Python爬虫爬取百度翻译之数据提取方法json
工具:Python 3.6.5、PyCharm开发工具、Windows 10 操作系统
说明:本例为实现输入中文翻译为英文的小程序,适合Python爬虫的初学者一起学习,感兴趣的可以做英文翻译为中文的功能,如单词查询功能等。推荐使用谷歌浏览器或火狐浏览器检查元素。使用之前需要先安装模块:pip install request pip install json。
数据提取方法:json
1、数据交换格式,看起来像Python类型(列表,字典)的字符串
2、使用json之前需要导入
3、json.loads
(1)、把json字符串转化为Python类型
(2)、json.loads(json字符串)
4、json.dumps
(1)、把Python类型转化为json字符串
(2)、json.dumps({})
(3)、json.dumps(ret1,ensure_ascii=False,indent=2)
ensure_ascii让中文显示成中文
indent:能够让下一行在上一行的基础上空格
代码:
import requests
import json
url = "https://fanyi.baidu.com/basetrans" query_str = input("请输入要翻译的中文:") data = {
"query":query_str,
"from":"zh",
"to":"en"} headers = {
"User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1", "Referer": "https://fanyi.baidu.com/?aldtype=16047&tpltype=sigma"
} response = requests.post(url,data=data,headers=headers) html_str = response.content.decode()#json字符串 #json数据交换格式,使用json之前需要导入
#把json字符串转化为Python类型
dict_ret = json.loads(html_str)
#print(dict_ret)
#print(type(dict_ret))
ret = dict_ret["trans"][0]["dst"]
print("翻译结果是:",ret)
运行效果:
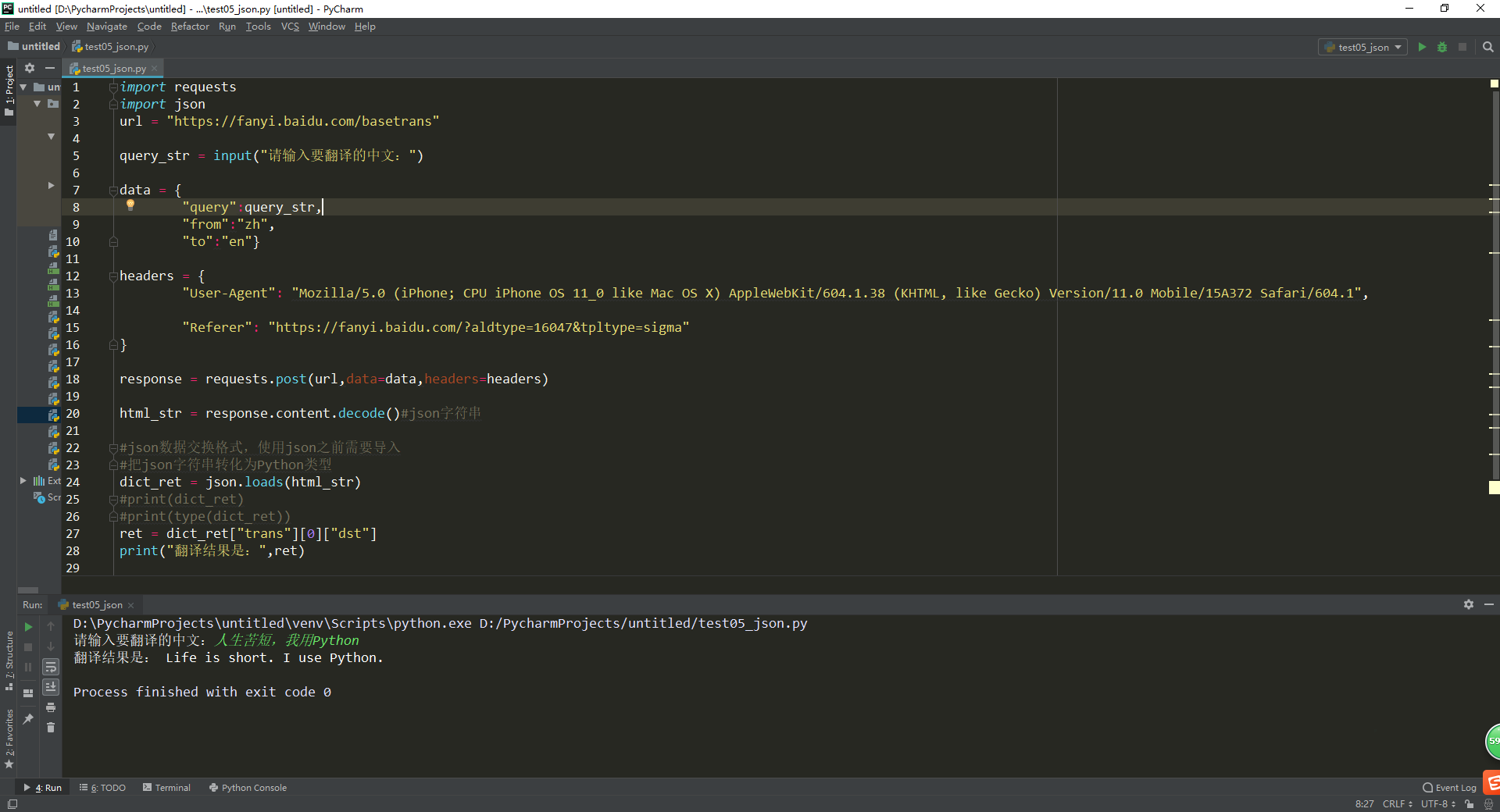
Python爬虫爬取百度翻译之数据提取方法json的更多相关文章
- python --爬虫--爬取百度翻译
import requestsimport json class baidufanyi: def __init__(self, trans_str): self.lang_detect_url = ' ...
- python爬虫-爬取百度图片
python爬虫-爬取百度图片(转) #!/usr/bin/python# coding=utf-8# 作者 :Y0010026# 创建时间 :2018/12/16 16:16# 文件 :spider ...
- Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理 源代码如下: # 改进版, 增加了 .strip()方法的使用 # coding=utf-8 ...
- 写一个python 爬虫爬取百度电影并存入mysql中
目标是利用python爬取百度搜索的电影 在类型 地区 年代各个标签下 电影的名字 评分 和图片连接 以及 电影连接 首先我们先在mysql中建表 create table liubo4( id in ...
- python爬虫—爬取百度百科数据
爬虫框架:开发平台 centos6.7 根据慕课网爬虫教程编写代码 片区百度百科url,标题,内容 分为4个模块:html_downloader.py 下载器 html_outputer.py 爬取数 ...
- Python爬虫爬取百度贴吧的帖子
同样是参考网上教程,编写爬取贴吧帖子的内容,同时把爬取的帖子保存到本地文档: #!/usr/bin/python#_*_coding:utf-8_*_import urllibimport urlli ...
- Python爬虫爬取百度贴吧的图片
根据输入的贴吧地址,爬取想要该贴吧的图片,保存到本地文件夹,仅供参考: #!/usr/bin/python#_*_coding:utf-8_*_import urllibimport urllib2i ...
- Python爬虫爬取豆瓣电影之数据提取值xpath和lxml模块
工具:Python 3.6.5.PyCharm开发工具.Windows 10 操作系统.谷歌浏览器 目的:爬取豆瓣电影排行榜中电影的title.链接地址.图片.评价人数.评分等 网址:https:// ...
- Python爬虫-爬取百度贴吧帖子
这次主要学习了替换各种标签,规范格式的方法.依然参考博主崔庆才的博客. 1.获取url 某一帖子:https://tieba.baidu.com/p/3138733512?see_lz=1&p ...
随机推荐
- python编写的简单的mysql巡检脚本
准备工作:1 安装python 3.5,本次使用源码安装.2 安装psutil模块,使用python3.5自带的easy_install包直接运行cd /opt/python3/bin./ ...
- 第3次Scrum冲刺
*:first-child { margin-top: 0 !important; } body>*:last-child { margin-bottom: 0 !important; } /* ...
- POJ-3104 Drying---二分答案判断是否可行
题目链接: https://cn.vjudge.net/problem/POJ-3104 题目大意: 有一些衣服,每件衣服有一定水量,有一个烘干机,每次可以烘一件衣服,每分钟可以烘掉k滴水.每件衣服每 ...
- Android——Intent,Bundle
Intent——切换activity intent.setClass(first.this,second.class); startActivity(intent); Bundle——切换时数据传递 ...
- CF498D Traffic Jams in the Land
嘟嘟嘟 题面:有n条公路一次连接着n + 1个城市,每一条公路有一个堵塞时刻a[i],如果当前时间能被a[i]整除,那么通过这条公路需要2分钟:否则需要1分钟. 现给出n条公路的a[i],以及m次操作 ...
- [18/11/20]break与continue的区别
一.普通break 和continue 1.break: break用于强行退出循环,不执行循环中剩余的语句. 2.continue continue 语句用在循环语句体中,用于终止某次循环过程,即跳 ...
- Idea 配置 Database 组件的MySql数据库连接
1.选择MySql
- servlet 与 tomcat版本不匹配的问题
严重: Failed to process JAR found at URL [/StudentLeave] for ServletContainerInitializers for context ...
- mybais学习记录一——入门程序
一.传统连接数据库和执行sql的不足 1.数据库连接,使用时就创建,不使用立即释放,对数据库进行频繁连接开启和关闭,造成数据库资源浪费,影响 数据库性能. 设想:使用数据库连接池管理数据库连接. 2. ...
- Java中基本类型和引用类型(简单介绍)
8种基本类型 一.4种整型 byte 1字节 -128——127 short 2 字节 -32,768 —— 32,767 in ...