十八般武艺玩转GaussDB(DWS)性能调优:路径干预
摘要:路径生成是表关联方式确定的主要阶段,本文介绍了几个影响路径生成的要素:cost_param, scan方式,join方式,stream方式,并从原理上分析如何干预路径的生成。
一、cost模型选择
顾名思义,cost_param是控制cost相关的一个参数。在了解cost_param之前,先回顾一下选择率的概念,GaussDB优化器中的选择率是指,当一个表有一个过滤或关联条件时,通过该条件能被选中的行数占总行数的比例,是介于0~1之间的一个实数。选择率在优化器中是一个重要的概念,主要应用于行数和distinct值的估算,行数和distinct值是计划生成中的基本要素。
首先,我们来看带有过滤条件的基表行数如何估算。如果一个表只有一个过滤条件,那么以选择率乘以表的行数,即可得到过滤完的行数;如果有多个过滤条件,那么就需要算出一个综合的选择率,如何计算?方式有二:一是通过多列统计信息直接计算,二是通过组合单列的选择率。那么组合的方式就由参数cost_param决定了,具体地,

举一个例子,TPC-H 1x的part表,过滤条件是:p_brand = 'Brand#45' and p_container = 'WRAP CASE',查看不同cost_param下的过滤后行数。
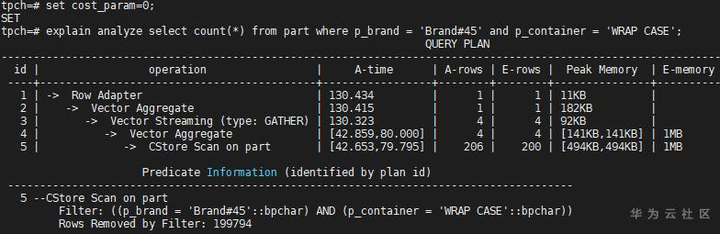
(1)cost_param=0
(2)cost_param=2
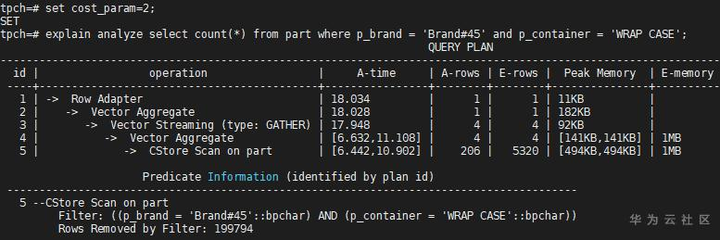
从估算出的行数(E-rows)和实际的行数(A-rows)对比可以看出,cost_param=0的不相关模型适合part表的p_brand和p_container列。
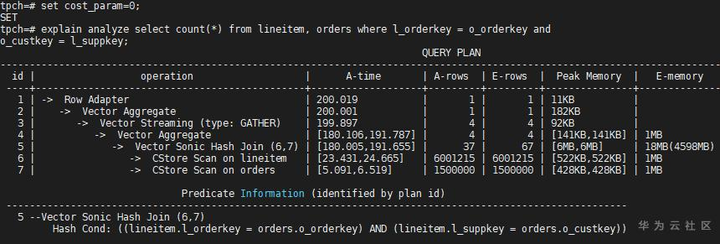
其次,Join的行数怎么估算的呢?原理跟过滤条件的行数估算是类似的,如果没有多列统计信息可以使用,则也需要单独计算每个条件的选择率,然后计算出综合选择率,得出行数。例如 TPC-H 1x lineitem和orders关联,关联条件是:l_orderkey = o_orderkey and o_custkey = l_suppkey,不同cost_param的执行情况如下:
(1)cost_param=0
(2)cost_param=2
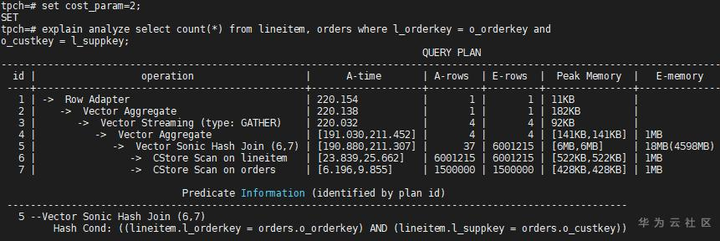
此例中,Join的列之间也适合完全相关模型,这与l_orderkey和l_suppkey的分布是吻合的。
由于TPC-H的模型接近完全不相关模型,因此cost_param=0模型可以较好的描述场景,实际应用中,用户可以根据具体业务场景来调整模型,行数估算的准确性是计划生成的重要保证,在调优中检查估算的最直接的地方。GaussDB会在后续版本中新增更多的模型供业务需求选择。
二、Scan方式的选择
GaussDB中扫描方式主要分顺序扫描和索引扫描,每种扫描方式都对应若干扫描算子,顺序扫描在行列存中对应的扫描算子分别是Seq Scan和CStore Scan算子(下面我们讨论中不加区分)。这些扫描算子大部分都可以通过开关来进行调控,例如Seq Scan,如果设置enable_seqscan=off,则表示不会优先选择Seq Scan,而不是一定不会选。扫描方式的选择,很大程度上决定了获取基表数据的路径。我们以如下的例子来说明:
select l_orderkey, o_custkey from lineitem, orders where l_orderkey = o_orderkey;
lineitem分布键是l_orderkey,并且在l_orderkey上有index,orders分布键是o_orderkey。默认情况下,Scan的方式如下:
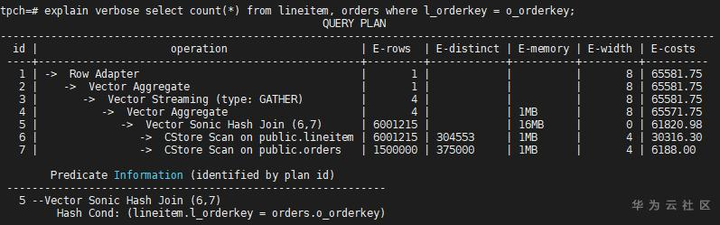
两个表都是顺序扫描的路径,关联方式选择了Hash Join。如果把Seq Scan关掉(enable_seqscan=off),计划如下:
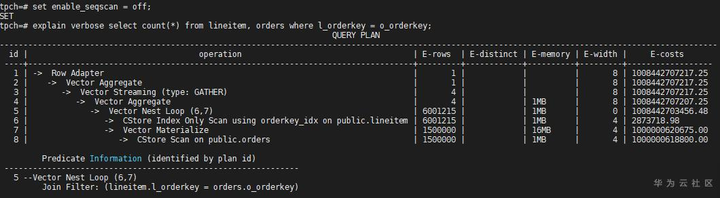
lineitem的扫描变成了Index Only Scan(因为l_orderkey的类型是int),而在orders表上仍然选择Seq Scan(因为没有其他路径),同时关联方式也变为了Nest Loop,因为Hash Join需要全表扫描数据(lineitem的Seq Scan已经被关掉了)。优化器的选择方式我们从代价(E-costs)一栏中也可以看出。再把Index Only Scan关掉,看看计划如何变化:
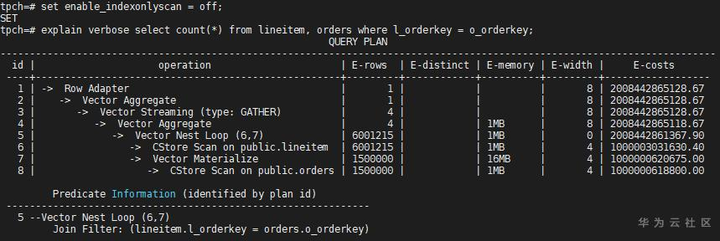
扫描路径都变为了Seq Scan,而且Seq Scan的代价都很大。此时既然都走了Seq Scan,为什么不选Hash Join呢,把Nest Loop关掉,看看Hash Join计划的代价:
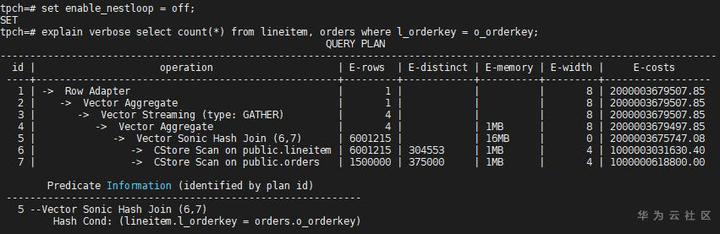
从代价上看出Hash Join的总代价比Nest Loop的小,但优化器没有选择Hash Join,这是因为优化器比较路径代价时,会比较Startup和Total代价,即启动代价和总代价,综合考虑,E-costs栏中显示的是总代价。把explain_perf_mode设置为normal,查看原Nest Loop的启动代价:
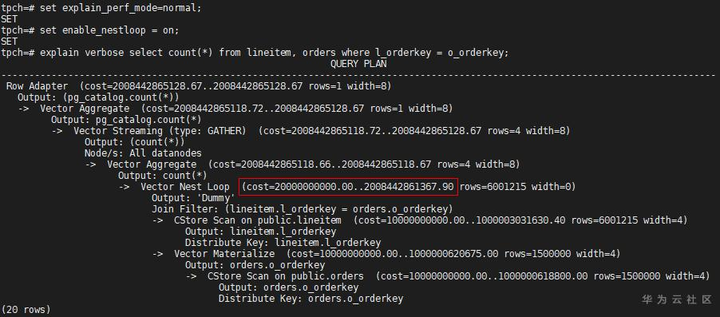
红框中的两个cost,分别是启动代价和总代价,在看Hash Join的cost,明显Hash Join的启动代价比Nest Loop的大很多(启动代价代表了输出第一条数据的代价),优化器在比较路径时,综合了这两个代价,最终推荐了Nest Loop的路径。
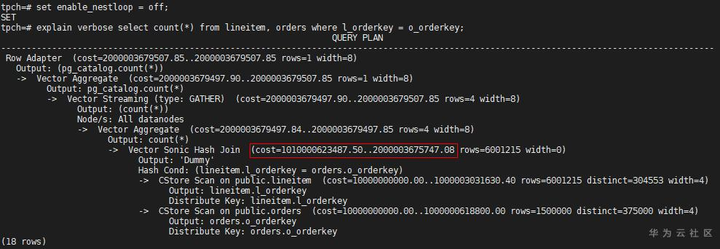
从上面的例子可以看出,扫描路径的调控,可以改变路径生成,合理的搭配是生成最优计划的前提,默认情况下,GaussDB优化器可以根据现有的路径选择(如上面的lineitem有两条扫描路径,orders只有一条扫描路径),最后确定出最优的一条。两条路径代价比较时,总代价不是唯一要素,但总代价越小,一般也会越容易被选中。
三、关联方式的选择
GaussDB优化器中表关联的主要方式有:Nest Loop,Hash Join和Merge Join,分别可以通过enable_nestloop、enable_hashjoin、enable_mergejoin进行控制,这种控制也不是绝对的,可以理解为是否优先选择。大部分场景下,三种路径的代价关系:Hash Join < Merge Join < Nest Loop。我们以一个简单的关联示例说明,store_returns和store_sales是TPC-DS 1x中两个表,SQL如下:
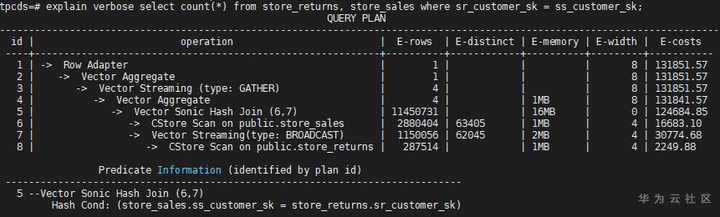
select count(*) from store_returns, store_sales where sr_customer_sk = ss_customer_sk;
默认情况下,优化器推荐Hash Join路径,计划如下:
如果把Hash Join关掉,则优化器选择了Merge Join路径:
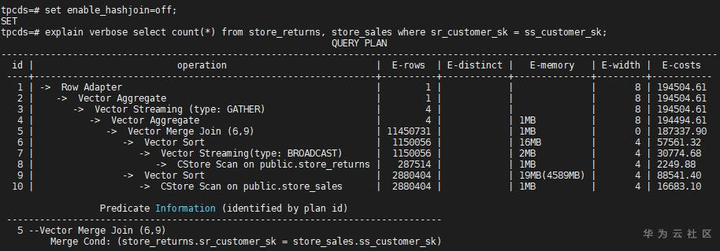
如果再把Merge Join路径关掉,可能就会选择Nest Loop路径。关联方式的控制开关一般用于调优或规避问题,但具体是否能够起作用要看具体的语句,除了当前关联方式,还有没有其他方式。实际场景中,一个语句中关联的算子较多,一般很难用参数enable_hashjoin或enable_nestloop或enable_mergejoin来控制某两个表的Join方式,GaussDB中更细致的语句级别的调优手段是Plan Hint,感兴趣的读者可以参考产品手册。
四、Stream方式的选择
Stream算子是GaussDB分布式执行的关键算子之一,主要起到网络传输的作用,概要介绍可以参考:GaussDB(DWS)性能调优系列实战篇一:十八般武艺之总体调优策略。Stream算子由参数enable_stream_operator控制,如果关掉Stream算子,则可能导致生成不下推的计划,例如:
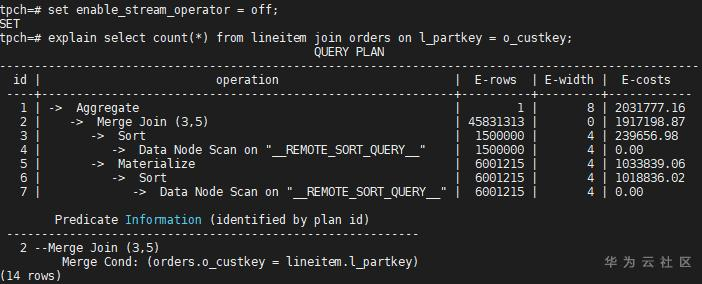
因为lineitem表关联的键l_partkey不是lineitem的分布键,需要添加Stream算子,但Stream功能被禁,于是只能生成不下推计划。
GaussDB计划中常见的主要Stream算子包括Redistribute、Broadcast和Gather。Gather一般是分布式计划中,CN用于收集DN的数据进行最后的处理,除非最后收集的行数非常多,这个算子涉及性能问题一般较少。Redistribute和Broadcast一是对“互补”的算子,前者用于重分布,后者用于广播,生成计划时,优化器会根据代价大小来选择。当Join Key没有包含表的分布键的时候,一般会添加Redistribute路径,能选择Redistribute路径理论上也可选择Broadcast路径,最终选择哪条路径要看优化器估算的代价是多少。这两个算子可以通过参数enable_redistribute和enable_broadcast进行控制。
在SMP开启的情况下,当并行度(dop)大于1时,一般还会有Local Redistribute、Split Redistribute、Local Broadcast和Split Broadcast;当倾斜优化开启时,还有PART REDISTRIBUTE PART ROUNDROBIN、PART_REDISTRIBUTE_PART_BROADCAST、PART_REDISTERIBUTE_PART_LOCAL等等,这些也是Stream算子,主要就是重分布、广播、RoundRobin的一些扩展形式,这里我们不一一介绍了,感兴趣的读者可以参考GaussDB DWS 产品手册。
我们考虑两个表的简单关联,store_sales和sr_tbl,它们的分布键分别是ss_item_sk 和sr_returned_date_sk,Join 条件是store_sales.ss_customer_sk =sr_tbl. sr_customer_sk,执行结果如下:
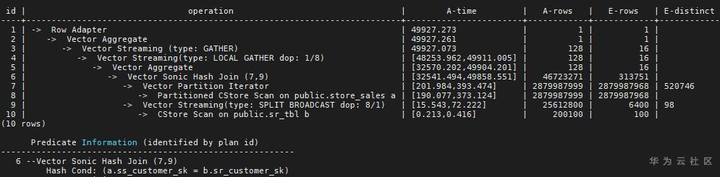
由于两个表的分布键都不是Join Key,因此走Hash Join路径的话需要有一个表做Broadcast或者两个表都做Redistribute,但是store_sales表比较大(E-rows显示28.7亿行),而sr_tbl表行数估算比较少(E-rows显示100行),优化器认为适合做Broadcast。于是最终选择了一边Broadcast的计划。
对于这个计划,由于sr_tbl表统计信息不准确(如果是中间结果集,则表示中间结果集估算不准),一种调优的方法是,将sr_tbl的表统计信息重新收集准确一些(如果sr_tbl是中间结果集,则无法收集),另一种方法是让sr_tbl走Redistribute路径,而后者我们又有两种方式来实现,一是用Plan Hint,即在生成计划时,告诉优化器走Redistribute路径,二是把Broadcast关掉。禁用Broadcast后,执行计划如下:
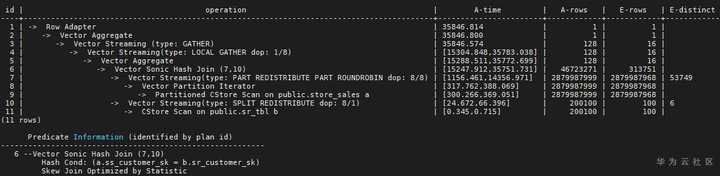
本列中,开启了SMP自适应,即优化器会根据系统资源和当前Active SQL数量来自行决定并行度(dop),如果Redistribute和Broadcast选择不当,则可能导致
(1)Broadcast计划会出现下盘
(2)两个计划的并行度不一样,最终执行时间可能会差异比较大。
对于Stream方式的控制,一般的调优方式有Plan Hint、GUC参数、改善统计信息或估算信息。
五、结束语
本文介绍的cost_param属于cost底层参数,建议对数据特征和使用场景比较熟悉的DBA慎重使用。Scan、Join、Stream调控的基本依据也是代价,代价一般体现在执行耗时上,调优时可从Performance中识别出性能的瓶颈点,分析选择的算子是否与代价匹配。另外,除了本文介绍的Session级别的控制参数外,还有基表、中间结果的行数,也可以通过Plan Hint进行语句级别的调控,感兴趣读者可通过GaussDB DWS产品文档进一步了解。
本文分享自华为云社区《GaussDB(DWS)性能调优系列实战篇五:十八般武艺之路径干预》,原文作者:- 大道至简 - 。
十八般武艺玩转GaussDB(DWS)性能调优:路径干预的更多相关文章
- 十八般武艺玩转GaussDB(DWS)性能调优:SQL改写
摘要:本文将系统介绍在GaussDB(DWS)系统中影响性能的坏味道SQL及SQL模式,帮助大家能够从原理层面尽快识别这些坏味道SQL,在调优过程中及时发现问题,进行整改. 数据库的应用中,充斥着坏味 ...
- 十八般武艺玩转GaussDB(DWS)性能调优(三):好味道表定义
摘要:表结构设计是数据库建模的一个关键环节,表定义好坏直接决定了集群的有效容量以及业务查询性能,本文从产品架构.功能实现以及业务特征的角度阐述在GaussDB(DWS)的中表定义时需要关注的一些关键因 ...
- 数据库性能调优之始: analyze统计信息
摘要:本文简单介绍一下什么是统计信息.统计信息记录了什么.为什么要收集统计信息.怎么收集统计信息以及什么时候收集统计信息. 1 WHY:为什么需要统计信息 1.1 query执行流程 下图描述了Gau ...
- JVM 性能调优实战之:一次系统性能瓶颈的寻找过程
玩过性能优化的朋友都清楚,性能优化的关键并不在于怎么进行优化,而在于怎么找到当前系统的性能瓶颈.性能优化分为好几个层次,比如系统层次.算法层次.代码层次…JVM 的性能优化被认为是底层优化,门槛较高, ...
- MySQL性能调优与架构设计——第 15 章 可扩展性设计之Cache与Search的利用
第 15 章 可扩展性设计之Cache与Search的利用 前言: 前面章节部分所分析的可扩展架构方案,基本上都是围绕在数据库自身来进行的,这样是否会使我们在寻求扩展性之路的思维受到“禁锢”,无法更为 ...
- sql server性能调优
转自:https://www.cnblogs.com/woodytu/tag/%E6%80%A7%E8%83%BD%E8%B0%83%E4%BC%98%E5%9F%B9%E8%AE%AD/defaul ...
- 大厂运维必备技能:PB级数据仓库性能调优
摘要:众所周知,数据量大了之后,性能是大家关注的一点,所以我们在业务开发的时候,特别关注性能,做为一个架构师,必须对性能要了解,要懂.才能设计出高性能的业务系统. 一.GaussDB分布式架构 所谓集 ...
- String 既然能做性能调优,我直呼内行
码哥,String 还能优化啥?你是不是框我? 莫慌,今天给大家见识一下不一样的 String,从根上拿捏直达 G 点. 并且码哥分享一个例子:通过性能调优我们能实现百兆内存轻松存储几十 G 数据. ...
- web前端性能调优
最近2个月一直在做手机端和电视端开发,开发的过程遇到过各种坑.弄到快元旦了,终于把上线了.2个月干下来满满的的辛苦,没有那么忙了自己准备把前端的性能调优总结以下,以方便以后自己再次使用到的时候得于得心 ...
随机推荐
- js 导出div 中的类容为 word 文件
//引入包 <script src="/FileSaver.js"></script> <script src="/jquery.word ...
- Angular:使用service进行数据的持久化设置
①使用ng g service services/storage创建一个服务组件 ②在app.module.ts 中引入创建的服务 ③利用本地存储实现数据持久化 ④在组件中使用
- CSS-backgroound和radial-giadient的常见用法
前言 这里主要介绍下css中background和radial-giadient径向渐变的使用,工作中用到的地方可能也不太多,但是每次用到了都需要查阅官网,查资料就比较麻烦,这里记录一下我自己整理的常 ...
- 超详细分析Bootloader到内核的启动流程(万字长文)
@ 目录 Bootloader启动流程分析 Bootloader第一阶段的功能 硬件设备初始化 为加载 Bootloader的第二阶段代码准备RAM空间(初始化内存空间) 复制 Bootloader的 ...
- 01-flask-helloWorld
代码 from flask import Flask # 创建Flask对象 app = Flask(__name__) # 定义路由 @app.route('/') def index(): # 函 ...
- js上 六、运算符-2
6.1.关系运算符 用来进行比较的.比较的结果通常是布尔值真和假. ü ==:相等,只比较值是否相等 ü ===:全等,比较值的同时比较数据类型是否相等 ü !=:不相等,比较值是否不相等 ü !== ...
- CSS练习 —— css选择器
CSS选择器就是 通过选择器来 定位 你要控制的样式的部分,分为以下几种 1.HTML选择符(标签选择器) 就是把HTML标签作为选择符使用 如 p {.......} 网页中所有的P标签采用此样式 ...
- CVE-2019-2618任意文件上传漏洞复现
CVE-2019-2618任意文件上传漏洞复现 漏洞介绍: 近期在内网扫描出不少CVE-2019-2618漏洞,需要复测,自己先搭个环境测试,复现下利用过程,该漏洞主要是利用了WebLogic组件中的 ...
- Application Data in Docker 笔记
Application Data in Docker By default all files created inside a container are stored on a writable ...
- DRF终极封装ViewSet和Router附教程PDF源码
在DRF官方教程的学习过程中,一个很明显的感受是框架在不断地进行封装,我们自己写框架/工具/脚本/平台也可以模仿模仿,先完成底层代码,再做多层封装,让使用者很容易就上手操作.本文是教程的最后一篇,介绍 ...