【爬虫】基于PUPPETEER页面爬虫
一、简介
本文简单介绍一下如何用puppeteer抓取页面数据。
二、下载
npm install puppeteer --save-dev
npm install typescrip --save-dev
三、实例
(一)实例一(看一段代码)
import { launch } from 'puppeteer';
async function maoyan_board_run() {
let browser = await launch({
ignoreHTTPSErrors: true,
headless: true,
executablePath: 'D:\\wangxiao\\chrome-win\\chrome-win\\chrome.exe',
args: ['--start-maximized']
});
const page = await browser.newPage();
await page.setViewport({width:1980,height:1080});
await page.goto('https://maoyan.com/board', { waitUntil: 'load' });
console.log(await page.title());
await browser.close();
}
maoyan_board_run();

运行后,答应出当前页面的title,分析一下这段代码做什么
- launch() 模拟启动一个浏览器,注意里面的参数,headless:true 无头模式,不打开浏览器,--start-maximized:浏览器最大化,executablePath:chromiun指定的路径
- browser.newPage() 打开一个新的页面
- page.setViewport() 指定窗口的高宽
- page.goto() 打开某个网站,waitUtil:load 加载完成
(二)分析页面selector
我们先分析一下这个页面,首先我们发现热门排行榜,电影名,主演,上映时间都是在一列一列的,那我们是不是只要获取一个,其他的都一样都获取到了
我们先分析一个名次
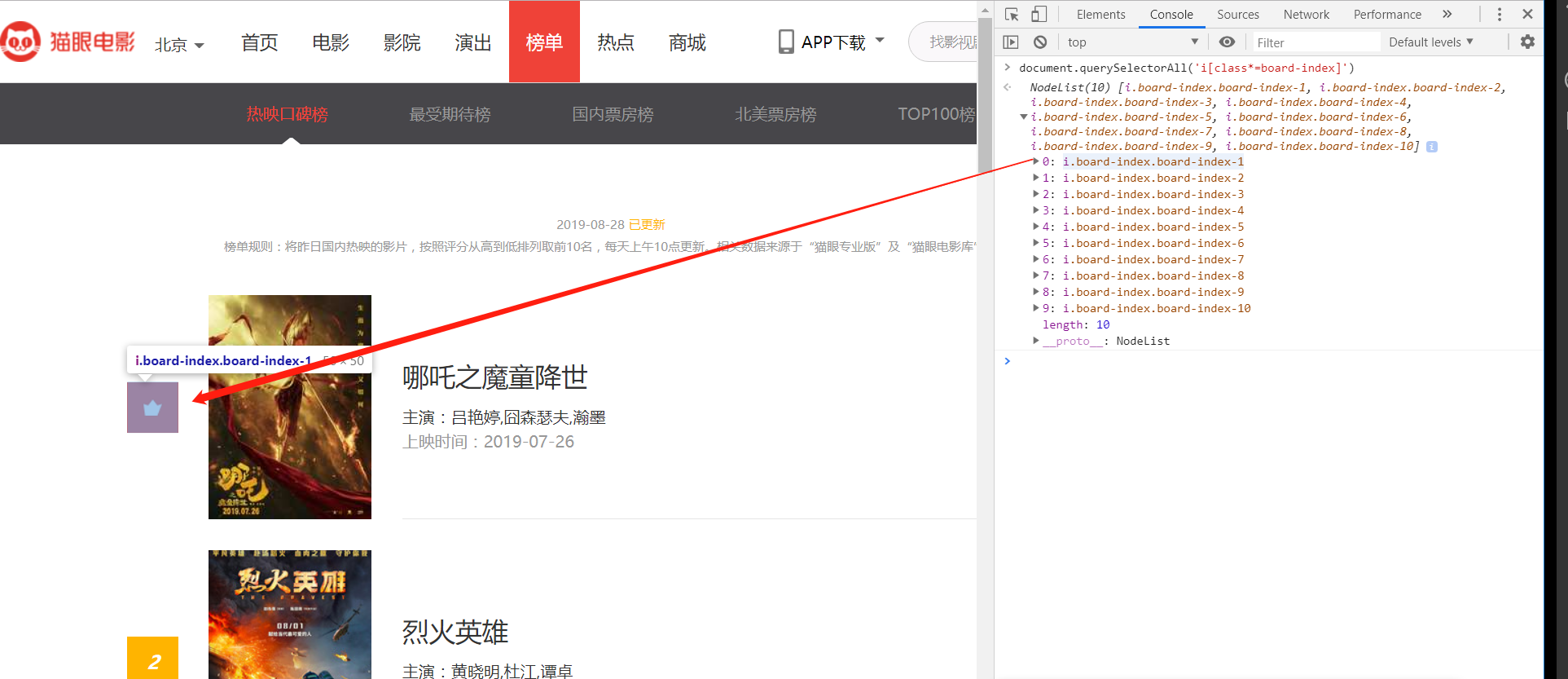
const movie_bank = 'i[class*=board-index]';
根据页面元素分析,要得到标签内的值($$eval用法不用说了,前面已经讲过了)
、

const banks = await page.$$eval(movie_bank, list =>
list.map(n => n.innerHTML)
);
其他内容获取方法依葫芦画瓢,完整代码如下
// 热门口碑榜-名次
const movie_bank = 'i[class*=board-index]';
// 热门口碑榜-名字
const movie_name = '.movie-item-info .name a';
// 热门口碑榜-主演
const movie_star = '.movie-item-info .star';
// 热门口碑榜-上映时间
const movie_releasetime = '.movie-item-info .releasetime';
// 热门口碑榜-图片
const board_lists_images = '.board-wrapper dd .image-link .board-img';
async function maoyan_board_run() {
let browser = await launch({
ignoreHTTPSErrors: true,
headless: true,
executablePath: 'D:\\wangxiao\\chrome-win\\chrome-win\\chrome.exe',
args: ['--start-maximized']
});
const page = await browser.newPage();
await page.setViewport({width:1980,height:1080});
await page.goto('https://maoyan.com/board', { waitUntil: 'load' });
// await autoScroll(page);
const length = await page.evaluate( (movie_bank) => {
return document.querySelectorAll(movie_bank).length;
},movie_bank);
const banks = await page.$$eval(movie_bank, list =>
list.map(n => n.innerHTML)
);
const names = await page.$$eval(movie_name, list =>
list.map(n => n.getAttribute('title'))
);
const stars = await page.$$eval(movie_star, list =>
list.map(n => n.innerHTML.replace(/\n/g,"").replace(/\s/g,""))
);
const releasetimes = await page.$$eval(movie_releasetime, list =>
list.map(n => n.innerHTML)
);
let data = [];
for (let i =0;i<length;i++) {
data.push({
bank:banks[i],
name:names[i],
star:stars[i],
releasetime:releasetimes[i]
})
}
await page.waitFor(10000);
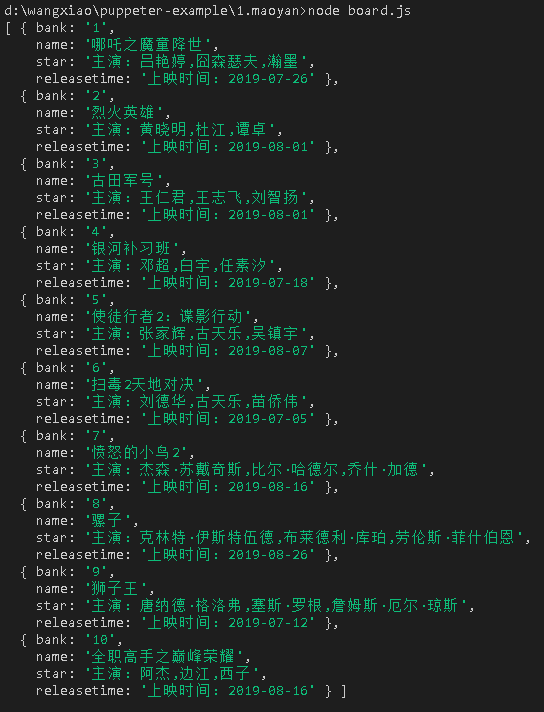
console.log(data);
await browser.close();
}
maoyan_board_run();
github:https://github.com/wangxiao9/puppeteer_spider
【爬虫】基于PUPPETEER页面爬虫的更多相关文章
- python爬虫之路——初识爬虫原理
爬虫主要做两件事 ①模拟计算机对服务器发起Request请求 ②接收服务器端的Response内容并解析,提取所需的信息 互联网页面错综复杂,一次请求不能获取全部信息.就需要设计爬虫的流程. 本书主要 ...
- 基于puppeteer模拟登录抓取页面
关于热图 在网站分析行业中,网站热图能够很好的反应用户在网站的操作行为,具体分析用户的喜好,对网站进行针对性的优化,一个热图的例子(来源于ptengine) 上图中能很清晰的看到用户关注点在那,我们不 ...
- 【java爬虫】---爬虫+基于接口的网络爬虫
爬虫+基于接口的网络爬虫 上一篇讲了[java爬虫]---爬虫+jsoup轻松爬博客,该方式有个很大的局限性,就是你通过jsoup爬虫只适合爬静态网页,所以只能爬当前页面的所有新闻.如果需要爬一个网站 ...
- web前端自动化测试/爬虫利器puppeteer介绍
web前端自动化测试/爬虫利器puppeteer介绍 Intro Chrome59(linux.macos). Chrome60(windows)之后,Chrome自带headless(无界面)模式很 ...
- 爬虫利器 Puppeteer
http://wintersmilesb101.online/2017/03/24/use-phantomjs-dynamic/ 一起学爬虫 Node.js 爬虫篇(三)使用 PhantomJS ...
- 爬虫抓取页面数据原理(php爬虫框架有很多 )
爬虫抓取页面数据原理(php爬虫框架有很多 ) 一.总结 1.php爬虫框架有很多,包括很多傻瓜式的软件 2.照以前写过java爬虫的例子来看,真的非常简单,就是一个获取网页数据的类或者方法(这里的话 ...
- 【图文详解】scrapy爬虫与动态页面——爬取拉勾网职位信息(2)
上次挖了一个坑,今天终于填上了,还记得之前我们做的拉勾爬虫吗?那时我们实现了一页的爬取,今天让我们再接再厉,实现多页爬取,顺便实现职位和公司的关键词搜索功能. 之前的内容就不再介绍了,不熟悉的请一定要 ...
- Python 自用代码(scrapy多级页面(三级页面)爬虫)
2017-03-28 入职接到的第一个小任务,scrapy多级页面爬虫,从来没写过爬虫,也没学过scrapy,甚至连xpath都没用过,最后用了将近一周才搞定.肯定有很多low爆的地方,希望大家可以给 ...
- Python日记:基于Scrapy的爬虫实现
安装 pywin32 和python版本一致 地址 https://sourceforge.net/projects/pywin32/files/pywin32/Build%20221/安装过程中提示 ...
随机推荐
- Spring Cloud Alibaba Seata
一.简介 官网地址:http://seata.io/zh-cn/ 1,概念 Seata是一款开源的分布式事务解决方案,致力于在微服务架构在提供高性能和简单一样的分布式事务服务. 2,处理过程 Tran ...
- 利用ADB命令强制卸载oppo自带浏览器
前言 oppo手机是自带oppo浏览器的,这个自带的浏览器带有oppo推荐的负面新闻很多,而且有时也自动推送一些消息给用户,页面不够简洁,打开浏览器负面内容比较多,所以想要强制卸载oppo浏览器,然后 ...
- 使用AI技术获取图片文字与识别图像内容
获取图片文字 如何使用python获取图片文字呢? 关注公众号[轻松学编程]了解更多- 1.通过python的第三方库pytesseract获取 通过pip install pytesseract导入 ...
- DP斜率优化学习笔记
斜率优化 首先,可以进行斜率优化的DP方程式一般式为$dp[i]=\max_{j=1}^{i-1}/\min_{j=1}^{i-1}\{a(i)*x(j)+b(i)*y(j)\}$ 其中$a(j)$和 ...
- [Codeforces 553E]Kyoya and Train(期望DP+Floyd+分治FFT)
[Codeforces 553E]Kyoya and Train(期望DP+Floyd+分治FFT) 题面 给出一个\(n\)个点\(m\)条边的有向图(可能有环),走每条边需要支付一个价格\(c_i ...
- 系统解析Apache Hive
Apache Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供一种HQL语言进行查询,具有扩展性好.延展性好.高容错等特点,多应用于离线数仓建设. 1. ...
- CSS总结(一)
1 css常用的一些属性 color: 文字颜色(前景色) font-size: 文字大小 font-family: 字体,比如:微软雅黑, 黑体,宋体,仿宋体,"Times New Rom ...
- cmd,py脚本,py编译的exe,uipath及uibot对它们的调用
UIPATH调用Python编译程序exe 好处: 1)code不以可编辑的状态被用户接触,对于不懂反编译的一般用户,可提升一定的代码安全性: 2)不需要用户机器上安装 python环境. 3)可以将 ...
- 经典c程序100例==81--90
[程序81] 题目:809*??=800*??+9*??+1 其中??代表的两位数,8*??的结果为两位数,9*??的结果为3位数.求??代表的两位数,及809*??后的结果. 1.程序分析: 2.程 ...
- lua调用dll demo
使用的是lua5.3 DllMain.cpp 1 //生成的dll 是 lua_add53.dll 2 //luaopen_lua_add 3 extern "C" { 4 #in ...