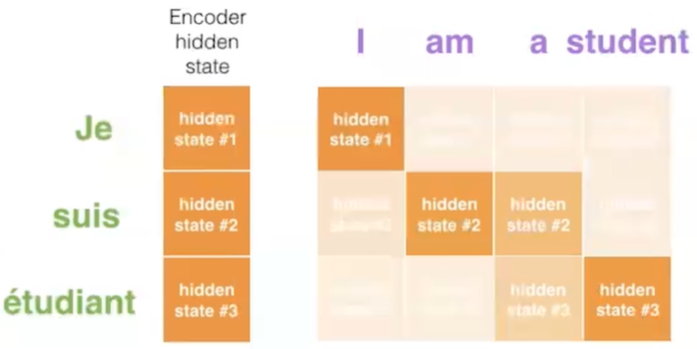
对于一个输入向量,将其q向量与其他词的k向量相乘计算分数;分数高则关系密切
将分数缩放(避免梯度弥散);通过softmax操作转化为概率。
将每个词的v向量用上一步的softmax概率加权求和;得到该输入向量的 z值
234步骤 以矩阵的形式,对多个输入向量并行求z,得到Z矩阵
多头机制
为关注曾提供了多个表示子空间;拓展了模型专注于不同层面的能力
有多组qkv的权重矩阵;e.g. 使用8个关注头则每个编码器解码器会得到8组Z
将所有的Z连接起来和一个权重矩阵\(W^O\)相乘,得到捕捉了所有注意力头的Z矩阵,再将其输入到接下来的全连接层。
3.4 Decoder 解码器
结构:自注意力,encoder-decoder attention,全连接层
自注意力层:仅对输出序列中之前的位置;在softmax之前,把将来生成的位置设置为-inf
encoder-decoder attention
在自注意力层、全连接神经网络之间加入了一个encoder和decoder之间的注意力层,类似seq2seqRNN模型中的注意力。
最后一个Encoder的输出,转换为K和V的集合,每个decoder在其encoder-decoder attention层中使用这些KV。
工作方式与多头注意力类似,区别在于是从Encoder Stack的输出中获取KV。
经过N层decoder,最终的输出通过线性层和softmax层得到输出的词
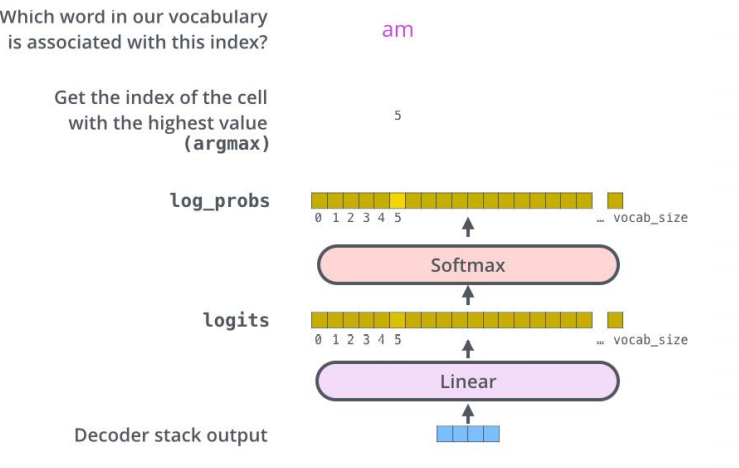
3.5 细节补充
残差和归一化 解码器编码器都有
Attention & Transformer的更多相关文章
- 2. Attention Is All You Need(Transformer)算法原理解析
1. 语言模型 2. Attention Is All You Need(Transformer)算法原理解析 3. ELMo算法原理解析 4. OpenAI GPT算法原理解析 5. BERT算法原 ...
- 深入浅出Transformer
Transformer Transformer是NLP的颠覆者,它创造性地用非序列模型来处理序列化的数据,而且还获得了大成功.更重要的是,NLP真的可以"深度"学习了,各种基于tr ...
- [NLP] REFORMER: THE EFFICIENT TRANSFORMER
1.现状 (1) 模型层数加深 (2) 模型参数量变大 (3) 难以训练 (4) 难以fine-tune 2. 单层参数量和占用内存分析 层 参数设置 参数量与占用内存 1 layer 0.5Bill ...
- 文本建模、文本分类相关开源项目推荐(Pytorch实现)
Awesome-Repositories-for-Text-Modeling repo paper miracleyoo/DPCNN-TextCNN-Pytorch-Inception Deep Py ...
- 关于NLP和深度学习,准备好好看看这个github,还有这篇介绍
这个github感觉很不错,把一些比较新的实现都尝试了: https://github.com/brightmart/text_classification fastText TextCNN Text ...
- BERT解析及文本分类应用
目录 前言 BERT模型概览 Seq2Seq Attention Transformer encoder部分 Decoder部分 BERT Embedding 预训练 文本分类试验 参考文献 前言 在 ...
- ACNet: 特别的想法,腾讯提出结合注意力卷积的二叉神经树进行细粒度分类 | CVPR 2020
论文提出了结合注意力卷积的二叉神经树进行弱监督的细粒度分类,在树结构的边上结合了注意力卷积操作,在每个节点使用路由函数来定义从根节点到叶子节点的计算路径,结合所有叶子节点的预测值进行最终的预测,论文的 ...
- 从RNN到BERT
一.文本特征编码 1. 标量编码 美国:1 中国:2 印度:3 … 朝鲜:197 标量编码问题:美国 + 中国 = 3 = 印度 2. One-hot编码 美国:[1,0,0,0,…,0]中国:[0, ...
- Transformer【Attention is all you need】
前言 Transfomer是一种encoder-decoder模型,在机器翻译领域主要就是通过encoder-decoder即seq2seq,将源语言(x1, x2 ... xn) 通过编码,再解码的 ...
随机推荐
- 换系统之后为什么iMindMap会提示“许可证使用的次数过多”
iMindMap是一款十分受欢迎的思维导图软件,随着12版本的上线,iMindMap新增了很多新用户,最近小编发现有不少新用户在群里反映:"为什么购买iMindMap时说可以支持换机,但是在 ...
- 对于final修饰的类型运算时的表现
我们知道,对于byte,char,这些数据类型加减时都会转化成int在运算,然而,对于final修饰过的数据是不会发生转换的. 比如说 byte b1=1; byte b2=2; byte b3=b1 ...
- 2017年第八届蓝桥杯【C++省赛B组】B、C、D、H 题解
可能因为我使用暴力思维比较少,这场感觉难度不低. B. 等差素数列 #暴力 #枚举 题意 类似:\(7,37,67,97,127,157\) 这样完全由素数组成的等差数列,叫等差素数数列. 上边的数列 ...
- 如何在Linux下关闭ARP协议
方法一:临时关闭ARP协议 echo 1 > /proc/sys/net/ipv4/conf/eth0/arp_ignoreecho 2 > /proc/sys/net/ipv4/conf ...
- 浅谈代理模式与java中的动态代理
代理模式的定义: 代理模式是一个使用律非常高的模式,定义如下: 为其他对象提供一种代理,以控制对这个对象的访问. 类图: 简单的静态代理: public interface IRunner{ //这是 ...
- docker安装myInfluxDB映射本地目录+开机后台自启动
CentOS7环境 1.docker hup库搜索influxdb docker search influxdb 2.拉取influxdb镜像 docker pull influxdb 3.查看已下载 ...
- 基于gin的golang web开发:认证利器jwt
JSON Web Token(JWT)是一种很流行的跨域认证解决方案,JWT基于JSON可以在进行验证的同时附带身份信息,对于前后端分离项目很有帮助. eyJhbGciOiJIUzI1NiIsInR5 ...
- node-sass版本问题
node-sass sass-loader的问题 出现了版本的问题 版本太高 版本不兼容解决方法: cnpm i node-sass@4.14.1 cnpm i sass-loader@7.3.1 - ...
- moviepy音视频剪辑:moviepy中的剪辑相关类及关系
专栏:Python基础教程目录 专栏:使用PyQt开发图形界面Python应用 专栏:PyQt+moviepy音视频剪辑实战 专栏:PyQt入门学习 老猿Python博文目录 老猿学5G博文目录 y在 ...
- 第14.10节 Python中使用BeautifulSoup解析http报文:html标签相关属性的访问
一. 引言 在<第14.8节 Python中使用BeautifulSoup加载HTML报文>中介绍使用BeautifulSoup的安装.导入和创建对象的过程,本节介绍导入后利用Beauti ...