mysql sql执行计划
查看Mysql执行计划
使用navicat查看mysql执行计划:
打开profile分析工具:

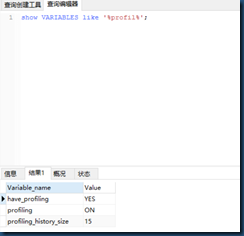
查看是否生效:show variable like ‘%profil%’;
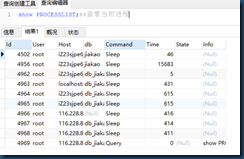
查看进程:show processlist;
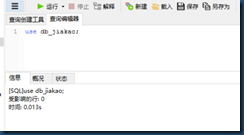
选择数据库:use db_jiakao;
全部分析的类型:show PROFILE all;
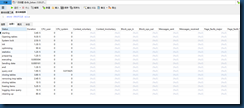
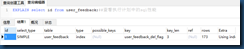
查看表索引:show index from user_member;##查看表索引

使用explain命令查看query语句的性能:
EXPLAIN select * from user_feedback;##查看执行计划中的sql性能
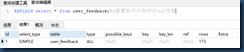
第一个查询是全表扫描,第二个是索引扫描:
区别在于type:all是全表扫描 index 通过索引扫描
select_type:是否是复杂语句
下面是MySQL文档关于ref连接类型的说明:
“对于每一种与另一个表中记录的组合,MySQL将从当前的表读取所有带有匹配索引值的记录。如果连接操作只使用键的最左前缀,或者如果键不是 UNIQUE或PRIMARY KEY类型(换句话说,如果连接操作不能根据键值选择出唯一行),则MySQL使用ref连接类型。如果连接操作所用的键只匹配少量的记录,则ref是一 种好的连接类型。”
在本例中,由于索引不是UNIQUE类型,ref是我们能够得到的最好连接类型。
如果EXPLAIN显示连接类型是“ALL”,而且你并不想从表里面选择出大多数记录,那么MySQL的操作效率将非常低,因为它要扫描整个表。你可以加入更多的索引来解决这个问题。预知更多信息,请参见MySQL的手册说明。
possible_keys:
可能可以利用的索引的名字。这里的索引名字是创建索引时指定的索引昵称;如果索引没有昵称,则默认显示的是索引中第一个列的名字。默认索引名字的含义往往不是很明显。
Key:
它显示了MySQL实际使用的索引的名字。如果它为空(或NULL),则MySQL不使用索引。
key_len:
索引中被使用部分的长度,以字节计。
ref:
它显示的是列的名字(或单词“const”),MySQL将根据这些列来选择行。在本例中,MySQL根据三个常量选择行。
rows:
MySQL所认为的它在找到正确的结果之前必须扫描的记录数。显然,这里最理想的数字就是1。
Extra:
这里可能出现许多不同的选项,其中大多数将对查询产生负面影响。在本例中,MySQL只是提醒我们它将用WHERE子句限制搜索结果集
◆ ID:Query Optimizer 所选定的执行计划中查询的序列号;
◆ Select_type:所使用的查询类型,主要有以下这几种查询类型
◇ DEPENDENT SUBQUERY:子查询中内层的第一个SELECT,依赖于外部查询的结果集;
◇ DEPENDENT UNION:子查询中的UNION,且为UNION 中从第二个SELECT 开始的后面所有
SELECT,同样依赖于外部查询的结果集;
◇ PRIMARY:子查询中的最外层查询,注意并不是主键查询;
◇ SIMPLE:除子查询或者UNION 之外的其他查询;
◇ SUBQUERY:子查询内层查询的第一个SELECT,结果不依赖于外部查询结果集;
◇ UNCACHEABLE SUBQUERY:结果集无法缓存的子查询;
◇ UNION:UNION 语句中第二个SELECT 开始的后面所有SELECT,第一个SELECT 为PRIMARY
◇ UNION RESULT:UNION 中的合并结果;
◆ Table:显示这一步所访问的数据库中的表的名称;
◆ Type:告诉我们对表所使用的访问方式,主要包含如下集中类型;
◇ all:全表扫描
◇ const:读常量,且最多只会有一条记录匹配,由于是常量,所以实际上只需要读一次;
◇ eq_ref:最多只会有一条匹配结果,一般是通过主键或者唯一键索引来访问;
◇ fulltext:
◇ index:全索引扫描;
◇ index_merge:查询中同时使用两个(或更多)索引,然后对索引结果进行merge 之后再读
取表数据;
◇ index_subquery:子查询中的返回结果字段组合是一个索引(或索引组合),但不是一个
主键或者唯一索引;
◇ rang:索引范围扫描;
◇ ref:Join 语句中被驱动表索引引用查询;
◇ ref_or_null:与ref 的唯一区别就是在使用索引引用查询之外再增加一个空值的查询;
◇ system:系统表,表中只有一行数据;
◇ unique_subquery:子查询中的返回结果字段组合是主键或者唯一约束;
◇
◆ Possible_keys:该查询可以利用的索引. 如果没有任何索引可以使用,就会显示成null,这一
项内容对于优化时候索引的调整非常重要;
◆ Key:MySQL Query Optimizer 从possible_keys 中所选择使用的索引;
◆ Key_len:被选中使用索引的索引键长度;
◆ Ref:列出是通过常量(const),还是某个表的某个字段(如果是join)来过滤(通过key)
的;
◆ Rows:MySQL Query Optimizer 通过系统收集到的统计信息估算出来的结果集记录条数;
◆ Extra:查询中每一步实现的额外细节信息,主要可能会是以下内容:
◇ Distinct:查找distinct 值,所以当mysql 找到了第一条匹配的结果后,将停止该值的查
询而转为后面其他值的查询;
◇ Full scan on NULL key:子查询中的一种优化方式,主要在遇到无法通过索引访问null
值的使用使用;
◇ Impossible WHERE noticed after reading const tables:MySQL Query Optimizer 通过
收集到的统计信息判断出不可能存在结果;
◇ No tables:Query 语句中使用FROM DUAL 或者不包含任何FROM 子句;
◇ Not exists:在某些左连接中MySQL Query Optimizer 所通过改变原有Query 的组成而
使用的优化方法,可以部分减少数据访问次数;
◇ Range checked for each record (index map: N):通过MySQL 官方手册的描述,当
MySQL Query Optimizer 没有发现好的可以使用的索引的时候,如果发现如果来自前面的
表的列值已知,可能部分索引可以使用。对前面的表的每个行组合,MySQL 检查是否可以使
用range 或index_merge 访问方法来索取行。
◇ Select tables optimized away:当我们使用某些聚合函数来访问存在索引的某个字段的
时候,MySQL Query Optimizer 会通过索引而直接一次定位到所需的数据行完成整个查
询。当然,前提是在Query 中不能有GROUP BY 操作。如使用MIN()或者MAX()的时
候;
◇ Using filesort:当我们的Query 中包含ORDER BY 操作,而且无法利用索引完成排序操
作的时候,MySQL Query Optimizer 不得不选择相应的排序算法来实现。
◇ Using index:所需要的数据只需要在Index 即可全部获得而不需要再到表中取数据;
◇ Using index for group-by:数据访问和Using index 一样,所需数据只需要读取索引即
可,而当Query 中使用了GROUP BY 或者DISTINCT 子句的时候,如果分组字段也在索引
中,Extra 中的信息就会是Using index for group-by;
◇ Using temporary:当MySQL 在某些操作中必须使用临时表的时候,在Extra 信息中就会
出现Using temporary 。主要常见于GROUP BY 和ORDER BY 等操作中。
◇ Using where:如果我们不是读取表的所有数据,或者不是仅仅通过索引就可以获取所有需
要的数据,则会出现Using where 信息;
◇ Using where with pushed condition:这是一个仅仅在NDBCluster 存储引擎中才会出现
的信息,而且还需要通过打开Condition Pushdown 优化功能才可能会被使用。控制参数
为engine_condition_pushdown 。
mysql sql执行计划的更多相关文章
- SQL优化 MySQL版 -分析explain SQL执行计划与笛卡尔积
SQL优化 MySQL版 -分析explain SQL执行计划 作者 Stanley 罗昊 [转载请注明出处和署名,谢谢!] 首先我们先创建一个数据库,数据库中分别写三张表来存储数据; course: ...
- Mysql查看执行计划-explain
最近生产环境有一些查询较慢,需要优化,于是先进行业务确认查询条件是否可以优化,不行再进行sql优化,于是学习了下Mysql查看执行计划. 语法 explain <sql语句> 例如: e ...
- Atitit sql执行计划
Atitit sql执行计划 1.1. 首先要搞明白什么叫执行计划? 执行计划是数据库根据SQL语句和相关表的统计信息作出的一个查询方案,这个方案是由查询优化器自动分析产生的 Oracle中的执行计划 ...
- Mysql查看执行计划
EXPLAIN(小写explain)显示了mysql如何使用索引来处理select语句以及连接表.可以帮助选择更好的索引和写出更优化的查询语句. EXPLAIN + sql语句可以查看mysql的执行 ...
- MySQL数据库执行计划(简单版)
+++++++++++++++++++++++++++++++++++++++++++标题:MySQL数据库执行计划简单版时间:2019年2月25日内容:MySQL数据库执行计划简单版重点:MySQL ...
- 一个RDBMS左连接SQL执行计划解析
1.测试数据如下: SQL> select * from t1; a | b | c ---+----+--- 1 | 10 | 1 2 | 20 | 2 3 | 30 | 3 4 ...
- Mysql explain执行计划
EXPLAIN(小写explain)显示了mysql如何使用索引来处理select语句以及连接表.可以帮助选择更好的索引和写出更优化的查询语句. EXPLAIN + sql语句可以查看mysql的执行 ...
- MySQL性能分析, mysql explain执行计划详解
MySQL性能分析 MySQL性能分析及explain用法的知识是本文我们主要要介绍的内容,接下来就让我们通过一些实际的例子来介绍这一过程,希望能够对您有所帮助. 1.使用explain语句去查看分析 ...
- EXPLAIN 查看 SQL 执行计划
EXPLAIN 查看 SQL 执行计划.分析索引的效率: id:id 列数字越大越先执行: 如果说数字一样大,那么就从上往下依次执行,id列为null的就表是这是一个结果集,不需要使用它来进行查询. ...
随机推荐
- 用sed实现wc -w的功能
版权申明:本文为博主窗户(Colin Cai)原创,欢迎转帖.如要转贴,必须注明原文网址 http://www.cnblogs.com/Colin-Cai/p/7663831.html 作者:窗户 Q ...
- 高可用,完全分布式Hadoop集群HDFS和MapReduce安装配置指南
原文:http://my.oschina.net/wstone/blog/365010#OSC_h3_13 (WJW)高可用,完全分布式Hadoop集群HDFS和MapReduce安装配置指南 [X] ...
- nginx入门与实战
网站服务 想必我们大多数人都是通过访问网站而开始接触互联网的吧.我们平时访问的网站服务 就是 Web 网络服务,一般是指允许用户通过浏览器访问到互联网中各种资源的服务. Web 网络服务是一种被动访问 ...
- 如何给30台centos7服务器分别增加相同的用户
老大直接给了30台新鲜的生产服务器,要给每一台服务器增加一个用户,密码相同 难道我们要部署一个工具吗?这样对生产环境可能会产生影响,为了保证服务器的新鲜以及节约时间,研究了小半天,终于研究出一个不是很 ...
- 关于xampp中无法启动mysql,Attempting to start MySQL service...的解决办法!!
最近在学习服务器方面的知识,找到了这款功能强大的建站集成软件包——xampp.但是在开数据库服务器的时候,出现了这种情况.一直在Attemptng to start MySQL service... ...
- Spark中的Join类型
常规连接: 左半连接: 左半连接结果集:仅仅保留左边表中的行,这些行的joinkey出现在右边表中!!!(类似于leftTable.joinKey in (rightTable.joinKeys)). ...
- maven 配置文件settings.xml设置
打开这个配置文件 在相应标签下配置这些内容 //将中央仓库修改为阿里云的仓库 <mirrors> <mirror> <id>nexus-aliyun</id& ...
- 004_centos安装pip的几种方式及pip源
一. (1) yum -y install epel-release yum install python-pip pip install --upgrade pip (2) python脚本的一键安 ...
- linux命令之netstat
功能:打印网络连接.路由表.接口统计信息.伪装连接和多播成员 参数 -r 显示路由表 -i 显示接口表 -n 不解析名字 -p 显示程序名 PID/Program -l 显示监听的 socket -a ...
- 请根据英文单词的第一个字母判断星期几,如果第一个字母是一样的,则继续判断第二个字母。例如如果第一个字母是S,则继续判断第二个字母,如果第二个字母是a,则输出“星期六”
请根据英文单词的第一个字母判断星期几,如果第一个字母是一样的,则继续判断第二个字母.例如如果第一个字母是S,则继续判断第二个字母,如果第二个字母是a,则输出“星期六”.星期的英文单词如下表所示. 星期 ...