Spark 2.2.0 分布式集群环境搭建
集群机器:
1台 装了 ubuntu 14.04的 台式机
1台 装了ubuntu 16.04 的 笔记本 (机器更多时同样适用)
1.需要安装好Hadoop分布式环境
参照:Hadoop分类 -->http://www.cnblogs.com/soyo/p/7868282.html
2.安装Spark2.2.0 到/usr/local2
sudo chmod -R 777 Spark( 此/usr/local2路径下的被解压的spark("spark"名字是自己改的) )
3.配置环境变量
vim ~/.bashrc
添加:
export SPARK_HOME=/usr/local2/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin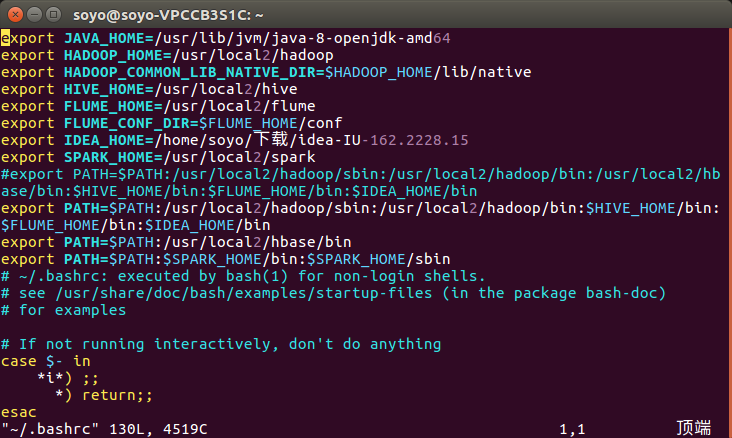
source ~/.bashrc
4.Spark分布式配置:
在Master节点主机上进行如下操作:
1.配置 slaves:slaves文件设置Worker节点
cd /usr/local2/spark/conf
cp ./slaves.template ./slaves
vim slaves
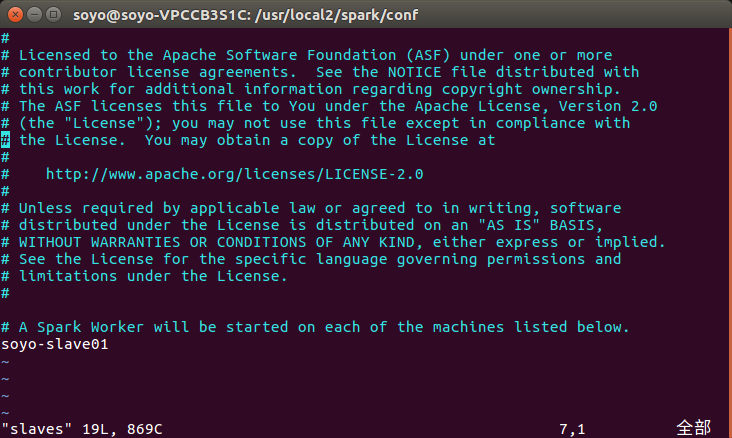
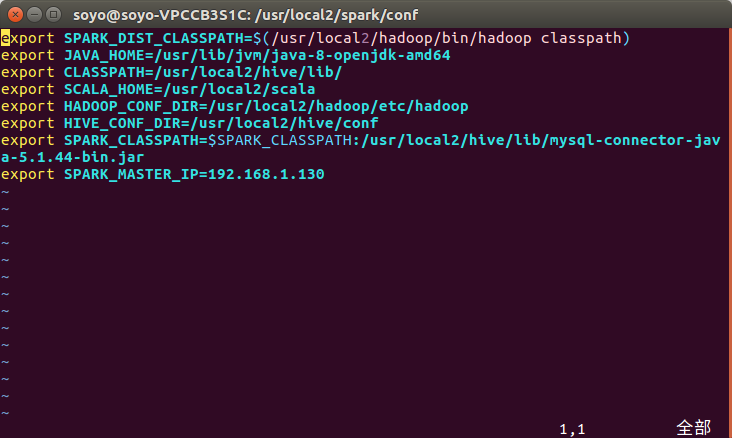
2.配置 spark-env.sh (刚开始这个文件也是没有的)( cp ./spark-env.sh.template ./spark-env.sh)
这里就加了 export SPARK_MASTER_IP=192.168.1.130 (别的是以前在非分布式情况下使用Spark需要时添加的)
SPARK_MASTER_IP 指定 Spark 集群 Master 节点的 IP 地址;
4.给节点分发Spark配置:
cd /usr/local2
tar -zcf ~/ spark.tar.gz ./spark
cd ~
scp ./spark.tar.gz soyo-slave01:/home/soyo
在soyo-slave01节点上分别执行下面同样的操作:
sudo tar -zxf spark.tar.gz -C /usr/local2
sudo chmod -R 777 spark
4.启动Spark集群:
4.1先启动分布式Hadoop:
在master节点执行:start-all.sh
4.2启动Spark:
启动Master节点:
在master节点执行:start-master.sh (在soyo-VPCCB3S1C节点执行jps:多了Master这个进程)

启动slave节点:
在master节点执行:start-slaves.sh (在soyo-slave01节点执行jps:多了Worker这个进程)

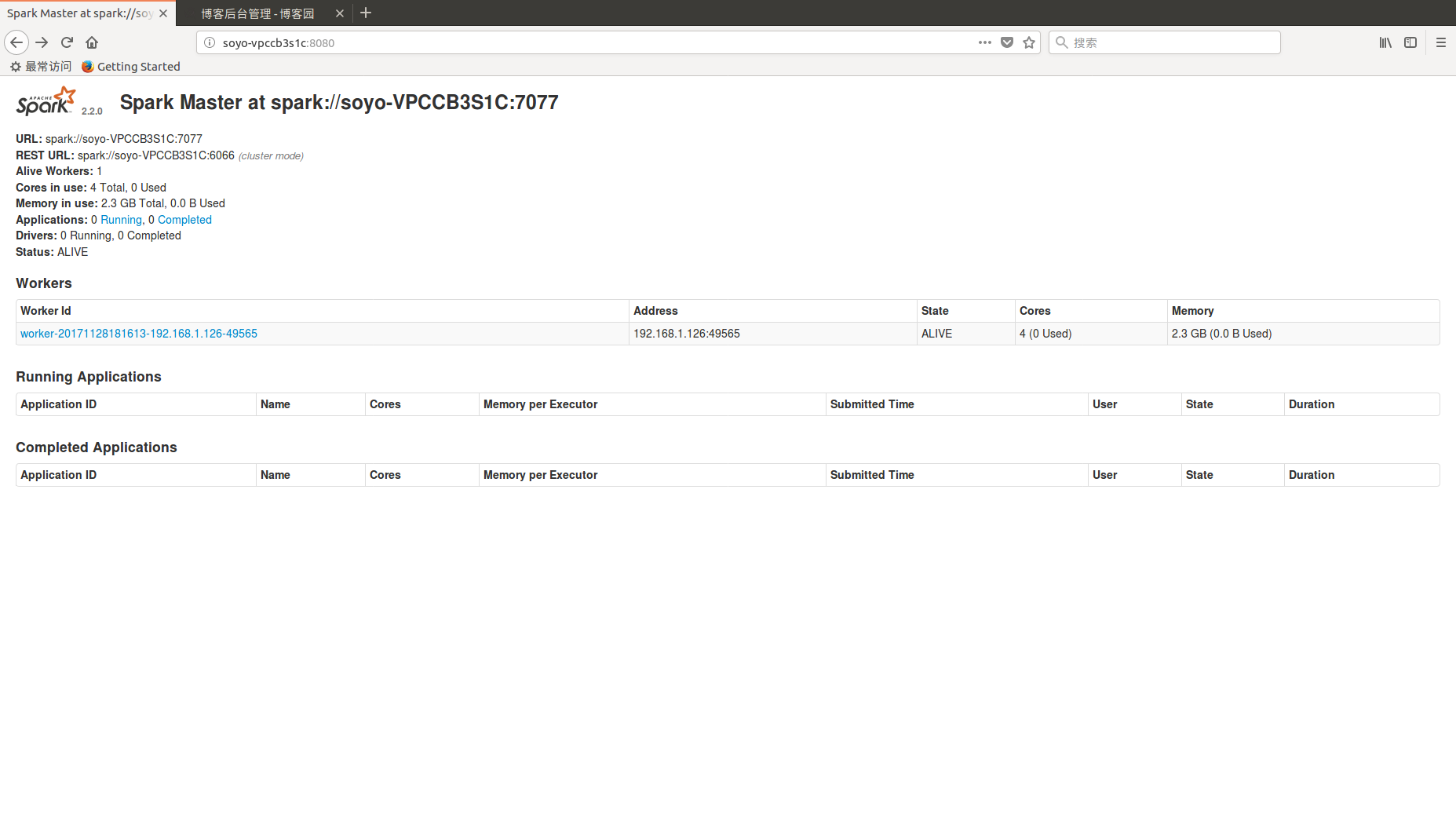
4.3在浏览器上查看Spark独立集群管理器的集群信息
http://soyo-vpccb3s1c:8080/
4.关闭Spark集群:

Spark 2.2.0 分布式集群环境搭建的更多相关文章
- Spark 1.6.1分布式集群环境搭建
一.软件准备 scala-2.11.8.tgz spark-1.6.1-bin-hadoop2.6.tgz 二.Scala 安装 1.master 机器 (1)下载 scala-2.11.8.tgz, ...
- Hadoop完全分布式集群环境搭建
1. 在Apache官网下载Hadoop 下载地址:http://hadoop.apache.org/releases.html 选择对应版本的二进制文件进行下载 2.解压配置 以hadoop-2.6 ...
- Kafka 完全分布式集群环境搭建
思路: 先在主机s1上安装配置,然后远程复制到其它两台主机s2.s3上, 并分别修改配置文件server.properties中的broker.id属性. 1. 搭建前准备 示例共三台主机,主机IP映 ...
- ZooKeeper 完全分布式集群环境搭建
1. 搭建前准备 示例共三台主机,主机IP映射信息如下: 192.168.32.101 s1 192.168.32.102 s2 192.168.32.103 s3 2.下载ZooKeeper, 以 ...
- Hadoop伪分布式集群环境搭建
本教程讲述在单机环境下搭建Hadoop伪分布式集群环境,帮助初学者方便学习Hadoop相关知识. 首先安装Hadoop之前需要准备安装环境. 安装Centos6.5(64位).(操作系统再次不做过多描 ...
- 阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建
准备: 两台配置CentOS 7.3的阿里云ECS服务器: hadoop-2.7.3.tar.gz安装包: jdk-8u77-linux-x64.tar.gz安装包: hostname及IP的配置: ...
- Hadoop学习(一):完全分布式集群环境搭建
1. 设置免密登录 (1) 新建普通用户hadoop:useradd hadoop(2) 在主节点master上生成密钥对,执行命令ssh-keygen -t rsa便会在home文件夹下生成 .ss ...
- Hadoop+HBase+ZooKeeper分布式集群环境搭建
一.环境说明 集群环境至少需要3个节点(也就是3台服务器设备):1个Master,2个Slave,节点之间局域网连接,可以相互ping通,下面举例说明,配置节点IP分配如下: Hostname IP ...
- IBM BigInsights 3.0.0.2 集群环境搭建
1. 改动hosts文件和永久主机名 由于BigInsights 3.0版本号不像之前的版本号能够直接用IP来添加节点,因此我们须要更改每台server的hosts文件和主机名: vim/etc/ho ...
随机推荐
- 第十八节:Scrapy爬虫框架之settings文件详解
# -*- coding: utf-8 -*- # Scrapy settings for maoyan project## For simplicity, this file contains on ...
- LeetCode(43)Multiply Strings
题目 Given two numbers represented as strings, return multiplication of the numbers as a string. Note: ...
- poj 2186 强连通分量
poj 2186 强连通分量 传送门 Popular Cows Time Limit: 2000MS Memory Limit: 65536K Total Submissions: 33414 Acc ...
- The Bells are Ringing(枚举)
Description Perhaps you all have heard the mythical story about Tower of Hanoi (The details of this ...
- Uva 816 Abbott的复仇(三元组BFS + 路径还原)
题意: 有一个最多9*9个点的迷宫, 给定起点坐标(r0,c0)和终点坐标(rf,cf), 求出最短路径并输出. 分析: 因为多了朝向这个元素, 所以我们bfs的队列元素就是一个三元组(r,c,dir ...
- 【Intellij】Intellij Idea 2017创建web项目及tomcat部署实战
相关软件:Intellij Idea2017.jdk16.tomcat7 Intellij Idea直接安装(可根据需要选择自己设置的安装目录),jdk使用1.6/1.7/1.8都可以,主要是配置好系 ...
- 【http_load】http_load性能测试工具使用详解
1.什么是http_loadhttp_load是一款基于Linux平台的web服务器性能测试工具,用于测试web服务器的吞吐量与负载,web页面的性能. 2.http_load的安装1)下载地址wge ...
- hosts.allow和hosts.deny文件
之前想通过外部主机访问自己主机上的VMWare虚拟机,使用了VMWare的NAT端口映射,经过一番尝试,算是成功了,总结一下. VMWare NAT端口映射就可以将虚拟机上的服务映射成自己主机上的端口 ...
- hdu - 1072 Nightmare(bfs)
http://acm.hdu.edu.cn/showproblem.php?pid=1072 遇到Bomb-Reset-Equipment的时候除了时间恢复之外,必须把这个点做标记不能再走,不然可能造 ...
- B - Euler theorem 数学
直接打表找规律 HazelFan is given two positive integers a,ba,b, and he wants to calculate amodbamodb. But no ...