Spark 1.6.1分布式集群环境搭建
一、软件准备
scala-2.11.8.tgz
spark-1.6.1-bin-hadoop2.6.tgz
二、Scala 安装
1、master 机器
(1)下载 scala-2.11.8.tgz, 解压到 /opt 目录下,即: /opt/scala-2.11.8。
(2)修改 scala-2.11.8 目录所属用户和用户组。
|
1
|
sudo chown -R hadoop:hadoop scala-2.11.8 |
(3)修改环境变量文件 .bashrc , 添加以下内容。
|
1
2
3
|
# Scala Envexport SCALA_HOME=/opt/scala-2.11.8export PATH=$PATH:$SCALA_HOME/bin |
运行 source .bashrc 使环境变量生效。
(4) 验证 Scala 安装

2、Slave机器
slave01 和 slave02 参照 master 机器安装步骤进行安装。
三、Spark 安装
1、master 机器
(1) 下载 spark-1.6.1-bin-hadoop2.6.tgz,解压到 /opt 目录下。
(2) 修改 spark-1.6.1-bin-hadoop2.6 目录所属用户和用户组。
|
1
|
sudo chown -R hadoop:hadoop spark-1.6.1-bin-hadoop2.6 |
(3) 修改环境变量文件 .bashrc , 添加以下内容。
|
1
2
3
|
# Spark Envexport SPARK_HOME=/opt/spark-1.6.1-bin-hadoop2.6export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin |
运行 source .bashrc 使环境变量生效。
(4) Spark 配置
进入 Spark 安装目录下的 conf 目录, 拷贝 spark-env.sh.template 到 spark-env.sh。
|
1
|
cp spark-env.sh.template spark-env.sh |
编辑 spark-env.sh,在其中添加以下配置信息:
|
1
2
3
4
5
|
export SCALA_HOME=/opt/scala-2.11.8export JAVA_HOME=/opt/java/jdk1.7.0_80export SPARK_MASTER_IP=192.168.109.137export SPARK_WORKER_MEMORY=1gexport HADOOP_CONF_DIR=/opt/hadoop-2.6.4/etc/hadoop |
JAVA_HOME 指定 Java 安装目录;
SCALA_HOME 指定 Scala 安装目录;
SPARK_MASTER_IP 指定 Spark 集群 Master 节点的 IP 地址;
SPARK_WORKER_MEMORY 指定的是 Worker 节点能够分配给 Executors 的最大内存大小;
HADOOP_CONF_DIR 指定 Hadoop 集群配置文件目录。
将 slaves.template 拷贝到 slaves, 编辑其内容为:
|
1
2
3
|
masterslave01slave02 |
即 master 既是 Master 节点又是 Worker 节点。
2、slave机器
slave01 和 slave02 参照 master 机器安装步骤进行安装。
四、启动 Spark 集群
1、启动 Hadoop 集群
Hadoop 集群的启动可以参见之前的一篇文章 Hadoop 2.6.4分布式集群环境搭建,这里不再赘述。启动之后,可以分别在 master、slave01、slave02 上使用 jps 命令查看进程信息。



2、启动 Spark 集群
(1) 启动 Master 节点
运行 start-master.sh,结果如下:

可以看到 master 上多了一个新进程 Master。
(2) 启动所有 Worker 节点
运行 start-slaves.sh, 运行结果如下:

在 master、slave01 和 slave02 上使用 jps 命令,可以发现都启动了一个 Worker 进程


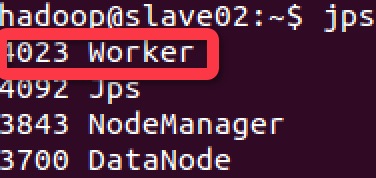
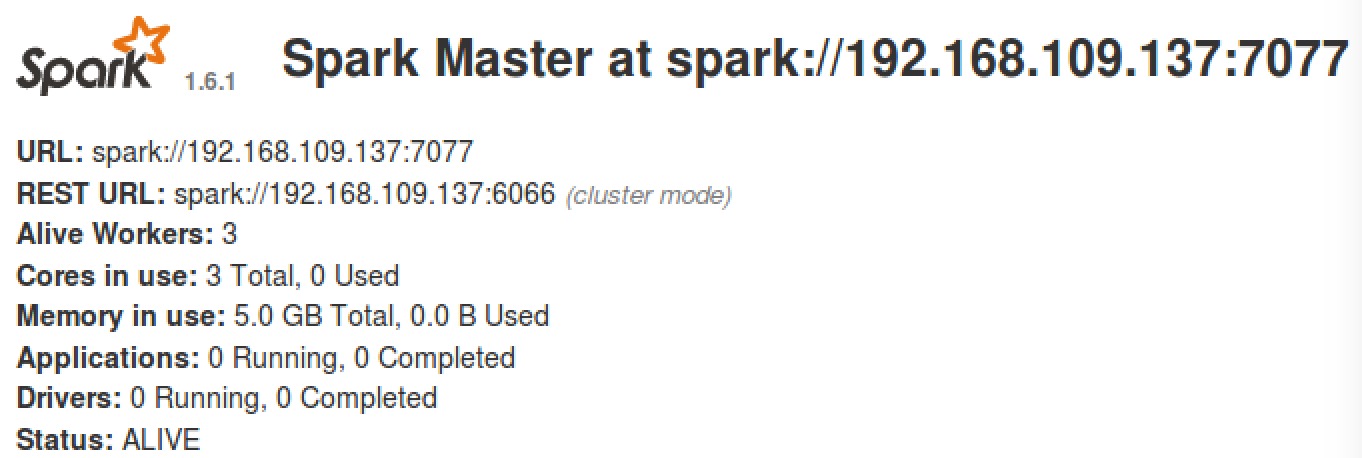
(3) 浏览器查看 Spark 集群信息。
访问:http://master:8080, 如下图:

(4) 使用 spark-shell
运行 spark-shell,可以进入 Spark 的 shell 控制台,如下:

(5) 浏览器访问 SparkUI
访问 http://master:4040, 如下图:

可以从 SparkUI 上查看一些 如环境变量、Job、Executor等信息。
至此,整个 Spark 分布式集群的搭建就到这里结束。
五、停止 Spark 集群
1、停止 Master 节点
运行 stop-master.sh 来停止 Master 节点。

使用 jps 命令查看当前 java 进程
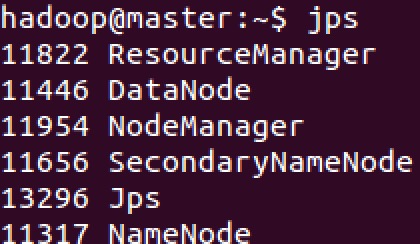
可以发现 Master 进程已经停止。
2、停止 Worker 节点
运行 stop-slaves.sh 可以停止所有的 Worker 节点

使用 jps 命令查看 master、slave01、slave02 上的进程信息:
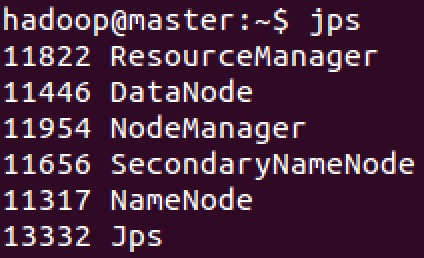
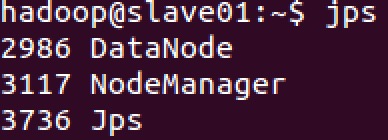
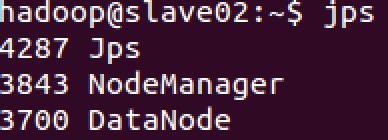
可以看到, Worker 进程均已停止,最后再停止 Hadoop 集群。
六、遗留问题
设置的 SCALA_HOME 没有生效,Spark 启动时用的是自带的 Scala 2.10.5 版本。
Spark 1.6.1分布式集群环境搭建的更多相关文章
- Spark 2.2.0 分布式集群环境搭建
集群机器: 1台 装了 ubuntu 14.04的 台式机 1台 装了ubuntu 16.04 的 笔记本 (机器更多时同样适用) 1.需要安装好Hadoop分布式环境 参照:Hadoop分类 ...
- ZooKeeper 完全分布式集群环境搭建
1. 搭建前准备 示例共三台主机,主机IP映射信息如下: 192.168.32.101 s1 192.168.32.102 s2 192.168.32.103 s3 2.下载ZooKeeper, 以 ...
- Hadoop完全分布式集群环境搭建
1. 在Apache官网下载Hadoop 下载地址:http://hadoop.apache.org/releases.html 选择对应版本的二进制文件进行下载 2.解压配置 以hadoop-2.6 ...
- Kafka 完全分布式集群环境搭建
思路: 先在主机s1上安装配置,然后远程复制到其它两台主机s2.s3上, 并分别修改配置文件server.properties中的broker.id属性. 1. 搭建前准备 示例共三台主机,主机IP映 ...
- Hadoop伪分布式集群环境搭建
本教程讲述在单机环境下搭建Hadoop伪分布式集群环境,帮助初学者方便学习Hadoop相关知识. 首先安装Hadoop之前需要准备安装环境. 安装Centos6.5(64位).(操作系统再次不做过多描 ...
- 阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建
准备: 两台配置CentOS 7.3的阿里云ECS服务器: hadoop-2.7.3.tar.gz安装包: jdk-8u77-linux-x64.tar.gz安装包: hostname及IP的配置: ...
- Hadoop学习(一):完全分布式集群环境搭建
1. 设置免密登录 (1) 新建普通用户hadoop:useradd hadoop(2) 在主节点master上生成密钥对,执行命令ssh-keygen -t rsa便会在home文件夹下生成 .ss ...
- Hadoop+HBase+ZooKeeper分布式集群环境搭建
一.环境说明 集群环境至少需要3个节点(也就是3台服务器设备):1个Master,2个Slave,节点之间局域网连接,可以相互ping通,下面举例说明,配置节点IP分配如下: Hostname IP ...
- zookeeper伪分布式集群环境搭建
step1.下载 下载地址:http://zookeeper.apache.org/releases.html 将下载的压缩包放到用户家目录下(其他目录也可以) step2.解压 $tar –zxvf ...
随机推荐
- php中curl的详细解说(转载)
本文转自:http://blog.csdn.net/yanhui_wei/article/details/21530811 这几天在帮一些同学处理问题的时候,突然发现这些同学是使用file_get_c ...
- C# 串口通信总结
在C#串口通信开发过程中有的产家只提供通信协议,这时候开发人员要自己根据协议来封装方法,有的产家比较人性化提供了封装好的通信协议方法供开发人员调用. 1.只提供通信协议(例如,今年早些时候开发的出钞机 ...
- 用setTimeout 代替 setInterval实时拉取数据
在开发中,我们常常碰到需要定时拉取网站数据,如: setInterval(function(){ $.ajax({ url: 'xx', success: function( response ){ ...
- yii的常用配置文件
<?php return array( 'basePath' => dirname(__FILE__).DIRECTORY_SEPARATOR.'..', //当前应用根目录路径 'nam ...
- Codeforces Round #353 (Div. 2) E. Trains and Statistic 线段树+dp
题目链接: http://www.codeforces.com/contest/675/problem/E 题意: 对于第i个站,它与i+1到a[i]的站有路相连,先在求所有站点i到站点j的最短距离之 ...
- openstack与VMware workStation的区别
免责声明: 本文中使用的部分图片来自于网络,如有侵权,请联系博主进行删除 最近一直在研究云计算,恰好有个同事问了我一个问题:你们研究的openstack到底是什么东西?跟VMware Work ...
- 01.Hibernate入门
前言:本文用一个简单的Hibernate应用程序例子来引领初学者入门,让初学者对Hibernate的使用有一个大致的认识.本文例子使用了MySQL数据库.Maven管理工具.Eclipse开发工具,创 ...
- C++实现CString和string的互相转换
CString->std::string 例子: CString strMfc=“test“; std::string strStl; strStl=strMfc.GetBuffer(0); u ...
- HackPorts – Mac OS X 渗透测试框架与工具
HackPorts是一个OS X 下的一个渗透框架. HackPorts是一个“超级工程”,充分利用现有的代码移植工作,安全专业人员现在可以使用数以百计的渗透工具在Mac系统中,而不需要虚拟机. 工具 ...
- android中PreferenceScreen类的用法
PreferenceScreen preference是偏好,首选的意思,PreferenceScreen个人翻译成 “偏好显示”,明白这个意思就好,就是说根据特点灵活的定义显示内容风格,一个屏幕可以 ...