【Python3 爬虫】03_urllib.error异常处理
urllib.error可以接受来自urllib.request产生的异常。urllib.error有两个方法:①URLError ②HTTPError

URLError
URLError产生的原因
①网络无连接,即本机无法上网
②连接不到特定的服务器
③服务器不存在
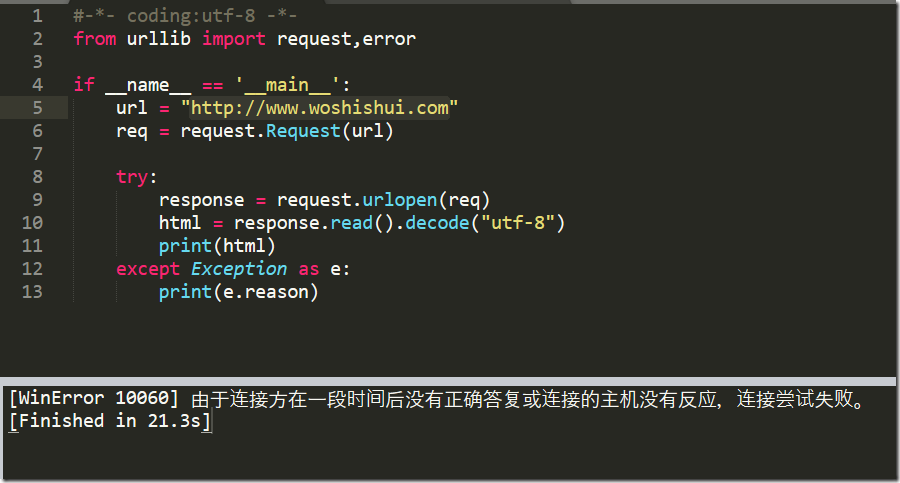
运行结果表明:连接超时
HTTPError
HTTPError是URLError的子类,在你利用URLopen方法发出一个请求时,服务器上都会对应一个应答对象response,其中他包含一个数字“状态码”,例如response是一个重定向,需定位到别的地址获取文档,urllib将对此进行处理。
其他不能处理的,URLopen会产生一个HTTPError,对应相应的状态码,HTTP状态码表示HTTP协议所返回的响应的状态。状态码归结如下:
100:继续 客户端应当继续发送请求。客户端应当继续发送请求的剩余部分,或者如果请求已经完成,忽略这个响应。
101: 转换协议 在发送完这个响应最后的空行后,服务器将会切换到在Upgrade 消息头中定义的那些协议。只有在切换新的协议更有好处的时候才应该采取类似措施。
102:继续处理 由WebDAV(RFC 2518)扩展的状态码,代表处理将被继续执行。
200:请求成功 处理方式:获得响应的内容,进行处理
201:请求完成,结果是创建了新资源。新创建资源的URI可在响应的实体中得到 处理方式:爬虫中不会遇到
202:请求被接受,但处理尚未完成 处理方式:阻塞等待
204:服务器端已经实现了请求,但是没有返回新的信 息。如果客户是用户代理,则无须为此更新自身的文档视图。 处理方式:丢弃
300:该状态码不被HTTP/1.0的应用程序直接使用, 只是作为3XX类型回应的默认解释。存在多个可用的被请求资源。 处理方式:若程序中能够处理,则进行进一步处理,如果程序中不能处理,则丢弃
301:请求到的资源都会分配一个永久的URL,这样就可以在将来通过该URL来访问此资源 处理方式:重定向到分配的URL
302:请求到的资源在一个不同的URL处临时保存 处理方式:重定向到临时的URL
304:请求的资源未更新 处理方式:丢弃
400:非法请求 处理方式:丢弃
401:未授权 处理方式:丢弃
403:禁止 处理方式:丢弃
404:没有找到 处理方式:丢弃
500:服务器内部错误 服务器遇到了一个未曾预料的状况,导致了它无法完成对请求的处理。一般来说,这个问题都会在服务器端的源代码出现错误时出现。
501:服务器无法识别 服务器不支持当前请求所需要的某个功能。当服务器无法识别请求的方法,并且无法支持其对任何资源的请求。
502:错误网关 作为网关或者代理工作的服务器尝试执行请求时,从上游服务器接收到无效的响应。
503:服务出错 由于临时的服务器维护或者过载,服务器当前无法处理请求。这个状况是临时的,并且将在一段时间以后恢复
HTTPError实例产生后会有一个code属性,这就是服务器发送的相关错误号。因为urllib可以为你处理重定向,也就是3开头的代号可以被处理,并且100-299范围的号码指示成功,所以你只能看到400-599的错误号码。
下面我们写一个例子来感受一下,捕获的异常是HTTPError,它会带有一个code属性,就是错误代号,另外我们又打印了reason属性,这是它的父类URLError的属性。
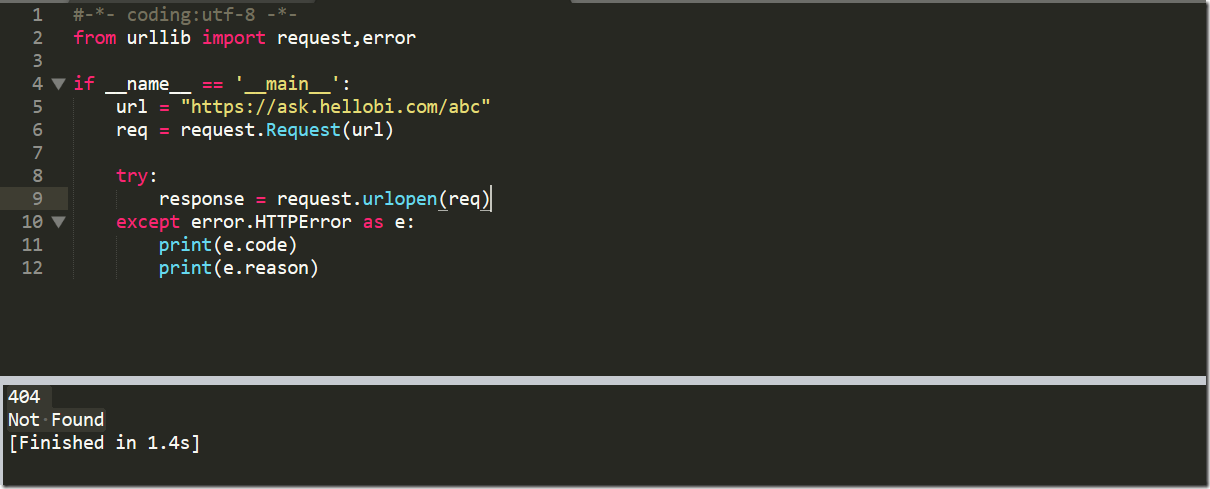
404
Not Found
结果分析:错误代码是404,错误原因是Not Found找不到网页
HTTPError与URLError一起使用
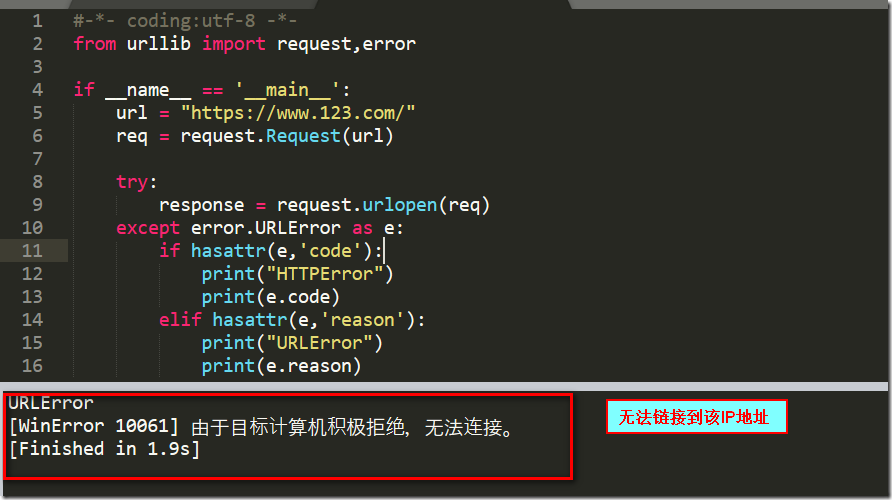
最后值得注意的一点是,如果想用HTTPError和URLError一起捕获异常,那么需要将HTTPError放在URLError的前面,因为HTTPError是URLError的一个子类。如果URLError放在前面,出现HTTP异常会先响应URLError,这样HTTPError就捕获不到错误信息了。
使用hasattr函数判断URLError含有的属性,如果含有reason属性表明是URLError,如果含有code属性表明是HTTPError
【Python3 爬虫】03_urllib.error异常处理的更多相关文章
- 第三百二十八节,web爬虫讲解2—urllib库爬虫—状态吗—异常处理—浏览器伪装技术、设置用户代理
第三百二十八节,web爬虫讲解2—urllib库爬虫—状态吗—异常处理—浏览器伪装技术.设置用户代理 如果爬虫没有异常处理,那么爬行中一旦出现错误,程序将崩溃停止工作,有异常处理即使出现错误也能继续执 ...
- Python3爬虫一之(urllib库)
urllib库是python3的内置HTTP请求库. ython2中urllib分为 urllib2.urllib两个库来发送请求,但是在python3中只有一个urllib库,方便了许多. urll ...
- Python3 爬虫之 Scrapy 核心功能实现(二)
博客地址:http://www.moonxy.com 基于 Python 3.6.2 的 Scrapy 爬虫框架使用,Scrapy 的搭建过程请参照本人的另一篇博客:Python3 爬虫之 Scrap ...
- python3爬虫系列19之反爬随机 User-Agent 和 ip代理池的使用
站长资讯平台:python3爬虫系列19之随机User-Agent 和ip代理池的使用我们前面几篇讲了爬虫增速多进程,进程池的用法之类的,爬虫速度加快呢,也会带来一些坏事. 1. 前言比如随着我们爬虫 ...
- Python3爬虫系列:理论+实验+爬取妹子图实战
Github: https://github.com/wangy8961/python3-concurrency-pics-02 ,欢迎star 爬虫系列: (1) 理论 Python3爬虫系列01 ...
- python3爬虫中文乱码之请求头‘Accept-Encoding’:br 的问题
当用python3做爬虫的时候,一些网站为了防爬虫会设置一些检查机制,这时我们就需要添加请求头,伪装成浏览器正常访问. header的内容在浏览器的开发者工具中便可看到,将这些信息添加到我们的爬虫代码 ...
- Python3 爬虫之 Scrapy 框架安装配置(一)
博客地址:http://www.moonxy.com 基于 Python 3.6.2 的 Scrapy 爬虫框架使用,Scrapy 的爬虫实现过程请参照本人的另一篇博客:Python3 爬虫之 Scr ...
- python3爬虫--反爬虫应对机制
python3爬虫--反爬虫应对机制 内容来源于: Python3网络爬虫开发实战: 网络爬虫教程(python2): 前言: 反爬虫更多是一种攻防战,针对网站的反爬虫处理来采取对应的应对机制,一般需 ...
- python3爬虫(4)各种网站视频下载方法
python3爬虫(4)各种网站视频下载方法原创H-KING 最后发布于2019-01-09 11:06:23 阅读数 13608 收藏展开理论上来讲只要是网上(浏览器)能看到图片,音频,视频,都能够 ...
随机推荐
- Qt笔记——绘图(QBitmap,QPixmap,QImage,QPicture)
QPainter绘图 重写绘图事件,虚函数 如果窗口绘图,必须放在绘图事件里实现 绘图事件内部自动调用,窗口需要重绘的时候,状态改变 绘图设备(QPixmap,QImage,QBitmap,QPict ...
- <Linux性能调优指南>主要思路流程
网上IBM很早放出的一本免费电子书, 十来年了,参考意义还是很大. 国内有翻译成中文在线阅读的版本. 见如下两个URL Linux Performance and Tuning Guidelines ...
- 25,Spark Sort-Based Shuffle内幕彻底解密
一:为什么需要Sort-Based Shuffle? 1, Shuffle一般包含两个阶段任务: 第一部分:产生Shuffle数据的阶段(Map阶段,额外补充,需要实现ShuffleManager中 ...
- BZOJ 3223: Tyvj 1729 文艺平衡树-Splay树(区间翻转)模板题
3223: Tyvj 1729 文艺平衡树 Time Limit: 10 Sec Memory Limit: 128 MBSubmit: 6881 Solved: 4213[Submit][Sta ...
- CodeForces 669B
链接:http://codeforces.com/problemset/problem/669/B 本文链接:http://www.cnblogs.com/Ash-ly/p/5443086.html ...
- python 输入 与如何查看文档 小结
Python 2 中的输入小结 转载请声明本文的引用出处:仰望大牛的小清新 1.raw_input(prompt = None)与input(prompt = None) 两个都是默认参数类型,这个参 ...
- NGUI_Sprites
一.UI Sprites 控件: Sprites控件是NGUI的基础控件,几乎可以这么说所有的控件都可以基于Sprites控件添加 Box Collider然后进行附加相关的脚本组件来达到想要的插件效 ...
- 1.4(Spring学习笔记)Spring-JDBC基础
一.Spring JDBC相关类 1.1 DriverManagerDataSource DriverManagerDataSource主要包含数据库连接地址,用户名,密码. 属性及含义如下配置所示: ...
- (转)[Unity3D]计时器/Timer
http://blog.sina.com.cn/s/blog_5b6cb9500101aejs.html 项目中管理计时器太混乱难看了,用好听点的话来说就是代码不优雅. 想了下就随手简单写了个时间 ...
- Android之startActivityForResult
作用:当aAty跳转之bAty时,需要bAty回传数据,使用startActivityForResult. 相关的函数: aAty:--跳转至bAty(intent可以传递数据) void andro ...